 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble Supervised Network with Attention Mechanism for Scene Text Recognition
Paper and Code
Aug 02, 2018
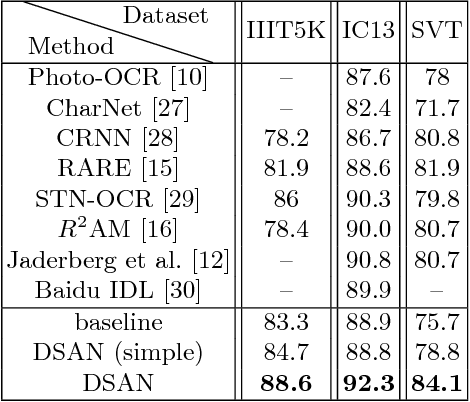
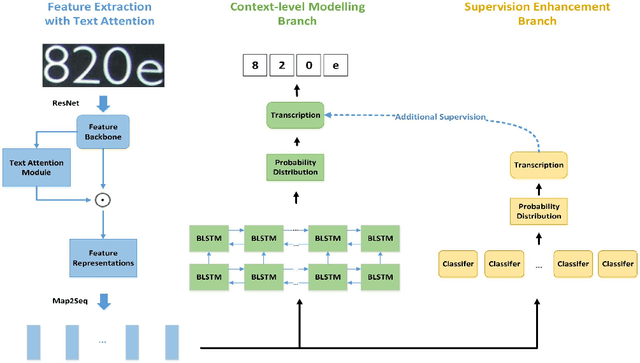
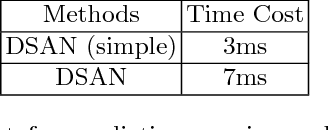
In this paper, we propose Double Supervised Network with Attention Mechanism (DSAN), a novel end-to-end trainable framework for scene text recognition. It incorporates one text attention module during feature extraction which enforces the model to focus on text regions and the whole framework is supervised by two branches. One supervision branch comes from context-level modelling and another comes from one extra supervision enhancement branch which aims at tackling inexplicit semantic information at character level. These two supervisions can benefit each other and yield better performance. The proposed approach can recognize text in arbitrary length and does not need any predefined lexicon. Our method outperforms the current state-of-the-art methods on three text recognition benchmarks: IIIT5K, ICDAR2013 and SVT reaching accuracy 88.6%, 92.3% and 84.1% respectively which suggests the effectiveness of the proposed method.