 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashSloth: Lightning Multimodal Large Language Models via Embedded Visual Compression
Dec 05, 2024
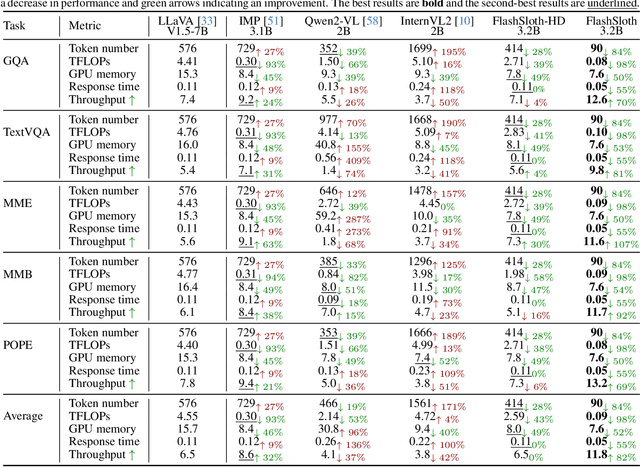
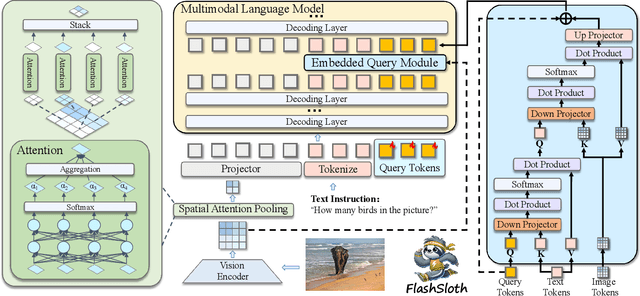

Despite a big leap forward in capability, multimodal large language models (MLLMs) tend to behave like a sloth in practical use, i.e., slow response and large latency. Recent efforts are devoted to building tiny MLLMs for better efficiency, but the plethora of visual tokens still used limit their actual speedup. In this paper, we propose a powerful and fast tiny MLLM called FlashSloth. Different from previous efforts, FlashSloth focuses on improving the descriptive power of visual tokens in the process of compressing their redundant semantics. In particular, FlashSloth introduces embedded visual compression designs to capture both visually salient and instruction-related image information, so as to achieving superior multimodal performance with fewer visual tokens. Extensive experiments are conducted to validate the proposed FlashSloth, and a bunch of tiny but strong MLLMs are also comprehensively compared, e.g., InternVL2, MiniCPM-V2 and Qwen2-VL. The experimental results show that compared with these advanced tiny MLLMs, our FlashSloth can greatly reduce the number of visual tokens, training memory and computation complexity while retaining high performance on various VL tasks.
Deep Instruction Tuning for Segment Anything Model
Mar 31, 2024Segment Anything Model (SAM) exhibits powerful yet versatile capabilities on (un) conditional image segmentation tasks recently. Although SAM can support various segmentation prompts, we note that, compared to point- and box-guided segmentation, it performs much worse on text-instructed tasks. We argue that deep text instruction tuning is key to mitigate such shortcoming caused by the shallow fusion scheme in its default light-weight mask decoder. In this paper, two \emph{deep instruction tuning} (DIT) methods are proposed, one is end-to-end and the other is layer-wise. With these tuning methods, we can regard the image encoder of SAM as a stand-alone vision-language learner in contrast to building another deep fusion branch. Extensive experiments on three highly competitive benchmark datasets of referring image segmentation show that a simple end-to-end DIT improves SAM by a large margin, with layer-wise DIT further boosts the performance to state-of-the-art. Our code is anonymously released at: https://github.com/wysnzzzz/DIT.
PK-Chat: Pointer Network Guided Knowledge Driven Generative Dialogue Model
Apr 02, 2023
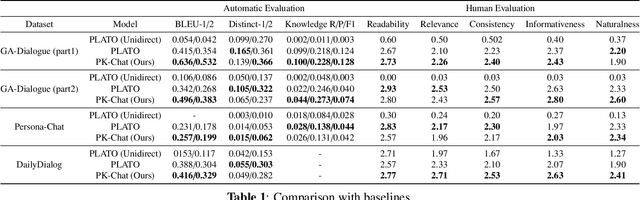
In the research of end-to-end dialogue systems, using real-world knowledge to generate natural, fluent, and human-like utterances with correct answers is crucial. However, domain-specific conversational dialogue systems may be incoherent and introduce erroneous external information to answer questions due to the out-of-vocabulary issue or the wrong knowledge from the parameters of the neural network. In this work, we propose PK-Chat, a Pointer network guided Knowledge-driven generative dialogue model, incorporating a unified pretrained language model and a pointer network over knowledge graphs. The words generated by PK-Chat in the dialogue are derived from the prediction of word lists and the direct prediction of the external knowledge graph knowledge. Moreover, based on the PK-Chat, a dialogue system is built for academic scenarios in the case of geosciences. Finally, an academic dialogue benchmark is constructed to evaluate the quality of dialogue systems in academic scenarios and the source code is available online.