 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepOPSD: Step-Aware Online Preference Distillation for Agent Reinforcement Learning
May 26, 2026Reinforcement learning for multi-turn agents suffers from a credit-assignment mismatch: rewards are sparse and trajectory-level, while success often hinges on a few local decisions. Existing online policy distillation (OPD) provides denser token-level supervision, but typically treats heterogeneous agent trajectories as monolithic strings rather than causal interaction units. We present StepOPSD, a post-rollout preference self-distillation framework that takes the agent step as the unit of credit redistribution. StepOPSD decomposes trajectories into action-centered step segments, rescoring them under hindsight-enriched teacher contexts and converting token-level log-probability gaps into sign-preserving advantage shaping with a normalized per-step credit budget before the GRPO update. Across ALFWorld and Search-QA with Qwen3-1.7B and Qwen2.5-3B-Instruct, StepOPSD attains best or second-best results on subsets most sensitive to local causal errors, including first-place performance on ALFWorld Heat (79.1%), PickTwo (95.0%), Search-QA TriviaQA (61.6%), and tied-best performance on HotpotQA (40.4%). The results further reveal a consistent two-knob law: smaller α_clip acts as a broadly stabilizing local trust region, whereas the optimal global mixing strength λ_mix remains task-dependent. These findings suggest that step-aware distillation is most useful when trajectory-level rewards are weakly aligned with the local action that determines downstream success.
Story2Proposal: A Scaffold for Structured Scientific Paper Writing
Mar 28, 2026Generating scientific manuscripts requires maintaining alignment between narrative reasoning, experimental evidence, and visual artifacts across the document lifecycle. Existing language-model generation pipelines rely on unconstrained text synthesis with validation applied only after generation, often producing structural drift, missing figures or tables, and cross-section inconsistencies. We introduce Story2Proposal, a contract-governed multi-agent framework that converts a research story into a structured manuscript through coordinated agents operating under a persistent shared visual contract. The system organizes architect, writer, refiner, and renderer agents around a contract state that tracks section structure and registered visual elements, while evaluation agents supply feedback in a generate evaluate adapt loop that updates the contract during generation. Experiments on tasks derived from the Jericho research corpus show that Story2Proposal achieved an expert evaluation score of 6.145 versus 3.963 for DirectChat (+2.182) across GPT, Claude, Gemini, and Qwen backbones. Compared with the structured generation baseline Fars, Story2Proposal obtained an average score of 5.705 versus 5.197, indicating improved structural consistency and visual alignment.
YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection
Dec 30, 2025Existing Real-Time Object Detection (RTOD) methods commonly adopt YOLO-like architectures for their favorable trade-off between accuracy and speed. However, these models rely on static dense computation that applies uniform processing to all inputs, misallocating representational capacity and computational resources such as over-allocating on trivial scenes while under-serving complex ones. This mismatch results in both computational redundancy and suboptimal detection performance. To overcome this limitation, we propose YOLO-Master, a novel YOLO-like framework that introduces instance-conditional adaptive computation for RTOD. This is achieved through a Efficient Sparse Mixture-of-Experts (ES-MoE) block that dynamically allocates computational resources to each input according to its scene complexity. At its core, a lightweight dynamic routing network guides expert specialization during training through a diversity enhancing objective, encouraging complementary expertise among experts. Additionally, the routing network adaptively learns to activate only the most relevant experts, thereby improving detection performance while minimizing computational overhead during inference. Comprehensive experiments on five large-scale benchmarks demonstrate the superiority of YOLO-Master. On MS COCO, our model achieves 42.4% AP with 1.62ms latency, outperforming YOLOv13-N by +0.8% mAP and 17.8% faster inference. Notably, the gains are most pronounced on challenging dense scenes, while the model preserves efficiency on typical inputs and maintains real-time inference speed. Code will be available.
