 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
Oct 30, 2025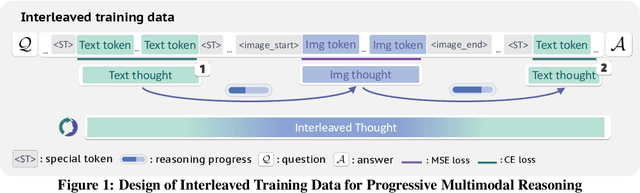
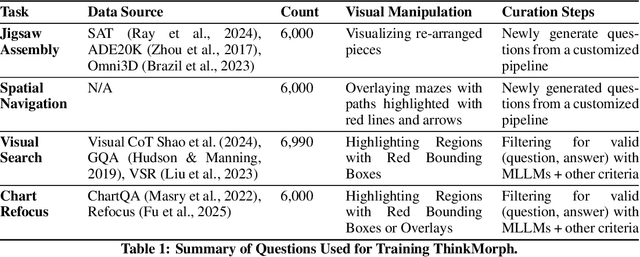


Multimodal reasoning requires iterative coordination between language and vision, yet it remains unclear what constitutes a meaningful interleaved chain of thought. We posit that text and image thoughts should function as complementary, rather than isomorphic, modalities that mutually advance reasoning. Guided by this principle, we build ThinkMorph, a unified model fine-tuned on 24K high-quality interleaved reasoning traces spanning tasks with varying visual engagement. ThinkMorph learns to generate progressive text-image reasoning steps that concretely manipulate visual content while maintaining coherent verbal logic. It delivers large gains on vision-centric benchmarks (averaging 34.7% over the base model) and generalizes to out-of-domain tasks, matching or surpassing larger and proprietary VLMs. Beyond performance, ThinkMorph exhibits emergent multimodal intelligence, including unseen visual manipulation skills, adaptive switching between reasoning modes, and better test-time scaling through diversified multimodal thoughts.These findings suggest promising directions for characterizing the emergent capabilities of unified models for multimodal reasoning.
Skywork-R1V3 Technical Report
Jul 09, 2025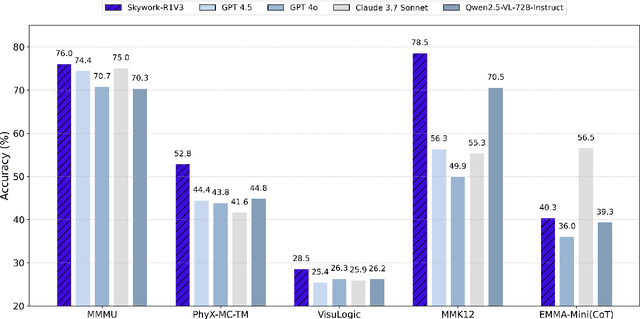
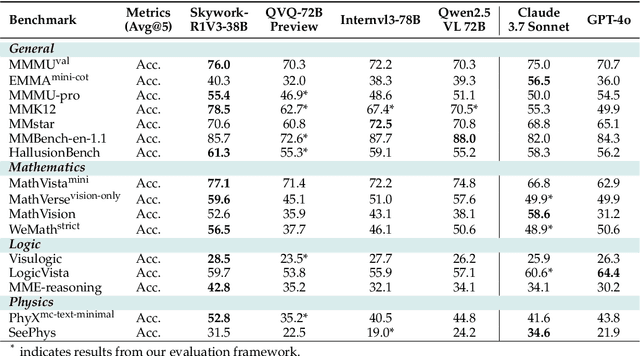
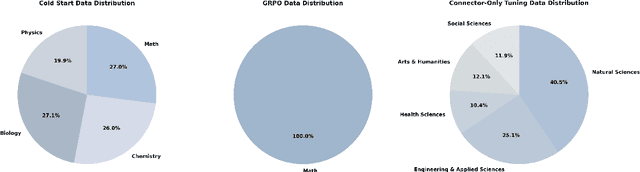

We introduce Skywork-R1V3, an advanced, open-source vision-language model (VLM) that pioneers a new approach to visual reasoning. Its key innovation lies in effectively transferring reasoning skills from text-only Large Language Models (LLMs) to visual tasks. The strong performance of Skywork-R1V3 primarily stems from our elaborate post-training RL framework, which effectively activates and enhances the model's reasoning ability, without the need for additional continue pre-training. Through this framework, we further uncover the fundamental role of the connector module in achieving robust cross-modal alignment for multimodal reasoning models. In addition, we introduce a unique indicator of reasoning capability, the entropy of critical reasoning tokens, which has proven highly effective for checkpoint selection during RL training. Skywork-R1V3 achieves state-of-the-art results on MMMU, significantly improving from 64.3% to 76.0%. This performance matches entry-level human capabilities. Remarkably, our RL-powered post-training approach enables even the 38B parameter model to rival top closed-source VLMs. The implementation successfully transfers mathematical reasoning to other subject-related reasoning tasks. We also include an analysis of curriculum learning and reinforcement finetuning strategies, along with a broader discussion on multimodal reasoning. Skywork-R1V3 represents a significant leap in multimodal reasoning, showcasing RL as a powerful engine for advancing open-source VLM capabilities.
