 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFused Text Segmentation Networks for Multi-oriented Scene Text Detection
Paper and Code
May 07, 2018
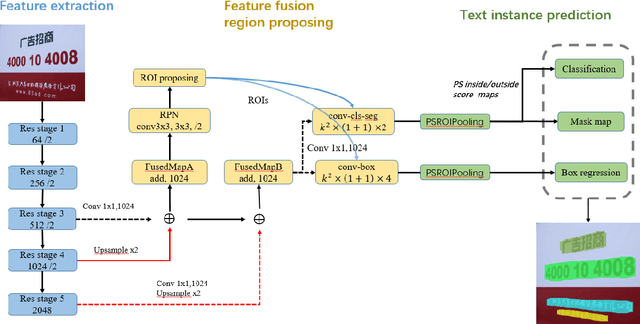

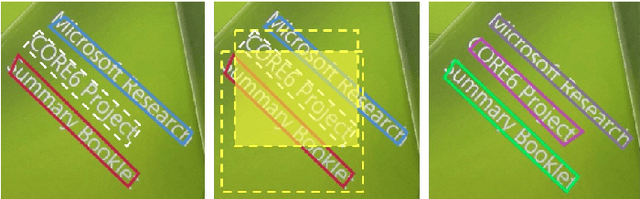
In this paper, we introduce a novel end-end framework for multi-oriented scene text detection from an instance-aware semantic segmentation perspective. We present Fused Text Segmentation Networks, which combine multi-level features during the feature extracting as text instance may rely on finer feature expression compared to general objects. It detects and segments the text instance jointly and simultaneously, leveraging merits from both semantic segmentation task and region proposal based object detection task. Not involving any extra pipelines, our approach surpasses the current state of the art on multi-oriented scene text detection benchmarks: ICDAR2015 Incidental Scene Text and MSRA-TD500 reaching Hmean 84.1% and 82.0% respectively. Morever, we report a baseline on total-text containing curved text which suggests effectiveness of the proposed approach.