Cross-Sample Augmented Test-Time Adaptation for Personalized Intraoperative Hypotension Prediction
Dec 12, 2025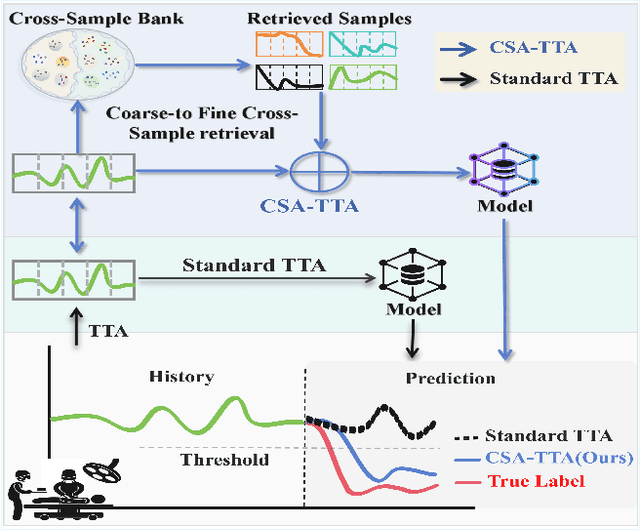
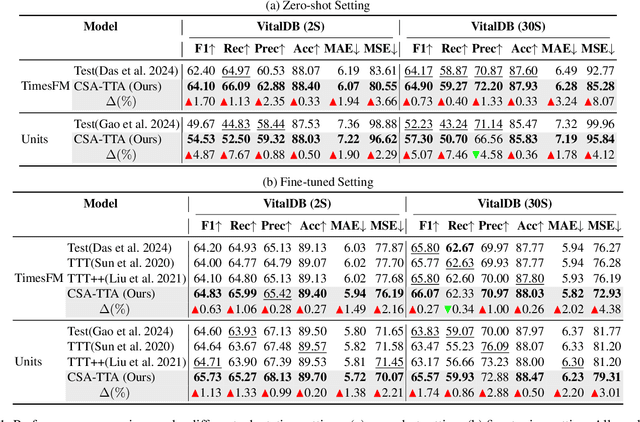
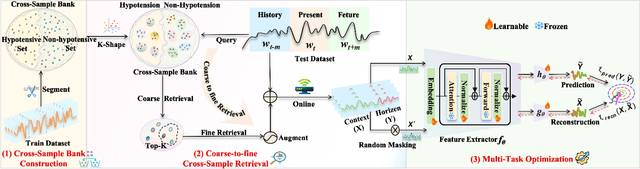
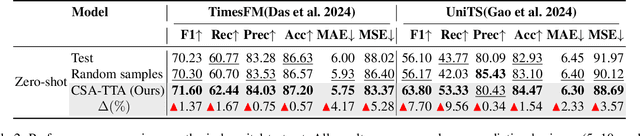
Intraoperative hypotension (IOH) poses significant surgical risks, but accurate prediction remains challenging due to patient-specific variability. While test-time adaptation (TTA) offers a promising approach for personalized prediction, the rarity of IOH events often leads to unreliable test-time training. To address this, we propose CSA-TTA, a novel Cross-Sample Augmented Test-Time Adaptation framework that enhances training by incorporating hypotension events from other individuals. Specifically, we first construct a cross-sample bank by segmenting historical data into hypotensive and non-hypotensive samples. Then, we introduce a coarse-to-fine retrieval strategy for building test-time training data: we initially apply K-Shape clustering to identify representative cluster centers and subsequently retrieve the top-K semantically similar samples based on the current patient signal. Additionally, we integrate both self-supervised masked reconstruction and retrospective sequence forecasting signals during training to enhance model adaptability to rapid and subtle intraoperative dynamics. We evaluate the proposed CSA-TTA on both the VitalDB dataset and a real-world in-hospital dataset by integrating it with state-of-the-art time series forecasting models, including TimesFM and UniTS. CSA-TTA consistently enhances performance across settings-for instance, on VitalDB, it improves Recall and F1 scores by +1.33% and +1.13%, respectively, under fine-tuning, and by +7.46% and +5.07% in zero-shot scenarios-demonstrating strong robustness and generalization.
MMOT: The First Challenging Benchmark for Drone-based Multispectral Multi-Object Tracking
Oct 14, 2025Drone-based multi-object tracking is essential yet highly challenging due to small targets, severe occlusions, and cluttered backgrounds. Existing RGB-based tracking algorithms heavily depend on spatial appearance cues such as color and texture, which often degrade in aerial views, compromising reliability. Multispectral imagery, capturing pixel-level spectral reflectance, provides crucial cues that enhance object discriminability under degraded spatial conditions. However, the lack of dedicated multispectral UAV datasets has hindered progress in this domain. To bridge this gap, we introduce MMOT, the first challenging benchmark for drone-based multispectral multi-object tracking. It features three key characteristics: (i) Large Scale - 125 video sequences with over 488.8K annotations across eight categories; (ii) Comprehensive Challenges - covering diverse conditions such as extreme small targets, high-density scenarios, severe occlusions, and complex motion; and (iii) Precise Oriented Annotations - enabling accurate localization and reduced ambiguity under aerial perspectives. To better extract spectral features and leverage oriented annotations, we further present a multispectral and orientation-aware MOT scheme adapting existing methods, featuring: (i) a lightweight Spectral 3D-Stem integrating spectral features while preserving compatibility with RGB pretraining; (ii) an orientation-aware Kalman filter for precise state estimation; and (iii) an end-to-end orientation-adaptive transformer. Extensive experiments across representative trackers consistently show that multispectral input markedly improves tracking performance over RGB baselines, particularly for small and densely packed objects. We believe our work will advance drone-based multispectral multi-object tracking research. Our MMOT, code, and benchmarks are publicly available at https://github.com/Annzstbl/MMOT.
