 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSVQA: A Chinese Multimodal Benchmark for Evaluating STEM Reasoning Capabilities of VLMs
May 30, 2025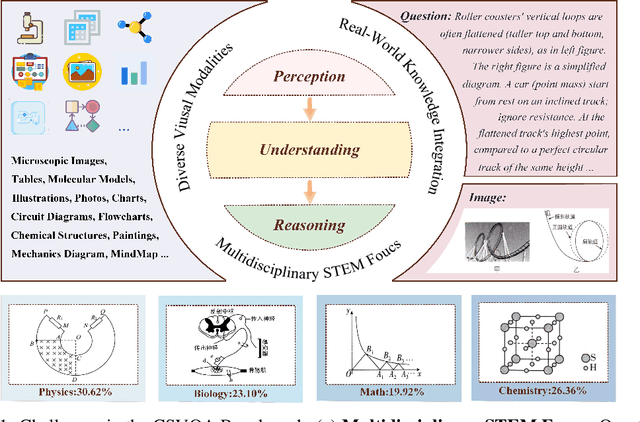
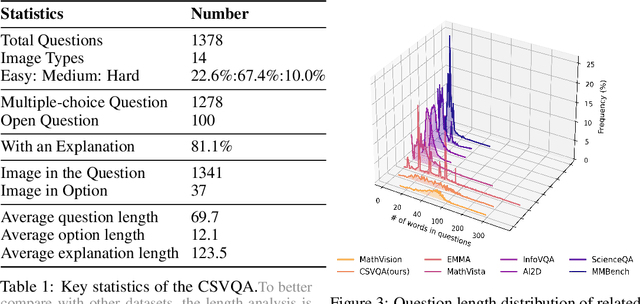
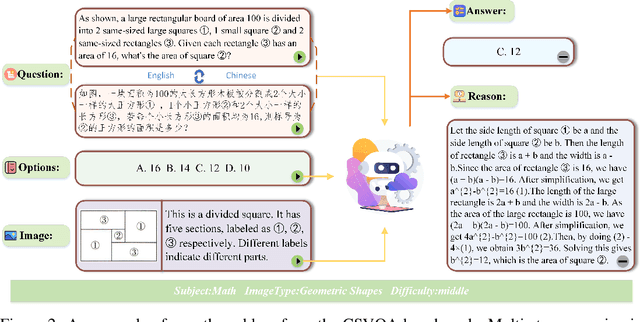
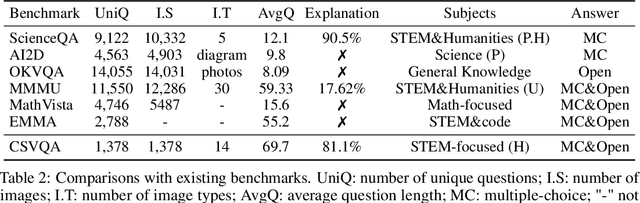
Vision-Language Models (VLMs) have demonstrated remarkable progress in multimodal understanding, yet their capabilities for scientific reasoning remains inadequately assessed. Current multimodal benchmarks predominantly evaluate generic image comprehension or text-driven reasoning, lacking authentic scientific contexts that require domain-specific knowledge integration with visual evidence analysis. To fill this gap, we present CSVQA, a diagnostic multimodal benchmark specifically designed for evaluating scientific reasoning through domain-grounded visual question answering.Our benchmark features 1,378 carefully constructed question-answer pairs spanning diverse STEM disciplines, each demanding domain knowledge, integration of visual evidence, and higher-order reasoning. Compared to prior multimodal benchmarks, CSVQA places greater emphasis on real-world scientific content and complex reasoning.We additionally propose a rigorous evaluation protocol to systematically assess whether model predictions are substantiated by valid intermediate reasoning steps based on curated explanations. Our comprehensive evaluation of 15 VLMs on this benchmark reveals notable performance disparities, as even the top-ranked proprietary model attains only 49.6\% accuracy.This empirical evidence underscores the pressing need for advancing scientific reasoning capabilities in VLMs. Our CSVQA is released at https://huggingface.co/datasets/Skywork/CSVQA.
Skywork-VL Reward: An Effective Reward Model for Multimodal Understanding and Reasoning
May 12, 2025We propose Skywork-VL Reward, a multimodal reward model that provides reward signals for both multimodal understanding and reasoning tasks. Our technical approach comprises two key components: First, we construct a large-scale multimodal preference dataset that covers a wide range of tasks and scenarios, with responses collected from both standard vision-language models (VLMs) and advanced VLM reasoners. Second, we design a reward model architecture based on Qwen2.5-VL-7B-Instruct, integrating a reward head and applying multi-stage fine-tuning using pairwise ranking loss on pairwise preference data. Experimental evaluations show that Skywork-VL Reward achieves state-of-the-art results on multimodal VL-RewardBench and exhibits competitive performance on the text-only RewardBench benchmark. Furthermore, preference data constructed based on our Skywork-VL Reward proves highly effective for training Mixed Preference Optimization (MPO), leading to significant improvements in multimodal reasoning capabilities. Our results underscore Skywork-VL Reward as a significant advancement toward general-purpose, reliable reward models for multimodal alignment. Our model has been publicly released to promote transparency and reproducibility.
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Apr 23, 2025We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively counters the ``Vanishing Advantages'' dilemma inherent in Group Relative Policy Optimization (GRPO) by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations--a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.
Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought
Apr 08, 2025We introduce Skywork R1V, a multimodal reasoning model extending the an R1-series Large language models (LLM) to visual modalities via an efficient multimodal transfer method. Leveraging a lightweight visual projector, Skywork R1V facilitates seamless multimodal adaptation without necessitating retraining of either the foundational language model or the vision encoder. To strengthen visual-text alignment, we propose a hybrid optimization strategy that combines Iterative Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), significantly enhancing cross-modal integration efficiency. Additionally, we introduce an adaptive-length Chain-of-Thought distillation approach for reasoning data generation. This approach dynamically optimizes reasoning chain lengths, thereby enhancing inference efficiency and preventing excessive reasoning overthinking. Empirical evaluations demonstrate that Skywork R1V, with only 38B parameters, delivers competitive performance, achieving a score of 69.0 on the MMMU benchmark and 67.5 on MathVista. Meanwhile, it maintains robust textual reasoning performance, evidenced by impressive scores of 72.0 on AIME and 94.0 on MATH500. The Skywork R1V model weights have been publicly released to promote openness and reproducibility.