 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Unifying Fourteen Attribution Methods with Taylor Interactions
Mar 06, 2023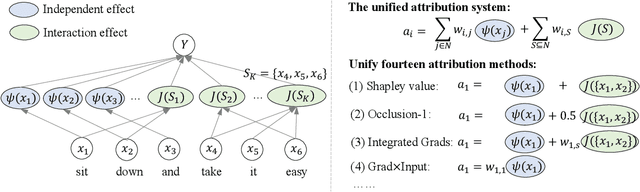
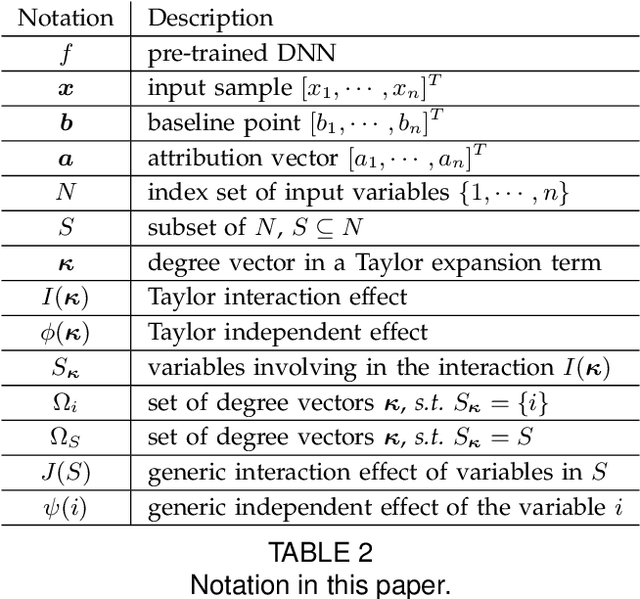

Various attribution methods have been developed to explain deep neural networks (DNNs) by inferring the attribution/importance/contribution score of each input variable to the final output. However, existing attribution methods are often built upon different heuristics. There remains a lack of a unified theoretical understanding of why these methods are effective and how they are related. To this end, for the first time, we formulate core mechanisms of fourteen attribution methods, which were designed on different heuristics, into the same mathematical system, i.e., the system of Taylor interactions. Specifically, we prove that attribution scores estimated by fourteen attribution methods can all be reformulated as the weighted sum of two types of effects, i.e., independent effects of each individual input variable and interaction effects between input variables. The essential difference among the fourteen attribution methods mainly lies in the weights of allocating different effects. Based on the above findings, we propose three principles for a fair allocation of effects to evaluate the faithfulness of the fourteen attribution methods.
A General Taylor Framework for Unifying and Revisiting Attribution Methods
May 28, 2021

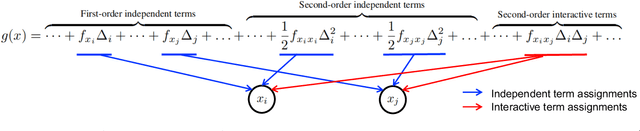
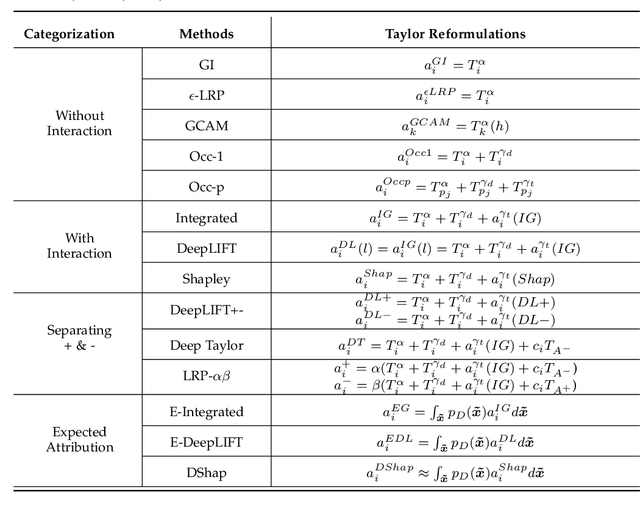
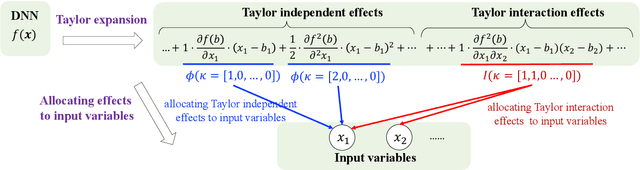
Attribution methods provide an insight into the decision-making process of machine learning models, especially deep neural networks, by assigning contribution scores to each individual feature. However, the attribution problem has not been well-defined, which lacks a unified guideline to the contribution assignment process. Furthermore, existing attribution methods often built upon various empirical intuitions and heuristics. There still lacks a general theoretical framework that not only can offer a good description of the attribution problem, but also can be applied to unifying and revisiting existing attribution methods. To bridge the gap, in this paper, we propose a Taylor attribution framework, which models the attribution problem as how to decide individual payoffs in a coalition. Then, we reformulate fourteen mainstream attribution methods into the Taylor framework and analyze these attribution methods in terms of rationale, fidelity, and limitation in the framework. Moreover, we establish three principles for a good attribution in the Taylor attribution framework, i.e., low approximation error, correct Taylor contribution assignment, and unbiased baseline selection. Finally, we empirically validate the Taylor reformulations and reveal a positive correlation between the attribution performance and the number of principles followed by the attribution method via benchmarking on real-world datasets.