CSVQA: A Chinese Multimodal Benchmark for Evaluating STEM Reasoning Capabilities of VLMs
May 30, 2025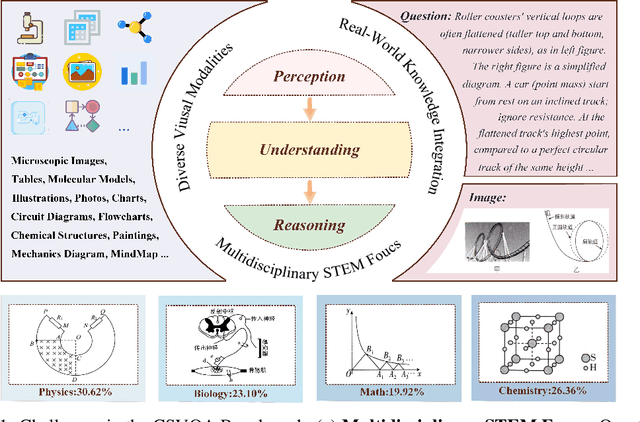
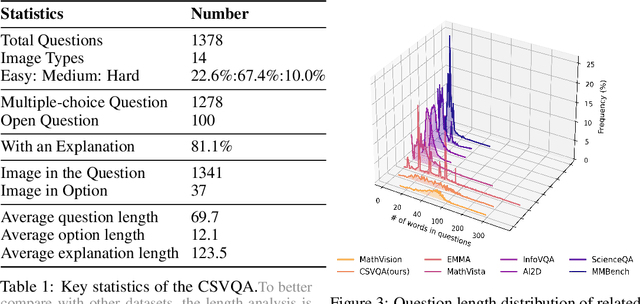
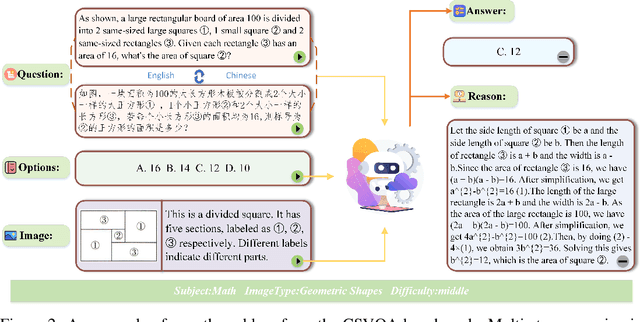
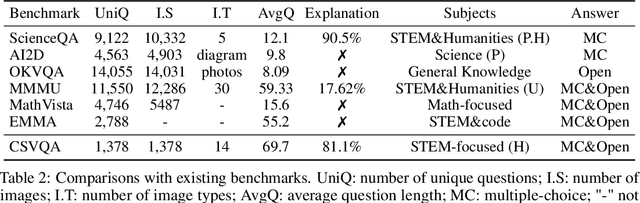
Vision-Language Models (VLMs) have demonstrated remarkable progress in multimodal understanding, yet their capabilities for scientific reasoning remains inadequately assessed. Current multimodal benchmarks predominantly evaluate generic image comprehension or text-driven reasoning, lacking authentic scientific contexts that require domain-specific knowledge integration with visual evidence analysis. To fill this gap, we present CSVQA, a diagnostic multimodal benchmark specifically designed for evaluating scientific reasoning through domain-grounded visual question answering.Our benchmark features 1,378 carefully constructed question-answer pairs spanning diverse STEM disciplines, each demanding domain knowledge, integration of visual evidence, and higher-order reasoning. Compared to prior multimodal benchmarks, CSVQA places greater emphasis on real-world scientific content and complex reasoning.We additionally propose a rigorous evaluation protocol to systematically assess whether model predictions are substantiated by valid intermediate reasoning steps based on curated explanations. Our comprehensive evaluation of 15 VLMs on this benchmark reveals notable performance disparities, as even the top-ranked proprietary model attains only 49.6\% accuracy.This empirical evidence underscores the pressing need for advancing scientific reasoning capabilities in VLMs. Our CSVQA is released at https://huggingface.co/datasets/Skywork/CSVQA.
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
May 13, 2025



While humans can flexibly leverage interactive visual cognition for complex problem-solving, enabling Large Vision-Language Models (LVLMs) to learn similarly adaptive behaviors with visual tools remains challenging. A significant hurdle is the current lack of standardized infrastructure, which hinders integrating diverse tools, generating rich interaction data, and training robust agents effectively. To address these gaps, we introduce