 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurricular and Cyclical Loss for Time Series Learning Strategy
Dec 26, 2023Time series widely exists in real-world applications and many deep learning models have performed well on it. Current research has shown the importance of learning strategy for models, suggesting that the benefit is the order and size of learning samples. However, no effective strategy has been proposed for time series due to its abstract and dynamic construction. Meanwhile, the existing one-shot tasks and continuous tasks for time series necessitate distinct learning processes and mechanisms. No all-purpose approach has been suggested. In this work, we propose a novel Curricular and CyclicaL loss (CRUCIAL) to learn time series for the first time. It is model- and task-agnostic and can be plugged on top of the original loss with no extra procedure. CRUCIAL has two characteristics: It can arrange an easy-to-hard learning order by dynamically determining the sample contribution and modulating the loss amplitude; It can manage a cyclically changed dataset and achieve an adaptive cycle by correlating the loss distribution and the selection probability. We prove that compared with monotonous size, cyclical size can reduce expected error. Experiments on 3 kinds of tasks and 5 real-world datasets show the benefits of CRUCIAL for most deep learning models when learning time series.
Continuous Diagnosis and Prognosis by Controlling the Update Process of Deep Neural Networks
Oct 06, 2022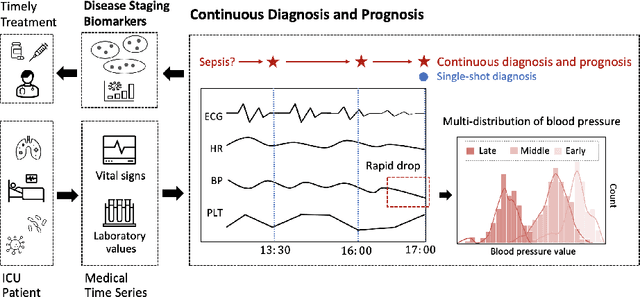
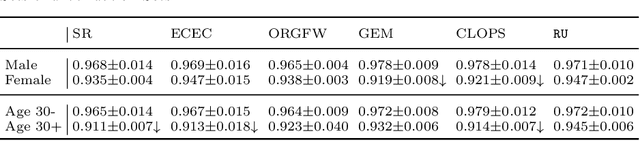
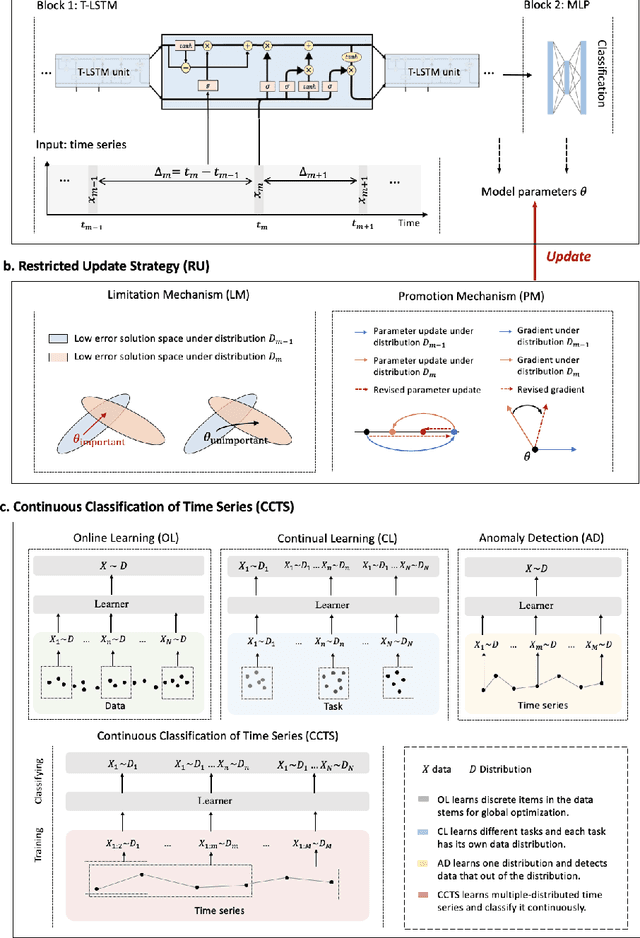
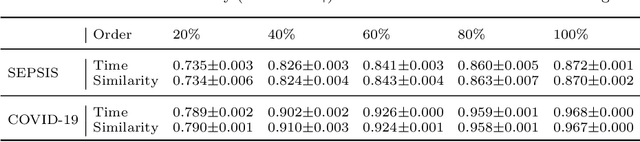
Continuous diagnosis and prognosis are essential for intensive care patients. It can provide more opportunities for timely treatment and rational resource allocation, especially for sepsis, a main cause of death in ICU, and COVID-19, a new worldwide epidemic. Although deep learning methods have shown their great superiority in many medical tasks, they tend to catastrophically forget, over fit, and get results too late when performing diagnosis and prognosis in the continuous mode. In this work, we summarized the three requirements of this task, proposed a new concept, continuous classification of time series (CCTS), and designed a novel model training method, restricted update strategy of neural networks (RU). In the context of continuous prognosis, our method outperformed all baselines and achieved the average accuracy of 90%, 97%, and 85% on sepsis prognosis, COVID-19 mortality prediction, and eight diseases classification. Superiorly, our method can also endow deep learning with interpretability, having the potential to explore disease mechanisms and provide a new horizon for medical research. We have achieved disease staging for sepsis and COVID-19, discovering four stages and three stages with their typical biomarkers respectively. Further, our method is a data-agnostic and model-agnostic plug-in, it can be used to continuously prognose other diseases with staging and even implement CCTS in other fields.
