 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Multimodal Large Language Models via Dynamic Visual-Token Exit and the Empirical Findings
Paper and Code
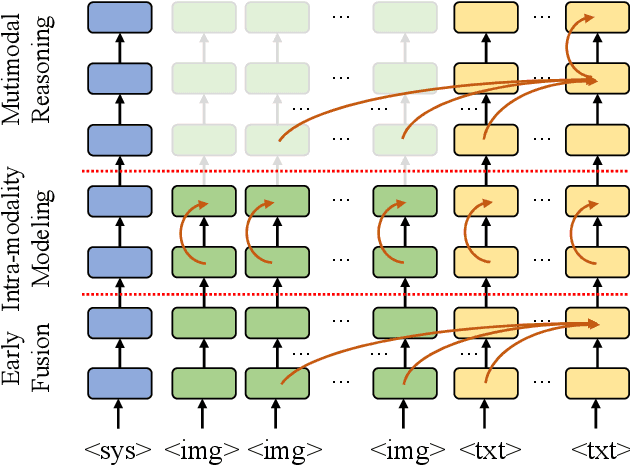


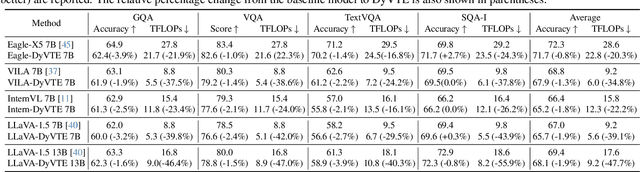
The excessive use of visual tokens in existing Multimoal Large Language Models (MLLMs) often exhibits obvious redundancy and brings in prohibitively expensive computation. To gain insights into this problem, we first conduct extensive empirical studies on the attention behaviors of MLLMs, and summarize three main inference stages in MLLMs: (i) Early fusion between tokens is first accomplished quickly. (ii) Intra-modality modeling then comes to play. (iii) Multimodal reasoning} resumes and lasts until the end of inference. In particular, we reveal that visual tokens will stop contributing to reasoning when the text tokens receive enough image information, yielding obvious visual redundancy. Based on these generalized observations, we propose a simple yet effective method to improve the efficiency of MLLMs, termed dynamic visual-token exit (DyVTE). DyVTE uses lightweight hyper-networks to perceive the text token status and decide the removal of all visual tokens after a certain layer, thereby addressing the observed visual redundancy. To validate VTE, we apply it to a set of MLLMs, including LLaVA, VILA, Eagle and InternVL, and conduct extensive experiments on a bunch of benchmarks. The experiment results not only show the effectiveness of our VTE in improving MLLMs' efficiency, but also yield the general modeling patterns of MLLMs, well facilitating the in-depth understanding of MLLMs. Our code is anonymously released at https://github.com/DoubtedSteam/DyVTE.