OpenThinkIMG, the first open-source, comprehensive end-to-end framework for tool-augmented LVLMs. It features standardized vision tool interfaces, scalable trajectory generation for policy initialization, and a flexible training environment. Furthermore, considering supervised fine-tuning (SFT) on static demonstrations offers limited policy generalization for dynamic tool invocation, we propose a novel reinforcement learning (RL) framework V-ToolRL to train LVLMs to learn adaptive policies for invoking external vision tools. V-ToolRL enables LVLMs to autonomously discover optimal tool-usage strategies by directly optimizing for task success using feedback from tool interactions. We empirically validate V-ToolRL on challenging chart reasoning tasks. Our RL-trained agent, built upon a Qwen2-VL-2B, significantly outperforms its SFT-initialized counterpart (+28.83 points) and surpasses established supervised tool-learning baselines like Taco and CogCom by an average of +12.7 points. Notably, it also surpasses prominent closed-source models like GPT-4.1 by +8.68 accuracy points. We hope OpenThinkIMG can serve as a foundational framework for advancing dynamic, tool-augmented visual reasoning, helping the community develop AI agents that can genuinely "think with images".
Skywork-VL Reward: An Effective Reward Model for Multimodal Understanding and Reasoning
May 12, 2025We propose Skywork-VL Reward, a multimodal reward model that provides reward signals for both multimodal understanding and reasoning tasks. Our technical approach comprises two key components: First, we construct a large-scale multimodal preference dataset that covers a wide range of tasks and scenarios, with responses collected from both standard vision-language models (VLMs) and advanced VLM reasoners. Second, we design a reward model architecture based on Qwen2.5-VL-7B-Instruct, integrating a reward head and applying multi-stage fine-tuning using pairwise ranking loss on pairwise preference data. Experimental evaluations show that Skywork-VL Reward achieves state-of-the-art results on multimodal VL-RewardBench and exhibits competitive performance on the text-only RewardBench benchmark. Furthermore, preference data constructed based on our Skywork-VL Reward proves highly effective for training Mixed Preference Optimization (MPO), leading to significant improvements in multimodal reasoning capabilities. Our results underscore Skywork-VL Reward as a significant advancement toward general-purpose, reliable reward models for multimodal alignment. Our model has been publicly released to promote transparency and reproducibility.
