 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutual Information Preserving Back-propagation: Learn to Invert for Faithful Attribution
Paper and Code
Apr 14, 2021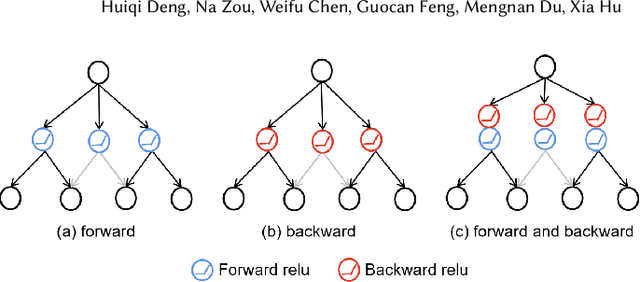
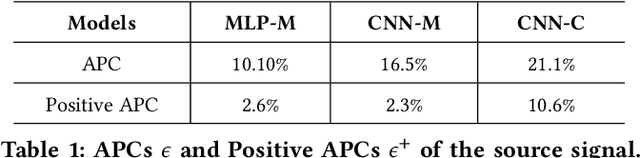
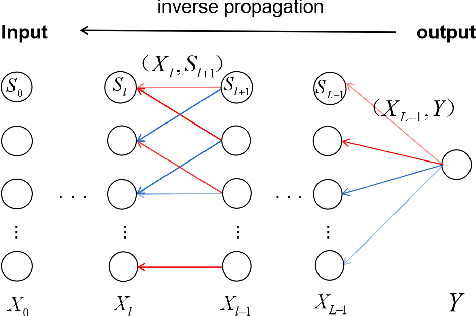
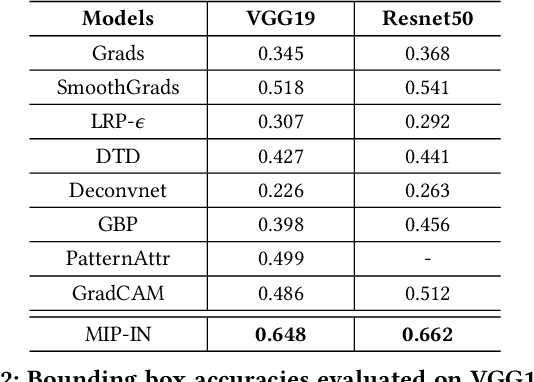
Back propagation based visualizations have been proposed to interpret deep neural networks (DNNs), some of which produce interpretations with good visual quality. However, there exist doubts about whether these intuitive visualizations are related to the network decisions. Recent studies have confirmed this suspicion by verifying that almost all these modified back-propagation visualizations are not faithful to the model's decision-making process. Besides, these visualizations produce vague "relative importance scores", among which low values can't guarantee to be independent of the final prediction. Hence, it's highly desirable to develop a novel back-propagation framework that guarantees theoretical faithfulness and produces a quantitative attribution score with a clear understanding. To achieve the goal, we resort to mutual information theory to generate the interpretations, studying how much information of output is encoded in each input neuron. The basic idea is to learn a source signal by back-propagation such that the mutual information between input and output should be as much as possible preserved in the mutual information between input and the source signal. In addition, we propose a Mutual Information Preserving Inverse Network, termed MIP-IN, in which the parameters of each layer are recursively trained to learn how to invert. During the inversion, forward Relu operation is adopted to adapt the general interpretations to the specific input. We then empirically demonstrate that the inverted source signal satisfies completeness and minimality property, which are crucial for a faithful interpretation. Furthermore, the empirical study validates the effectiveness of interpretations generated by MIP-IN.