Temporal-Oriented Recipe for Transferring Large Vision-Language Model to Video Understanding
May 19, 2025Recent years have witnessed outstanding advances of large vision-language models (LVLMs). In order to tackle video understanding, most of them depend upon their implicit temporal understanding capacity. As such, they have not deciphered important components that contribute to temporal understanding ability, which might limit the potential of these LVLMs for video understanding. In this work, we conduct a thorough empirical study to demystify crucial components that influence the temporal understanding of LVLMs. Our empirical study reveals that significant impacts are centered around the intermediate interface between the visual encoder and the large language model. Building on these insights, we propose a temporal-oriented recipe that encompasses temporal-oriented training schemes and an upscaled interface. Our final model developed using our recipe significantly enhances previous LVLMs on standard video understanding tasks.
Towards Training A Chinese Large Language Model for Anesthesiology
Mar 05, 2024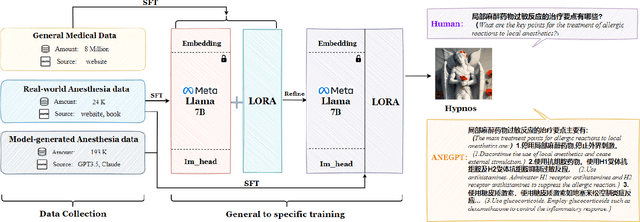
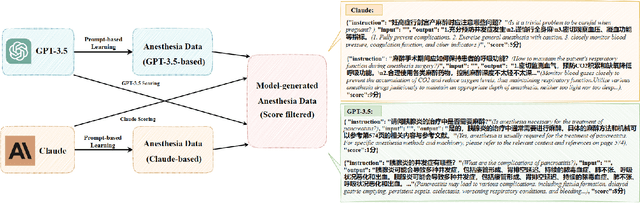
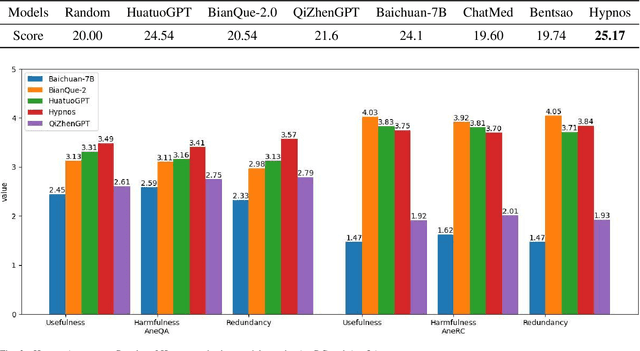
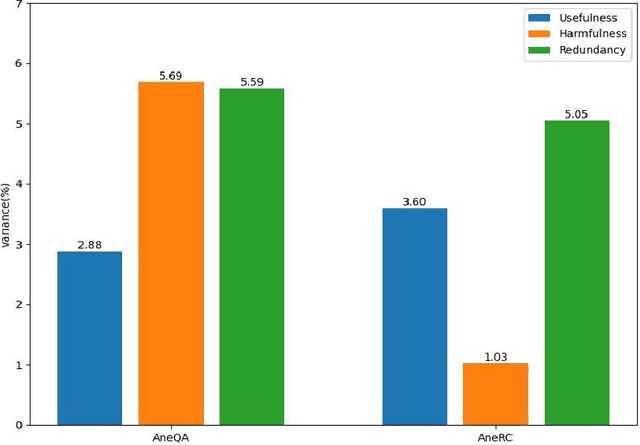
Medical large language models (LLMs) have gained popularity recently due to their significant practical utility. However, most existing research focuses on general medicine, and there is a need for in-depth study of LLMs in specific fields like anesthesiology. To fill the gap, we introduce Hypnos, a Chinese Anesthesia model built upon existing LLMs, e.g., Llama. Hypnos' contributions have three aspects: 1) The data, such as utilizing Self-Instruct, acquired from current LLMs likely includes inaccuracies. Hypnos implements a cross-filtering strategy to improve the data quality. This strategy involves using one LLM to assess the quality of the generated data from another LLM and filtering out the data with low quality. 2) Hypnos employs a general-to-specific training strategy that starts by fine-tuning LLMs using the general medicine data and subsequently improving the fine-tuned LLMs using data specifically from Anesthesiology. The general medical data supplement the medical expertise in Anesthesiology and enhance the effectiveness of Hypnos' generation. 3) We introduce a standardized benchmark for evaluating medical LLM in Anesthesiology. Our benchmark includes both publicly available instances from the Internet and privately obtained cases from the Hospital. Hypnos outperforms other medical LLMs in anesthesiology in metrics, GPT-4, and human evaluation on the benchmark dataset.
