 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-Adaptive Attention Network for Crowd Counting
Dec 31, 2021
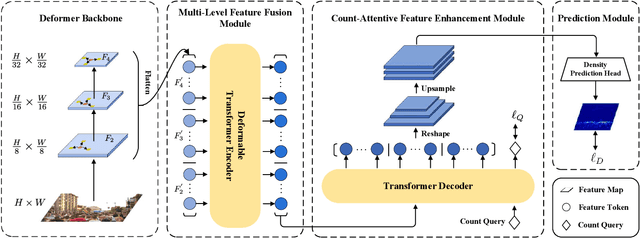
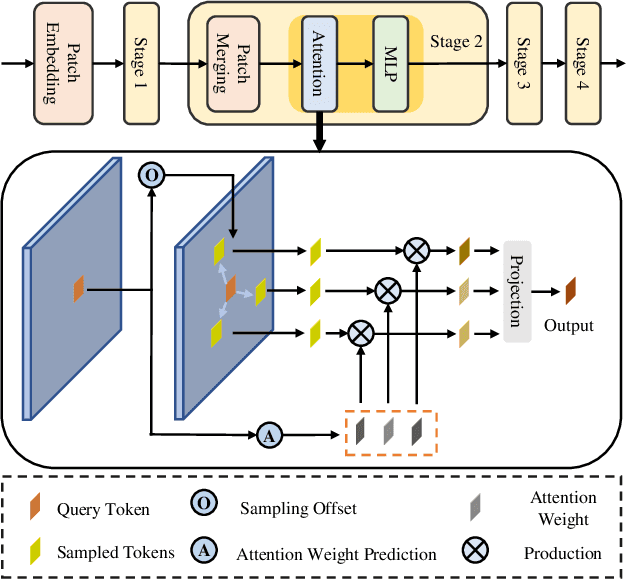
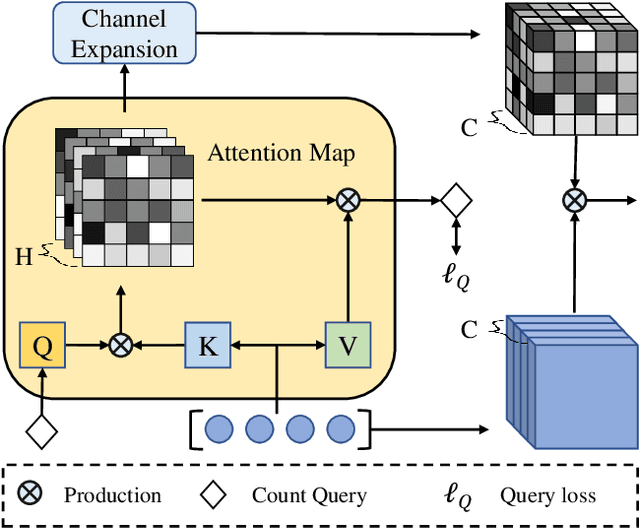
In recent years, significant progress has been made on the research of crowd counting. However, as the challenging scale variations and complex scenes existed in crowds, neither traditional convolution networks nor recent Transformer architectures with fixed-size attention could handle the task well. To address this problem, this paper proposes a scene-adaptive attention network, termed SAANet. First of all, we design a deformable attention in-built Transformer backbone, which learns adaptive feature representations with deformable sampling locations and dynamic attention weights. Then we propose the multi-level feature fusion and count-attentive feature enhancement modules further, to strengthen feature representation under the global image context. The learned representations could attend to the foreground and are adaptive to different scales of crowds. We conduct extensive experiments on four challenging crowd counting benchmarks, demonstrating that our method achieves state-of-the-art performance. Especially, our method currently ranks No.1 on the public leaderboard of the NWPU-Crowd benchmark. We hope our method could be a strong baseline to support future research in crowd counting. The source code will be released to the community.