 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDETR-ViP: Detection Transformer with Robust Discriminative Visual Prompts
Apr 16, 2026Visual prompted object detection enables interactive and flexible definition of target categories, thereby facilitating open-vocabulary detection. Since visual prompts are derived directly from image features, they often outperform text prompts in recognizing rare categories. Nevertheless, research on visual prompted detection has been largely overlooked, and it is typically treated as a byproduct of training text prompted detectors, which hinders its development. To fully unlock the potential of visual-prompted detection, we investigate the reasons why its performance is suboptimal and reveal that the underlying issue lies in the absence of global discriminability in visual prompts. Motivated by these observations, we propose DETR-ViP, a robust object detection framework that yields class-distinguishable visual prompts. On top of basic image-text contrastive learning, DETR-ViP incorporates global prompt integration and visual-textual prompt relation distillation to learn more discriminative prompt representations. In addition, DETR-ViP employs a selective fusion strategy that ensures stable and robust detection. Extensive experiments on COCO, LVIS, ODinW, and Roboflow100 demonstrate that DETR-ViP achieves substantially higher performance in visual prompt detection compared to other state-of-the-art counterparts. A series of ablation studies and analyses further validate the effectiveness of the proposed improvements and shed light on the underlying reasons for the enhanced detection capability of visual prompts.
Better Matching, Less Forgetting: A Quality-Guided Matcher for Transformer-based Incremental Object Detection
Mar 02, 2026Incremental Object Detection (IOD) aims to continuously learn new object classes without forgetting previously learned ones. A persistent challenge is catastrophic forgetting, primarily attributed to background shift in conventional detectors. While pseudo-labeling mitigates this in dense detectors, we identify a novel, distinct source of forgetting specific to DETR-like architectures: background foregrounding. This arises from the exhaustiveness constraint of the Hungarian matcher, which forcibly assigns every ground truth target to one prediction, even when predictions primarily cover background regions (i.e., low IoU). This erroneous supervision compels the model to misclassify background features as specific foreground classes, disrupting learned representations and accelerating forgetting. To address this, we