 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Deep Learning Methods for Irregularly Sampled Medical Time Series Data
Paper and Code

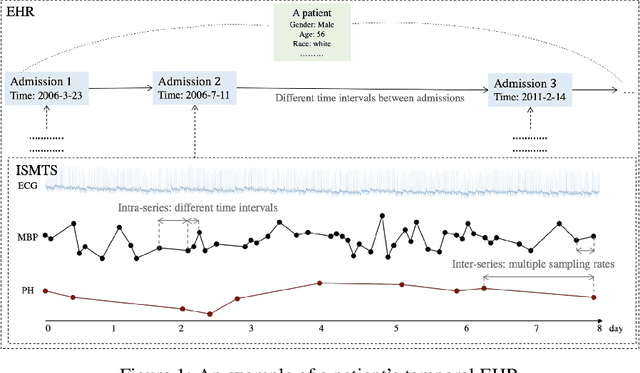

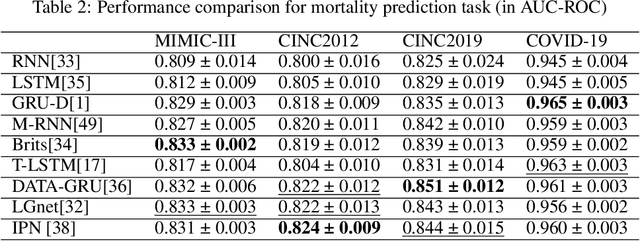
Irregularly sampled time series (ISTS) data has irregular temporal intervals between observations and different sampling rates between sequences. ISTS commonly appears in healthcare, economics, and geoscience. Especially in the medical environment, the widely used Electronic Health Records (EHRs) have abundant typical irregularly sampled medical time series (ISMTS) data. Developing deep learning methods on EHRs data is critical for personalized treatment, precise diagnosis and medical management. However, it is challenging to directly use deep learning models for ISMTS data. On the one hand, ISMTS data has the intra-series and inter-series relations. Both the local and global structures should be considered. On the other hand, methods should consider the trade-off between task accuracy and model complexity and remain generality and interpretability. So far, many existing works have tried to solve the above problems and have achieved good results. In this paper, we review these deep learning methods from the perspectives of technology and task. Under the technology-driven perspective, we summarize them into two categories - missing data-based methods and raw data-based methods. Under the task-driven perspective, we also summarize them into two categories - data imputation-oriented and downstream task-oriented. For each of them, we point out their advantages and disadvantages. Moreover, we implement some representative methods and compare them on four medical datasets with two tasks. Finally, we discuss the challenges and opportunities in this area.