Confidence-Guided Learning Process for Continuous Classification of Time Series
Aug 14, 2022
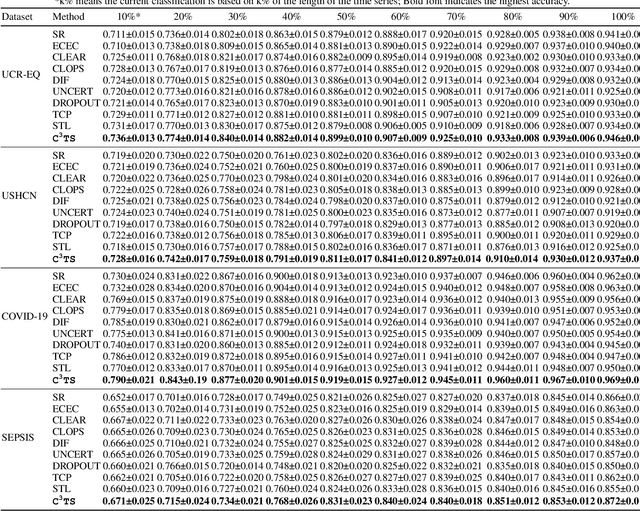
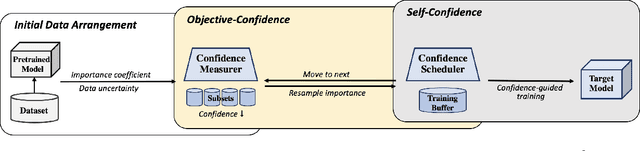
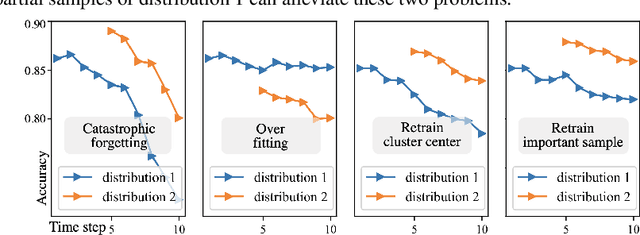
In the real world, the class of a time series is usually labeled at the final time, but many applications require to classify time series at every time point. e.g. the outcome of a critical patient is only determined at the end, but he should be diagnosed at all times for timely treatment. Thus, we propose a new concept: Continuous Classification of Time Series (CCTS). It requires the model to learn data in different time stages. But the time series evolves dynamically, leading to different data distributions. When a model learns multi-distribution, it always forgets or overfits. We suggest that meaningful learning scheduling is potential due to an interesting observation: Measured by confidence, the process of model learning multiple distributions is similar to the process of human learning multiple knowledge. Thus, we propose a novel Confidence-guided method for CCTS (C3TS). It can imitate the alternating human confidence described by the Dunning-Kruger Effect. We define the objective- confidence to arrange data, and the self-confidence to control the learning duration. Experiments on four real-world datasets show that C3TS is more accurate than all baselines for CCTS.