propose a Quality-guided Min-Cost Max-Flow (Q-MCMF) matcher. To avoid forced assignments, Q-MCMF builds a flow graph and prunes implausible matches based on geometric quality. It then optimizes for the final matching that minimizes cost and maximizes valid assignments. This strategy eliminates harmful supervision from background foregrounding while maximizing foreground learning signals. Extensive experiments on the COCO dataset under various incremental settings demonstrate that our method consistently outperforms existing state-of-the-art approaches.
Scene-Adaptive Attention Network for Crowd Counting
Dec 31, 2021
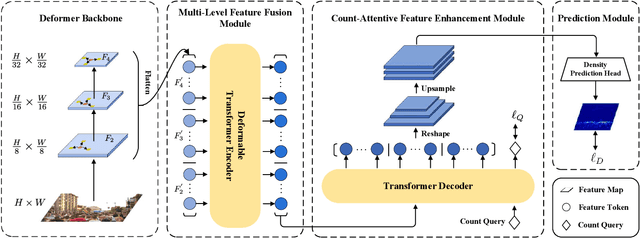
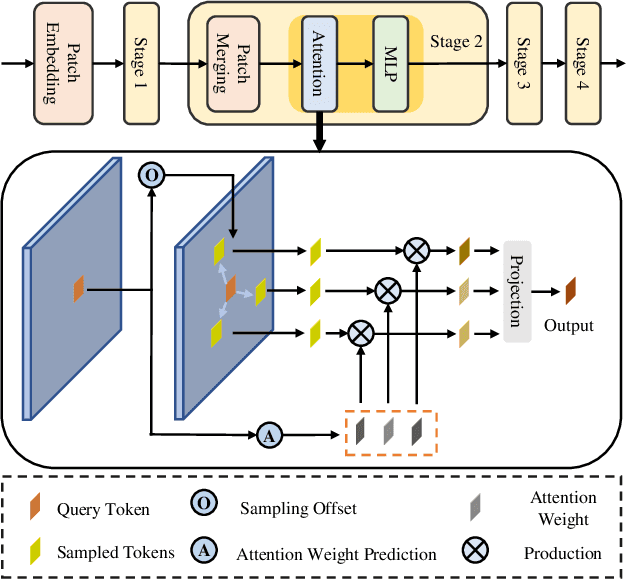
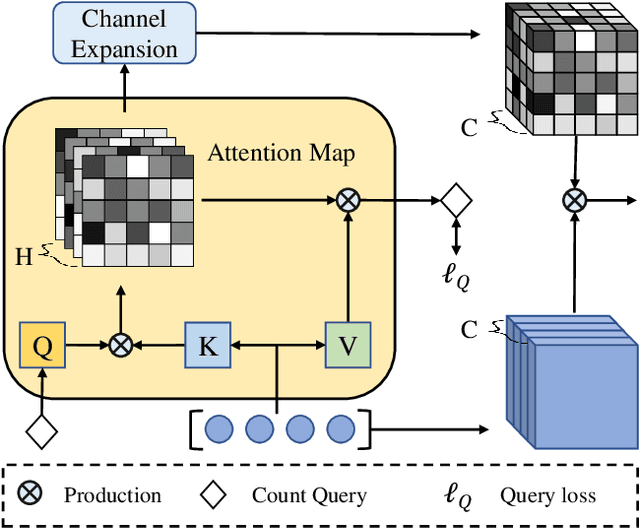
In recent years, significant progress has been made on the research of crowd counting. However, as the challenging scale variations and complex scenes existed in crowds, neither traditional convolution networks nor recent Transformer architectures with fixed-size attention could handle the task well. To address this problem, this paper proposes a scene-adaptive attention network, termed SAANet. First of all, we design a deformable attention in-built Transformer backbone, which learns adaptive feature representations with deformable sampling locations and dynamic attention weights. Then we propose the multi-level feature fusion and count-attentive feature enhancement modules further, to strengthen feature representation under the global image context. The learned representations could attend to the foreground and are adaptive to different scales of crowds. We conduct extensive experiments on four challenging crowd counting benchmarks, demonstrating that our method achieves state-of-the-art performance. Especially, our method currently ranks No.1 on the public leaderboard of the NWPU-Crowd benchmark. We hope our method could be a strong baseline to support future research in crowd counting. The source code will be released to the community.
SOIT: Segmenting Objects with Instance-Aware Transformers
Dec 23, 2021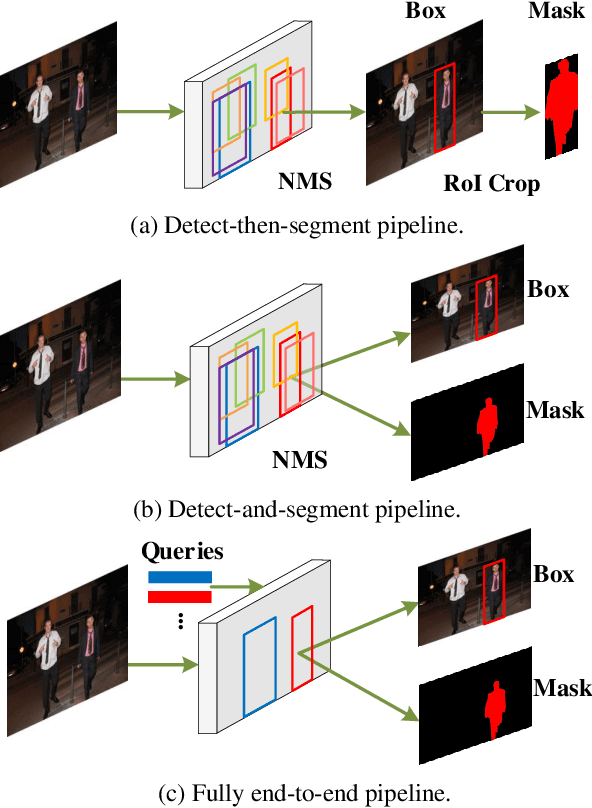
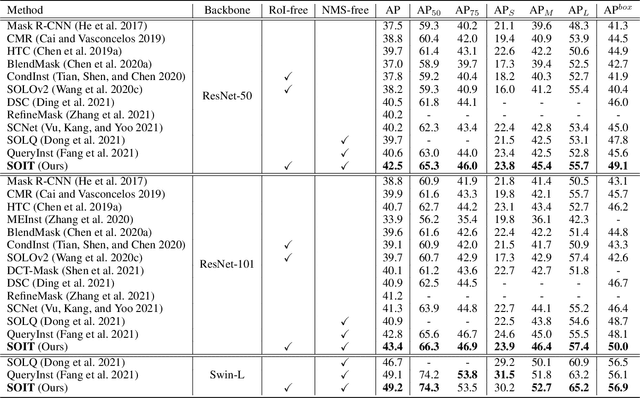
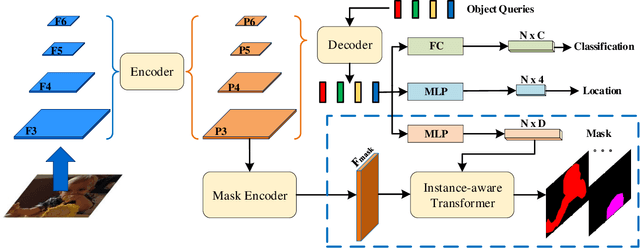
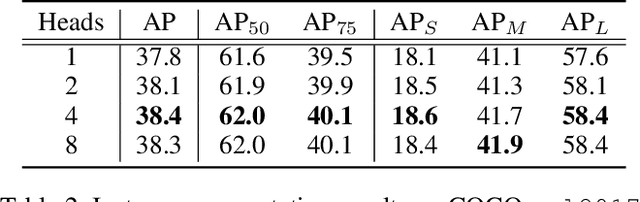
