 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG+: Enhancing Retrieval-Augmented Generation with Application-Aware Reasoning
Jun 13, 2025The integration of external knowledge through Retrieval-Augmented Generation (RAG) has become foundational in enhancing large language models (LLMs) for knowledge-intensive tasks. However, existing RAG paradigms often overlook the cognitive step of applying knowledge, leaving a gap between retrieved facts and task-specific reasoning. In this work, we introduce RAG+, a principled and modular extension that explicitly incorporates application-aware reasoning into the RAG pipeline. RAG+ constructs a dual corpus consisting of knowledge and aligned application examples, created either manually or automatically, and retrieves both jointly during inference. This design enables LLMs not only to access relevant information but also to apply it within structured, goal-oriented reasoning processes. Experiments across mathematical, legal, and medical domains, conducted on multiple models, demonstrate that RAG+ consistently outperforms standard RAG variants, achieving average improvements of 3-5%, and peak gains up to 7.5% in complex scenarios. By bridging retrieval with actionable application, RAG+ advances a more cognitively grounded framework for knowledge integration, representing a step toward more interpretable and capable LLMs.
Strategic Chain-of-Thought: Guiding Accurate Reasoning in LLMs through Strategy Elicitation
Sep 05, 2024
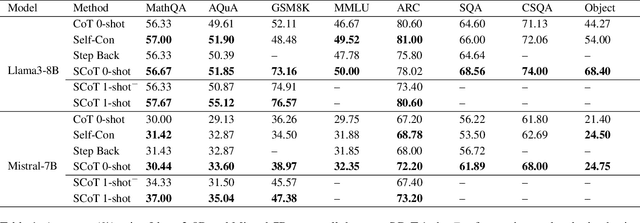
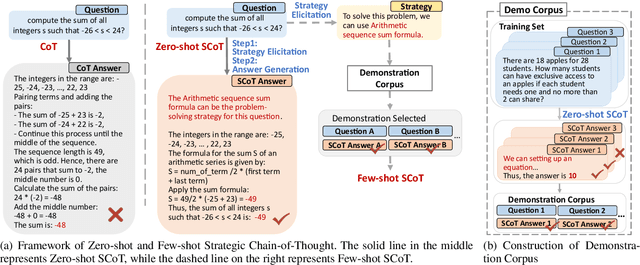
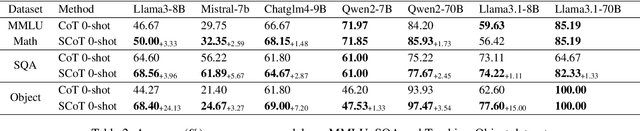
The Chain-of-Thought (CoT) paradigm has emerged as a critical approach for enhancing the reasoning capabilities of large language models (LLMs). However, despite their widespread adoption and success, CoT methods often exhibit instability due to their inability to consistently ensure the quality of generated reasoning paths, leading to sub-optimal reasoning performance. To address this challenge, we propose the \textbf{Strategic Chain-of-Thought} (SCoT), a novel methodology designed to refine LLM performance by integrating strategic knowledge prior to generating intermediate reasoning steps. SCoT employs a two-stage approach within a single prompt: first eliciting an effective problem-solving strategy, which is then used to guide the generation of high-quality CoT paths and final answers. Our experiments across eight challenging reasoning datasets demonstrate significant improvements, including a 21.05\% increase on the GSM8K dataset and 24.13\% on the Tracking\_Objects dataset, respectively, using the Llama3-8b model. Additionally, we extend the SCoT framework to develop a few-shot method with automatically matched demonstrations, yielding even stronger results. These findings underscore the efficacy of SCoT, highlighting its potential to substantially enhance LLM performance in complex reasoning tasks.
Re-TASK: Revisiting LLM Tasks from Capability, Skill, and Knowledge Perspectives
Aug 13, 2024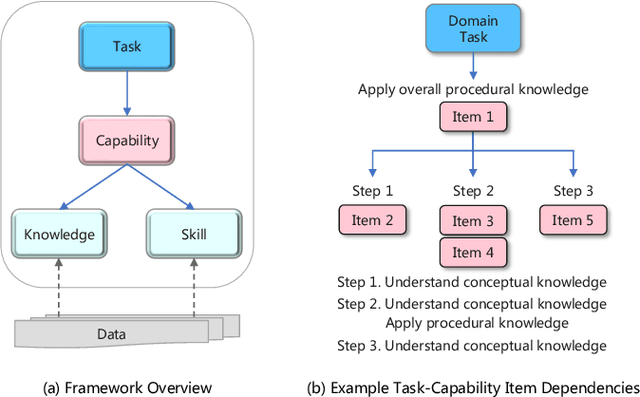
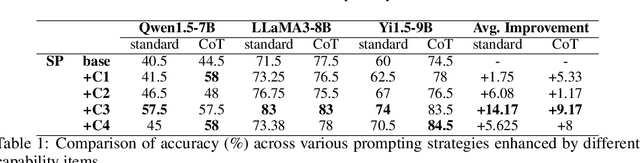

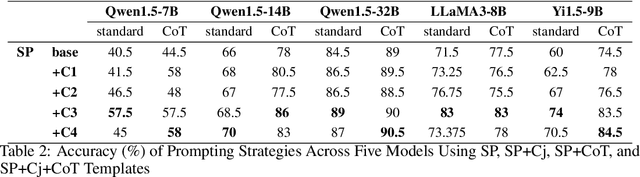
As large language models (LLMs) continue to scale, their enhanced performance often proves insufficient for solving domain-specific tasks. Systematically analyzing their failures and effectively enhancing their performance remain significant challenges. This paper introduces the Re-TASK framework, a novel theoretical model that Revisits LLM Tasks from cApability, Skill, Knowledge perspectives, guided by the principles of Bloom's Taxonomy and Knowledge Space Theory. The Re-TASK framework provides a systematic methodology to deepen our understanding, evaluation, and enhancement of LLMs for domain-specific tasks. It explores the interplay among an LLM's capabilities, the knowledge it processes, and the skills it applies, elucidating how these elements are interconnected and impact task performance. Our application of the Re-TASK framework reveals that many failures in domain-specific tasks can be attributed to insufficient knowledge or inadequate skill adaptation. With this insight, we propose structured strategies for enhancing LLMs through targeted knowledge injection and skill adaptation. Specifically, we identify key capability items associated with tasks and employ a deliberately designed prompting strategy to enhance task performance, thereby reducing the need for extensive fine-tuning. Alternatively, we fine-tune the LLM using capability-specific instructions, further validating the efficacy of our framework. Experimental results confirm the framework's effectiveness, demonstrating substantial improvements in both the performance and applicability of LLMs.