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Apr 23, 2025We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively counters the ``Vanishing Advantages'' dilemma inherent in Group Relative Policy Optimization (GRPO) by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations--a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.
Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought
Apr 08, 2025We introduce Skywork R1V, a multimodal reasoning model extending the an R1-series Large language models (LLM) to visual modalities via an efficient multimodal transfer method. Leveraging a lightweight visual projector, Skywork R1V facilitates seamless multimodal adaptation without necessitating retraining of either the foundational language model or the vision encoder. To strengthen visual-text alignment, we propose a hybrid optimization strategy that combines Iterative Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), significantly enhancing cross-modal integration efficiency. Additionally, we introduce an adaptive-length Chain-of-Thought distillation approach for reasoning data generation. This approach dynamically optimizes reasoning chain lengths, thereby enhancing inference efficiency and preventing excessive reasoning overthinking. Empirical evaluations demonstrate that Skywork R1V, with only 38B parameters, delivers competitive performance, achieving a score of 69.0 on the MMMU benchmark and 67.5 on MathVista. Meanwhile, it maintains robust textual reasoning performance, evidenced by impressive scores of 72.0 on AIME and 94.0 on MATH500. The Skywork R1V model weights have been publicly released to promote openness and reproducibility.
Can MLLMs Reason in Multimodality? EMMA: An Enhanced MultiModal ReAsoning Benchmark
Jan 09, 2025



The ability to organically reason over and with both text and images is a pillar of human intelligence, yet the ability of Multimodal Large Language Models (MLLMs) to perform such multimodal reasoning remains under-explored. Existing benchmarks often emphasize text-dominant reasoning or rely on shallow visual cues, failing to adequately assess integrated visual and textual reasoning. We introduce EMMA (Enhanced MultiModal reAsoning), a benchmark targeting organic multimodal reasoning across mathematics, physics, chemistry, and coding. EMMA tasks demand advanced cross-modal reasoning that cannot be addressed by reasoning independently in each modality, offering an enhanced test suite for MLLMs' reasoning capabilities. Our evaluation of state-of-the-art MLLMs on EMMA reveals significant limitations in handling complex multimodal and multi-step reasoning tasks, even with advanced techniques like Chain-of-Thought prompting and test-time compute scaling underperforming. These findings underscore the need for improved multimodal architectures and training paradigms to close the gap between human and model reasoning in multimodality.
Exploring Backdoor Vulnerabilities of Chat Models
Apr 03, 2024



Recent researches have shown that Large Language Models (LLMs) are susceptible to a security threat known as Backdoor Attack. The backdoored model will behave well in normal cases but exhibit malicious behaviours on inputs inserted with a specific backdoor trigger. Current backdoor studies on LLMs predominantly focus on instruction-tuned LLMs, while neglecting another realistic scenario where LLMs are fine-tuned on multi-turn conversational data to be chat models. Chat models are extensively adopted across various real-world scenarios, thus the security of chat models deserves increasing attention. Unfortunately, we point out that the flexible multi-turn interaction format instead increases the flexibility of trigger designs and amplifies the vulnerability of chat models to backdoor attacks. In this work, we reveal and achieve a novel backdoor attacking method on chat models by distributing multiple trigger scenarios across user inputs in different rounds, and making the backdoor be triggered only when all trigger scenarios have appeared in the historical conversations. Experimental results demonstrate that our method can achieve high attack success rates (e.g., over 90% ASR on Vicuna-7B) while successfully maintaining the normal capabilities of chat models on providing helpful responses to benign user requests. Also, the backdoor can not be easily removed by the downstream re-alignment, highlighting the importance of continued research and attention to the security concerns of chat models. Warning: This paper may contain toxic content.