Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning zeroth class dictionary for human action recognition
Paper and Code
Sep 28, 2016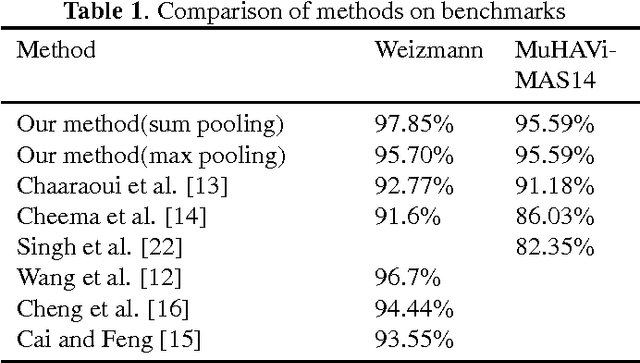
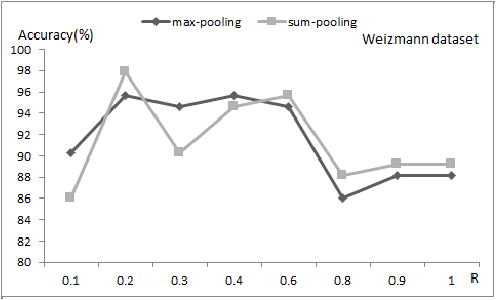
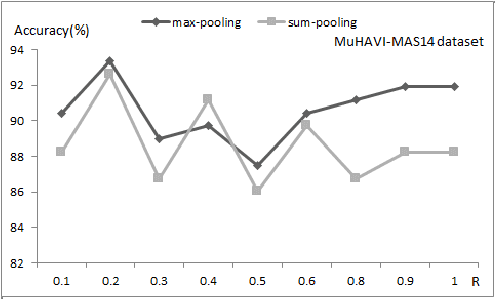
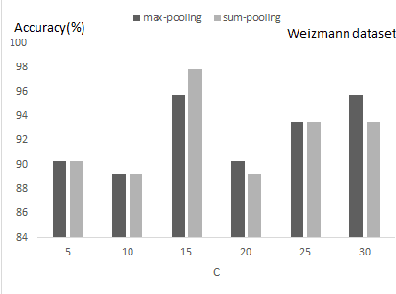
In this paper, a discriminative two-phase dictionary learning framework is proposed for classifying human action by sparse shape representations, in which the first-phase dictionary is learned on the selected discriminative frames and the second-phase dictionary is built for recognition using reconstruction errors of the first-phase dictionary as input features. We propose a "zeroth class" trick for detecting undiscriminating frames of the test video and eliminating them before voting on the action categories. Experimental results on benchmarks demonstrate the effectiveness of our method.
View paper on