 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIA-Edit: Frequency-Interactive Attention for Efficient and High-Fidelity Inversion-Free Text-Guided Image Editing
Nov 15, 2025Text-guided image editing has advanced rapidly with the rise of diffusion models. While flow-based inversion-free methods offer high efficiency by avoiding latent inversion, they often fail to effectively integrate source information, leading to poor background preservation, spatial inconsistencies, and over-editing due to the lack of effective integration of source information. In this paper, we present FIA-Edit, a novel inversion-free framework that achieves high-fidelity and semantically precise edits through a Frequency-Interactive Attention. Specifically, we design two key components: (1) a Frequency Representation Interaction (FRI) module that enhances cross-domain alignment by exchanging frequency components between source and target features within self-attention, and (2) a Feature Injection (FIJ) module that explicitly incorporates source-side queries, keys, values, and text embeddings into the target branch's cross-attention to preserve structure and semantics. Comprehensive and extensive experiments demonstrate that FIA-Edit supports high-fidelity editing at low computational cost (~6s per 512 * 512 image on an RTX 4090) and consistently outperforms existing methods across diverse tasks in visual quality, background fidelity, and controllability. Furthermore, we are the first to extend text-guided image editing to clinical applications. By synthesizing anatomically coherent hemorrhage variations in surgical images, FIA-Edit opens new opportunities for medical data augmentation and delivers significant gains in downstream bleeding classification. Our project is available at: https://github.com/kk42yy/FIA-Edit.
Prime-Aware Adaptive Distillation
Aug 04, 2020
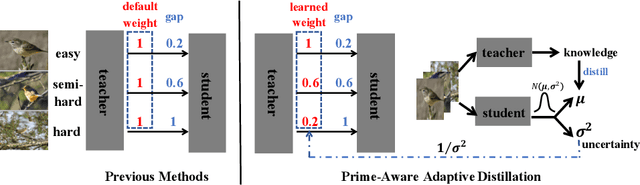
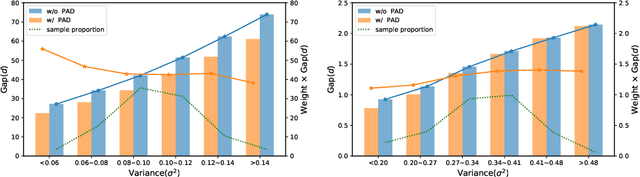

Knowledge distillation(KD) aims to improve the performance of a student network by mimicing the knowledge from a powerful teacher network. Existing methods focus on studying what knowledge should be transferred and treat all samples equally during training. This paper introduces the adaptive sample weighting to KD. We discover that previous effective hard mining methods are not appropriate for distillation. Furthermore, we propose Prime-Aware Adaptive Distillation (PAD) by the incorporation of uncertainty learning. PAD perceives the prime samples in distillation and then emphasizes their effect adaptively. PAD is fundamentally different from and would refine existing methods with the innovative view of unequal training. For this reason, PAD is versatile and has been applied in various tasks including classification, metric learning, and object detection. With ten teacher-student combinations on six datasets, PAD promotes the performance of existing distillation methods and outperforms recent state-of-the-art methods.
Double Supervised Network with Attention Mechanism for Scene Text Recognition
Aug 02, 2018
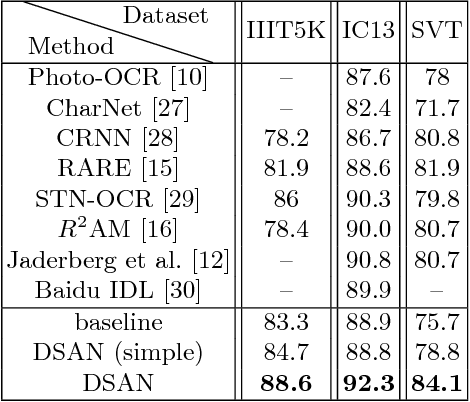
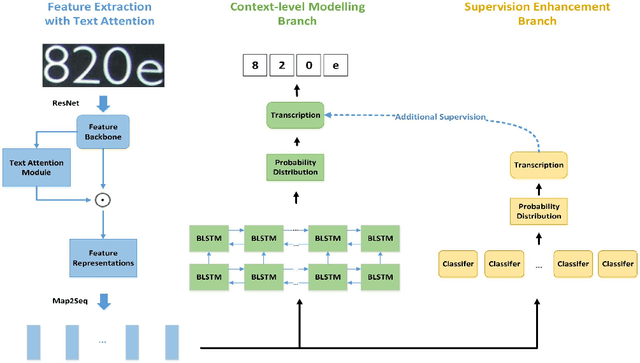
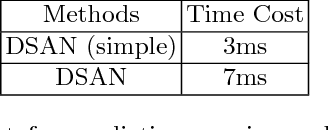
In this paper, we propose Double Supervised Network with Attention Mechanism (DSAN), a novel end-to-end trainable framework for scene text recognition. It incorporates one text attention module during feature extraction which enforces the model to focus on text regions and the whole framework is supervised by two branches. One supervision branch comes from context-level modelling and another comes from one extra supervision enhancement branch which aims at tackling inexplicit semantic information at character level. These two supervisions can benefit each other and yield better performance. The proposed approach can recognize text in arbitrary length and does not need any predefined lexicon. Our method outperforms the current state-of-the-art methods on three text recognition benchmarks: IIIT5K, ICDAR2013 and SVT reaching accuracy 88.6%, 92.3% and 84.1% respectively which suggests the effectiveness of the proposed method.
Fused Text Segmentation Networks for Multi-oriented Scene Text Detection
May 07, 2018
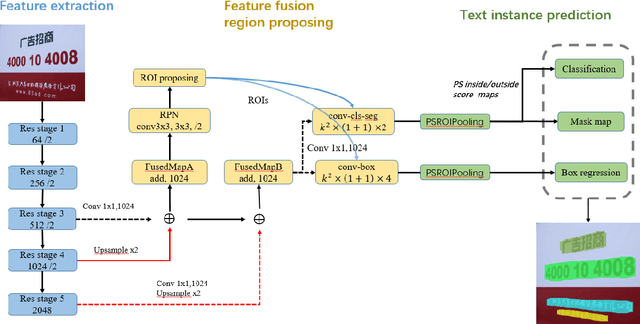

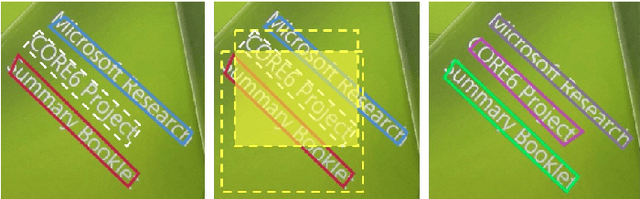
In this paper, we introduce a novel end-end framework for multi-oriented scene text detection from an instance-aware semantic segmentation perspective. We present Fused Text Segmentation Networks, which combine multi-level features during the feature extracting as text instance may rely on finer feature expression compared to general objects. It detects and segments the text instance jointly and simultaneously, leveraging merits from both semantic segmentation task and region proposal based object detection task. Not involving any extra pipelines, our approach surpasses the current state of the art on multi-oriented scene text detection benchmarks: ICDAR2015 Incidental Scene Text and MSRA-TD500 reaching Hmean 84.1% and 82.0% respectively. Morever, we report a baseline on total-text containing curved text which suggests effectiveness of the proposed approach.