This paper presents an end-to-end instance segmentation framework, termed SOIT, that Segments Objects with Instance-aware Transformers. Inspired by DETR \cite{carion2020end}, our method views instance segmentation as a direct set prediction problem and effectively removes the need for many hand-crafted components like RoI cropping, one-to-many label assignment, and non-maximum suppression (NMS). In SOIT, multiple queries are learned to directly reason a set of object embeddings of semantic category, bounding-box location, and pixel-wise mask in parallel under the global image context. The class and bounding-box can be easily embedded by a fixed-length vector. The pixel-wise mask, especially, is embedded by a group of parameters to construct a lightweight instance-aware transformer. Afterward, a full-resolution mask is produced by the instance-aware transformer without involving any RoI-based operation. Overall, SOIT introduces a simple single-stage instance segmentation framework that is both RoI- and NMS-free. Experimental results on the MS COCO dataset demonstrate that SOIT outperforms state-of-the-art instance segmentation approaches significantly. Moreover, the joint learning of multiple tasks in a unified query embedding can also substantially improve the detection performance. Code is available at \url{https://github.com/yuxiaodongHRI/SOIT}.
InsPose: Instance-Aware Networks for Single-Stage Multi-Person Pose Estimation
Jul 20, 2021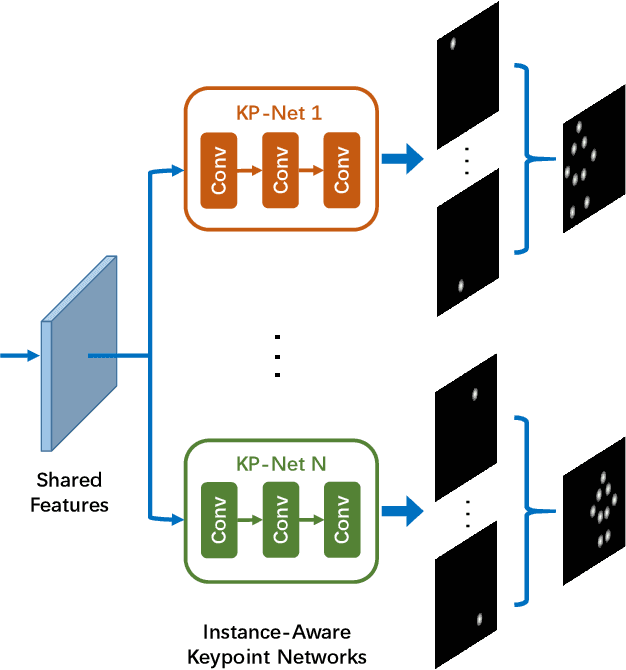


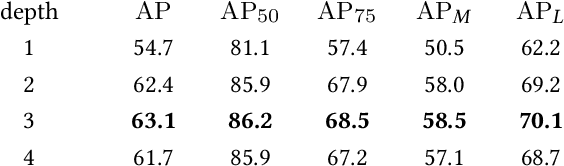
Multi-person pose estimation is an attractive and challenging task. Existing methods are mostly based on two-stage frameworks, which include top-down and bottom-up methods. Two-stage methods either suffer from high computational redundancy for additional person detectors or they need to group keypoints heuristically after predicting all the instance-agnostic keypoints. The single-stage paradigm aims to simplify the multi-person pose estimation pipeline and receives a lot of attention. However, recent single-stage methods have the limitation of low performance due to the difficulty of regressing various full-body poses from a single feature vector. Different from previous solutions that involve complex heuristic designs, we present a simple yet effective solution by employing instance-aware dynamic networks. Specifically, we propose an instance-aware module to adaptively adjust (part of) the network parameters for each instance. Our solution can significantly increase the capacity and adaptive-ability of the network for recognizing various poses, while maintaining a compact end-to-end trainable pipeline. Extensive experiments on the MS-COCO dataset demonstrate that our method achieves significant improvement over existing single-stage methods, and makes a better balance of accuracy and efficiency compared to the state-of-the-art two-stage approaches.
* arXiv admin note: text overlap with arXiv:1911.07451, arXiv:2003.05664, arXiv:2102.03026 by other authors