GRP-FED: Addressing Client Imbalance in Federated Learning via Global-Regularized Personalization
Aug 31, 2021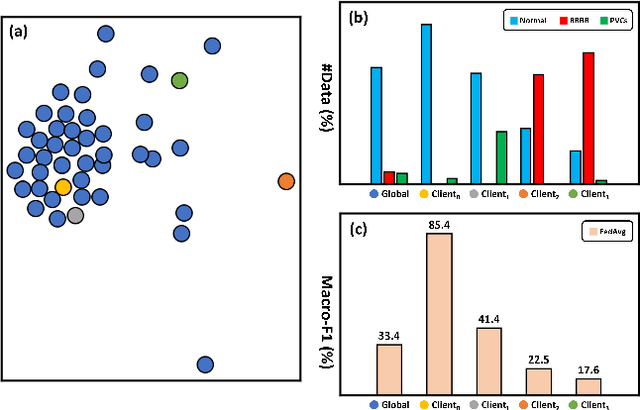
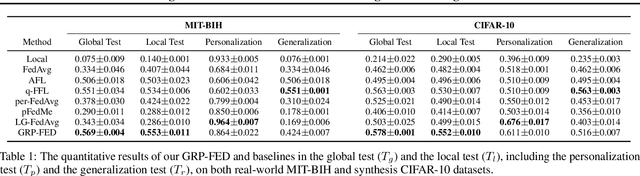
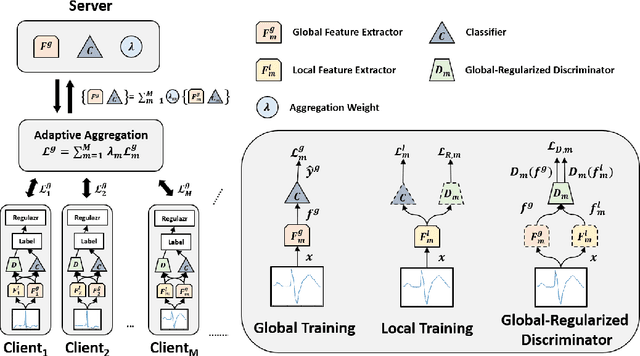
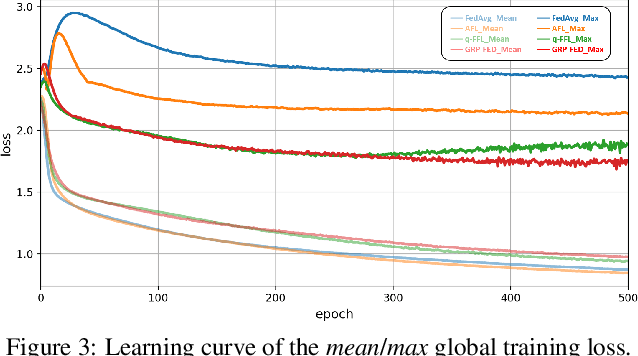
Since data is presented long-tailed in reality, it is challenging for Federated Learning (FL) to train across decentralized clients as practical applications. We present Global-Regularized Personalization (GRP-FED) to tackle the data imbalanced issue by considering a single global model and multiple local models for each client. With adaptive aggregation, the global model treats multiple clients fairly and mitigates the global long-tailed issue. Each local model is learned from the local data and aligns with its distribution for customization. To prevent the local model from just overfitting, GRP-FED applies an adversarial discriminator to regularize between the learned global-local features. Extensive results show that our GRP-FED improves under both global and local scenarios on real-world MIT-BIH and synthesis CIFAR-10 datasets, achieving comparable performance and addressing client imbalance.
TE-ESN: Time Encoding Echo State Network for Prediction Based on Irregularly Sampled Time Series Data
May 02, 2021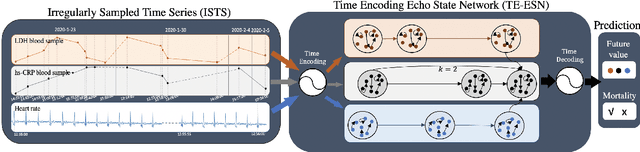

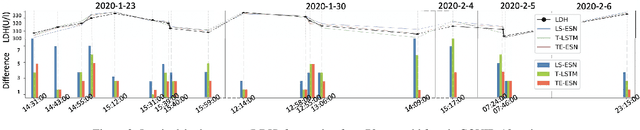
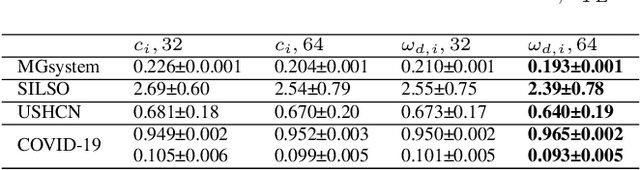
Prediction based on Irregularly Sampled Time Series (ISTS) is of wide concern in the real-world applications. For more accurate prediction, the methods had better grasp more data characteristics. Different from ordinary time series, ISTS is characterised with irregular time intervals of intra-series and different sampling rates of inter-series. However, existing methods have suboptimal predictions due to artificially introducing new dependencies in a time series and biasedly learning relations among time series when modeling these two characteristics. In this work, we propose a novel Time Encoding (TE) mechanism. TE can embed the time information as time vectors in the complex domain. It has the the properties of absolute distance and relative distance under different sampling rates, which helps to represent both two irregularities of ISTS. Meanwhile, we create a new model structure named Time Encoding Echo State Network (TE-ESN). It is the first ESNs-based model that can process ISTS data. Besides, TE-ESN can incorporate long short-term memories and series fusion to grasp horizontal and vertical relations. Experiments on one chaos system and three real-world datasets show that TE-ESN performs better than all baselines and has better reservoir property.