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Jul 02, 2023
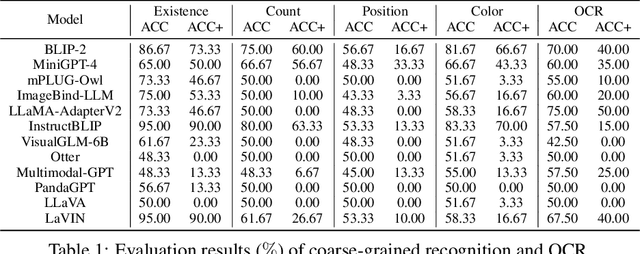
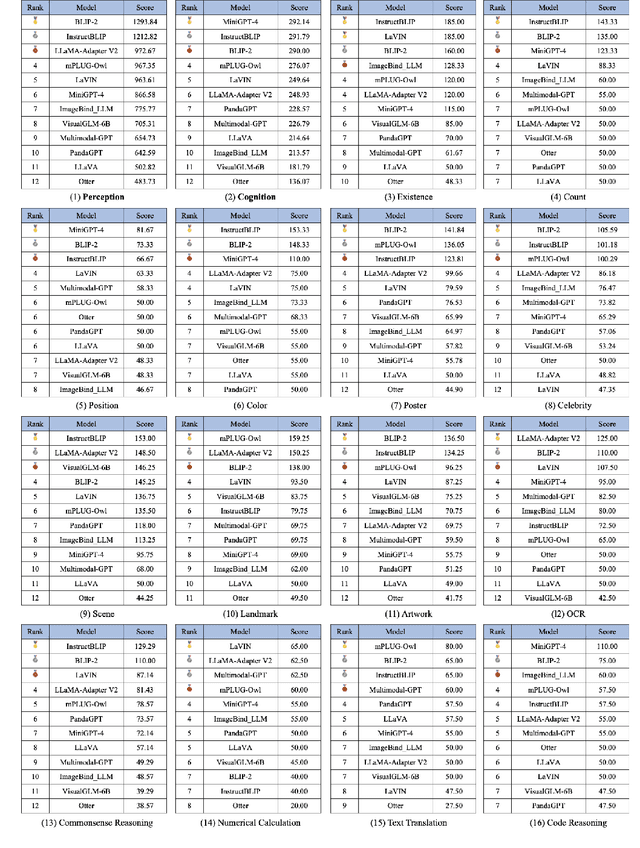
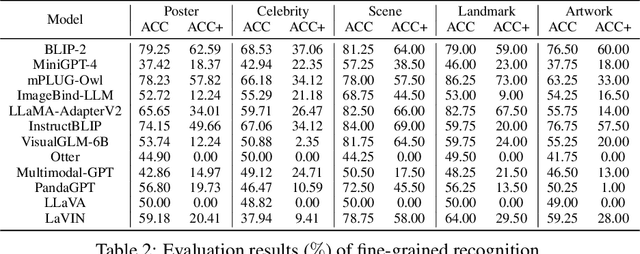
Multimodal Large Language Model (MLLM) relies on the powerful LLM to perform multimodal tasks, showing amazing emergent abilities in recent studies, such as writing poems based on an image. However, it is difficult for these case studies to fully reflect the performance of MLLM, lacking a comprehensive evaluation. In this paper, we fill in this blank, presenting the first MLLM Evaluation benchmark MME. It measures both perception and cognition abilities on a total of 14 subtasks. In order to avoid data leakage that may arise from direct use of public datasets for evaluation, the annotations of instruction-answer pairs are all manually designed. The concise instruction design allows us to fairly compare MLLMs, instead of struggling in prompt engineering. Besides, with such an instruction, we can also easily carry out quantitative statistics. A total of 12 advanced MLLMs are comprehensively evaluated on our MME, which not only suggests that existing MLLMs still have a large room for improvement, but also reveals the potential directions for the subsequent model optimization.