Mutual Information Preserving Back-propagation: Learn to Invert for Faithful Attribution
Apr 14, 2021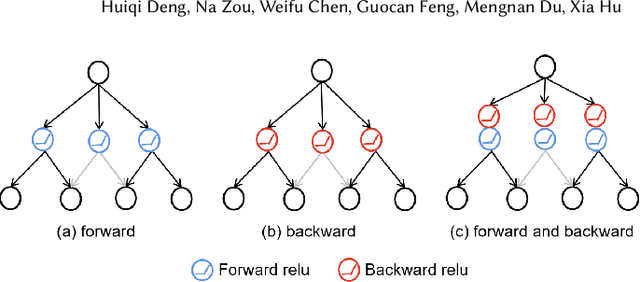
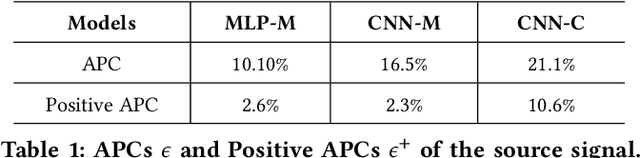
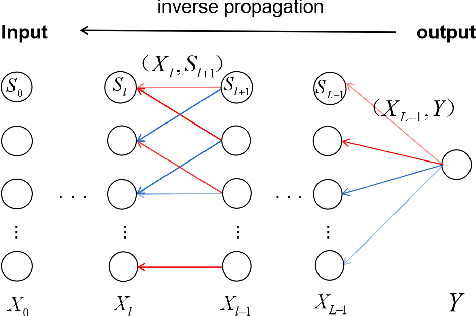
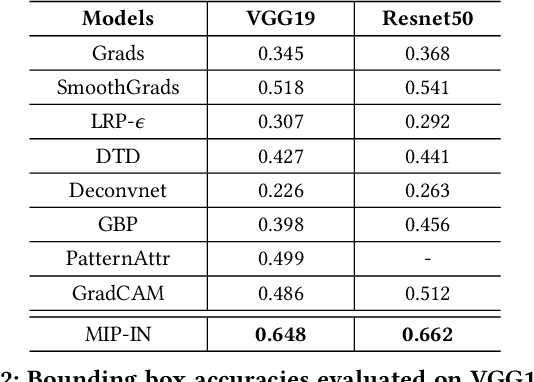
Back propagation based visualizations have been proposed to interpret deep neural networks (DNNs), some of which produce interpretations with good visual quality. However, there exist doubts about whether these intuitive visualizations are related to the network decisions. Recent studies have confirmed this suspicion by verifying that almost all these modified back-propagation visualizations are not faithful to the model's decision-making process. Besides, these visualizations produce vague "relative importance scores", among which low values can't guarantee to be independent of the final prediction. Hence, it's highly desirable to develop a novel back-propagation framework that guarantees theoretical faithfulness and produces a quantitative attribution score with a clear understanding. To achieve the goal, we resort to mutual information theory to generate the interpretations, studying how much information of output is encoded in each input neuron. The basic idea is to learn a source signal by back-propagation such that the mutual information between input and output should be as much as possible preserved in the mutual information between input and the source signal. In addition, we propose a Mutual Information Preserving Inverse Network, termed MIP-IN, in which the parameters of each layer are recursively trained to learn how to invert. During the inversion, forward Relu operation is adopted to adapt the general interpretations to the specific input. We then empirically demonstrate that the inverted source signal satisfies completeness and minimality property, which are crucial for a faithful interpretation. Furthermore, the empirical study validates the effectiveness of interpretations generated by MIP-IN.