A Review of Designs and Applications of Echo State Networks
Dec 05, 2020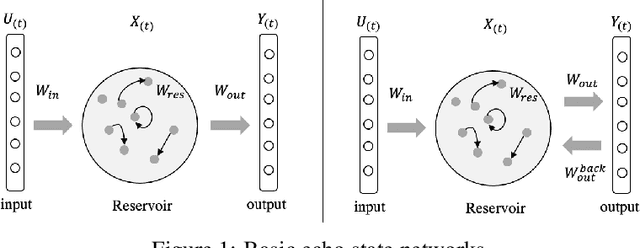
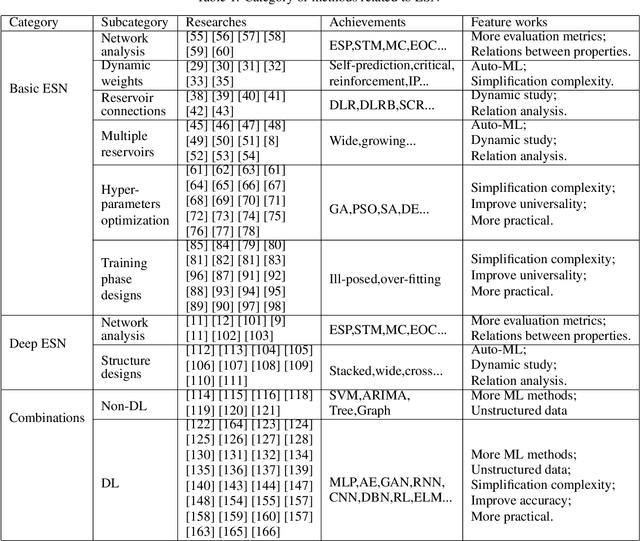
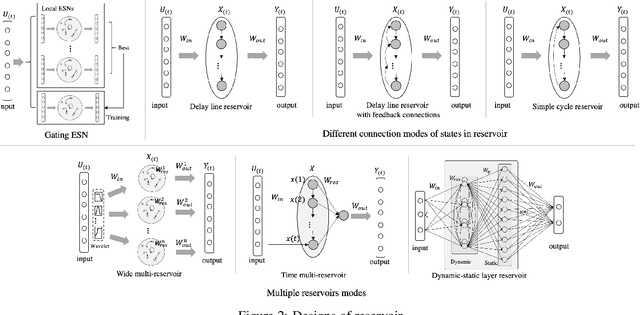
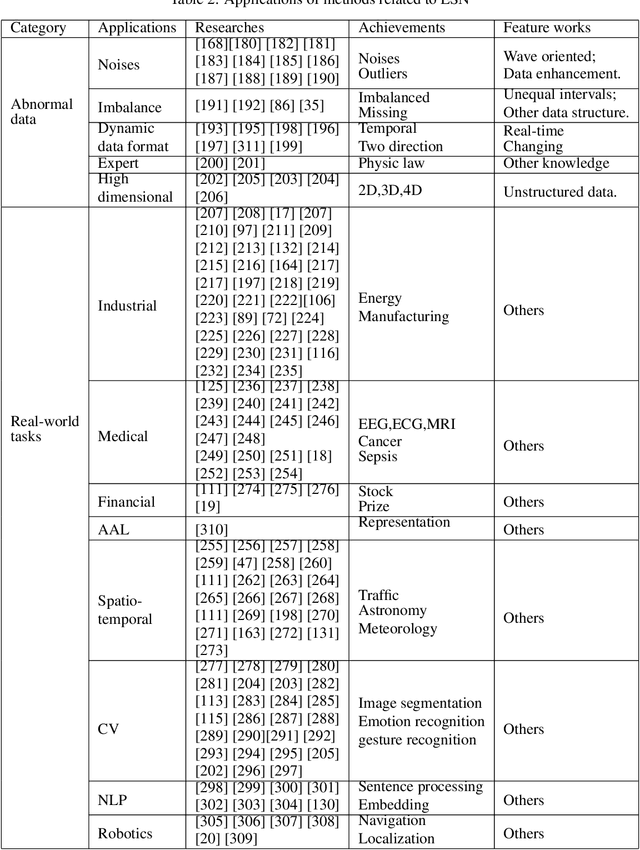
Recurrent Neural Networks (RNNs) have demonstrated their outstanding ability in sequence tasks and have achieved state-of-the-art in wide range of applications, such as industrial, medical, economic and linguistic. Echo State Network (ESN) is simple type of RNNs and has emerged in the last decade as an alternative to gradient descent training based RNNs. ESN, with a strong theoretical ground, is practical, conceptually simple, easy to implement. It avoids non-converging and computationally expensive in the gradient descent methods. Since ESN was put forward in 2002, abundant existing works have promoted the progress of ESN, and the recently introduced Deep ESN model opened the way to uniting the merits of deep learning and ESNs. Besides, the combinations of ESNs with other machine learning models have also overperformed baselines in some applications. However, the apparent simplicity of ESNs can sometimes be deceptive and successfully applying ESNs needs some experience. Thus, in this paper, we categorize the ESN-based methods to basic ESNs, DeepESNs and combinations, then analyze them from the perspective of theoretical studies, network designs and specific applications. Finally, we discuss the challenges and opportunities of ESNs by summarizing the open questions and proposing possible future works.
A Review of Deep Learning Methods for Irregularly Sampled Medical Time Series Data
Oct 26, 2020
