 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashSloth: Lightning Multimodal Large Language Models via Embedded Visual Compression
Paper and Code

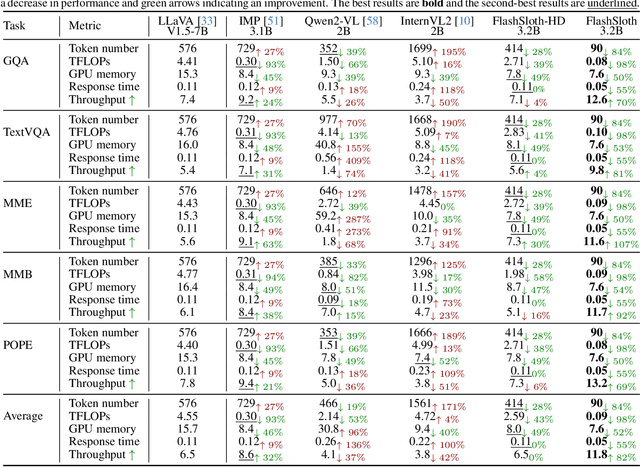
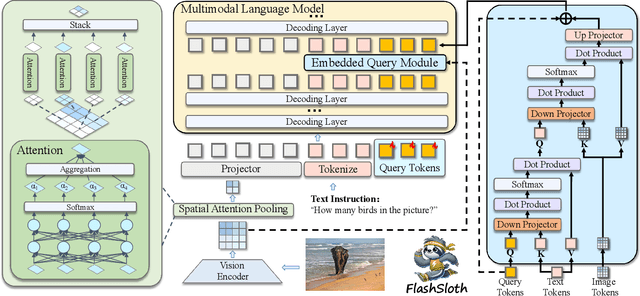

Despite a big leap forward in capability, multimodal large language models (MLLMs) tend to behave like a sloth in practical use, i.e., slow response and large latency. Recent efforts are devoted to building tiny MLLMs for better efficiency, but the plethora of visual tokens still used limit their actual speedup. In this paper, we propose a powerful and fast tiny MLLM called FlashSloth. Different from previous efforts, FlashSloth focuses on improving the descriptive power of visual tokens in the process of compressing their redundant semantics. In particular, FlashSloth introduces embedded visual compression designs to capture both visually salient and instruction-related image information, so as to achieving superior multimodal performance with fewer visual tokens. Extensive experiments are conducted to validate the proposed FlashSloth, and a bunch of tiny but strong MLLMs are also comprehensively compared, e.g., InternVL2, MiniCPM-V2 and Qwen2-VL. The experimental results show that compared with these advanced tiny MLLMs, our FlashSloth can greatly reduce the number of visual tokens, training memory and computation complexity while retaining high performance on various VL tasks.