A Unified Taylor Framework for Revisiting Attribution Methods
Aug 21, 2020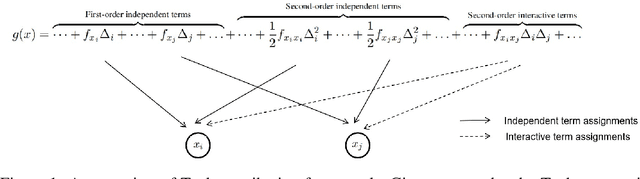



Attribution methods have been developed to understand the decision making process of machine learning models, especially deep neural networks, by assigning importance scores to individual features. Existing attribution methods often built upon empirical intuitions and heuristics. There still lacks a unified framework that can provide deeper understandings of their rationales, theoretical fidelity, and limitations. To bridge the gap, we present a Taylor attribution framework to theoretically characterize the fidelity of explanations. The key idea is to decompose model behaviors into first-order, high-order independent, and high-order interactive terms, which makes clearer attribution of high-order effects and complex feature interactions. Three desired properties are proposed for Taylor attributions, i.e., low model approximation error, accurate assignment of independent and interactive effects. Moreover, several popular attribution methods are mathematically reformulated under the unified Taylor attribution framework. Our theoretical investigations indicate that these attribution methods implicitly reflect high-order terms involving complex feature interdependencies. Among these methods, Integrated Gradient is the only one satisfying the proposed three desired properties. New attribution methods are proposed based on Integrated Gradient by utilizing the Taylor framework. Experimental results show that the proposed method outperforms the existing ones in model interpretations.
Learning zeroth class dictionary for human action recognition
Sep 28, 2016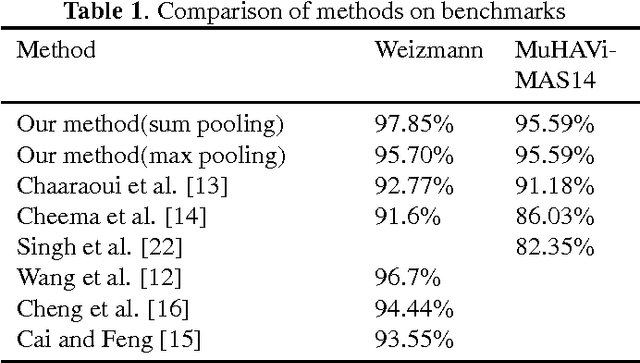
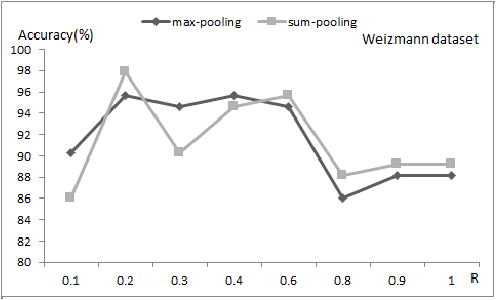
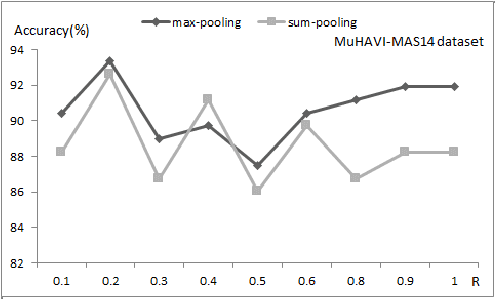
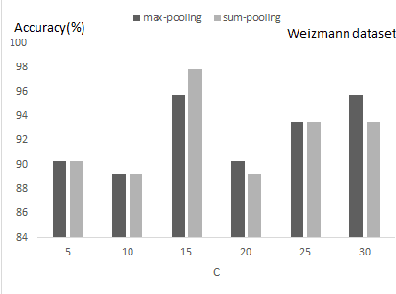
In this paper, a discriminative two-phase dictionary learning framework is proposed for classifying human action by sparse shape representations, in which the first-phase dictionary is learned on the selected discriminative frames and the second-phase dictionary is built for recognition using reconstruction errors of the first-phase dictionary as input features. We propose a "zeroth class" trick for detecting undiscriminating frames of the test video and eliminating them before voting on the action categories. Experimental results on benchmarks demonstrate the effectiveness of our method.