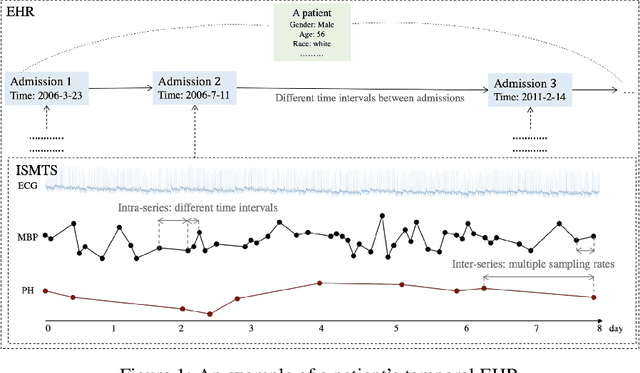

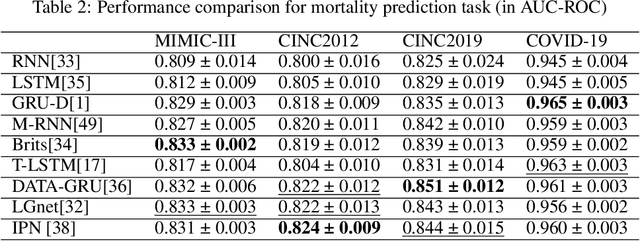
Irregularly sampled time series (ISTS) data has irregular temporal intervals between observations and different sampling rates between sequences. ISTS commonly appears in healthcare, economics, and geoscience. Especially in the medical environment, the widely used Electronic Health Records (EHRs) have abundant typical irregularly sampled medical time series (ISMTS) data. Developing deep learning methods on EHRs data is critical for personalized treatment, precise diagnosis and medical management. However, it is challenging to directly use deep learning models for ISMTS data. On the one hand, ISMTS data has the intra-series and inter-series relations. Both the local and global structures should be considered. On the other hand, methods should consider the trade-off between task accuracy and model complexity and remain generality and interpretability. So far, many existing works have tried to solve the above problems and have achieved good results. In this paper, we review these deep learning methods from the perspectives of technology and task. Under the technology-driven perspective, we summarize them into two categories - missing data-based methods and raw data-based methods. Under the task-driven perspective, we also summarize them into two categories - data imputation-oriented and downstream task-oriented. For each of them, we point out their advantages and disadvantages. Moreover, we implement some representative methods and compare them on four medical datasets with two tasks. Finally, we discuss the challenges and opportunities in this area.