 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXStreamVGGT: Extremely Memory-Efficient Streaming Vision Geometry Grounded Transformer with KV Cache Compression
Jan 03, 2026Learning-based 3D visual geometry models have benefited substantially from large-scale transformers. Among these, StreamVGGT leverages frame-wise causal attention for strong streaming reconstruction, but suffers from unbounded KV cache growth, leading to escalating memory consumption and inference latency as input frames accumulate. We propose XStreamVGGT, a tuning-free approach that systematically compresses the KV cache through joint pruning and quantization, enabling extremely memory-efficient streaming inference. Specifically, redundant KVs originating from multi-view inputs are pruned through efficient token importance identification, enabling a fixed memory budget. Leveraging the unique distribution of KV tensors, we incorporate KV quantization to further reduce memory consumption. Extensive evaluations show that XStreamVGGT achieves mostly negligible performance degradation while substantially reducing memory usage by 4.42$\times$ and accelerating inference by 5.48$\times$, enabling scalable and practical streaming 3D applications. The code is available at https://github.com/ywh187/XStreamVGGT/.
CCF: A Context Compression Framework for Efficient Long-Sequence Language Modeling
Sep 11, 2025Scaling language models to longer contexts is essential for capturing rich dependencies across extended discourse. However, na\"ive context extension imposes significant computational and memory burdens, often resulting in inefficiencies during both training and inference. In this work, we propose CCF, a novel context compression framework designed to enable efficient long-context modeling by learning hierarchical latent representations that preserve global semantics while aggressively reducing input redundancy. CCF integrates segment-wise semantic aggregation with key-value memory encoding, forming compact representations that support accurate reconstruction and long-range understanding. To further enhance scalability, we introduce a training-efficient optimization strategy that couples incremental segment decoding with sparse reservoir sampling, substantially reducing memory overhead without degrading performance. Empirical results on multiple long-context language modeling benchmarks demonstrate that CCF achieves competitive perplexity under high compression ratios, and significantly improves throughput and memory efficiency compared to existing approaches. These findings highlight the potential of structured compression for scalable and effective long-context language modeling.
Accelerating Multimodal Large Language Models via Dynamic Visual-Token Exit and the Empirical Findings
Nov 29, 2024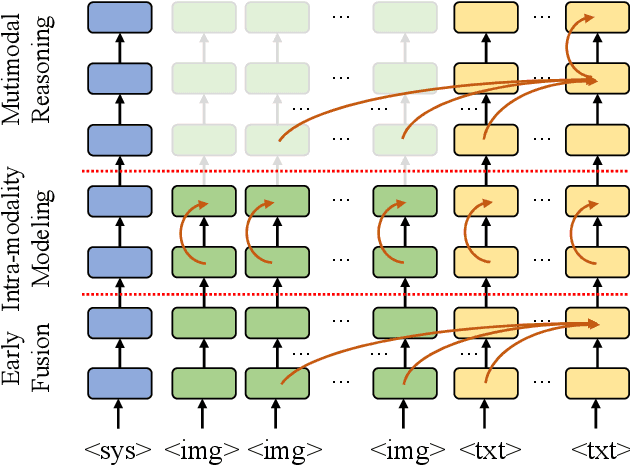


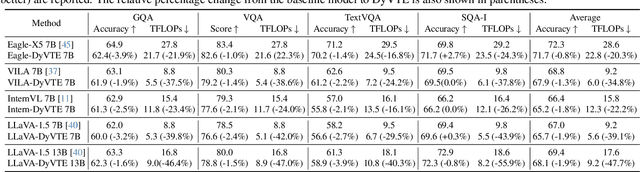
The excessive use of visual tokens in existing Multimoal Large Language Models (MLLMs) often exhibits obvious redundancy and brings in prohibitively expensive computation. To gain insights into this problem, we first conduct extensive empirical studies on the attention behaviors of MLLMs, and summarize three main inference stages in MLLMs: (i) Early fusion between tokens is first accomplished quickly. (ii) Intra-modality modeling then comes to play. (iii) Multimodal reasoning} resumes and lasts until the end of inference. In particular, we reveal that visual tokens will stop contributing to reasoning when the text tokens receive enough image information, yielding obvious visual redundancy. Based on these generalized observations, we propose a simple yet effective method to improve the efficiency of MLLMs, termed dynamic visual-token exit (DyVTE). DyVTE uses lightweight hyper-networks to perceive the text token status and decide the removal of all visual tokens after a certain layer, thereby addressing the observed visual redundancy. To validate VTE, we apply it to a set of MLLMs, including LLaVA, VILA, Eagle and InternVL, and conduct extensive experiments on a bunch of benchmarks. The experiment results not only show the effectiveness of our VTE in improving MLLMs' efficiency, but also yield the general modeling patterns of MLLMs, well facilitating the in-depth understanding of MLLMs. Our code is anonymously released at https://github.com/DoubtedSteam/DyVTE.
Fit and Prune: Fast and Training-free Visual Token Pruning for Multi-modal Large Language Models
Sep 16, 2024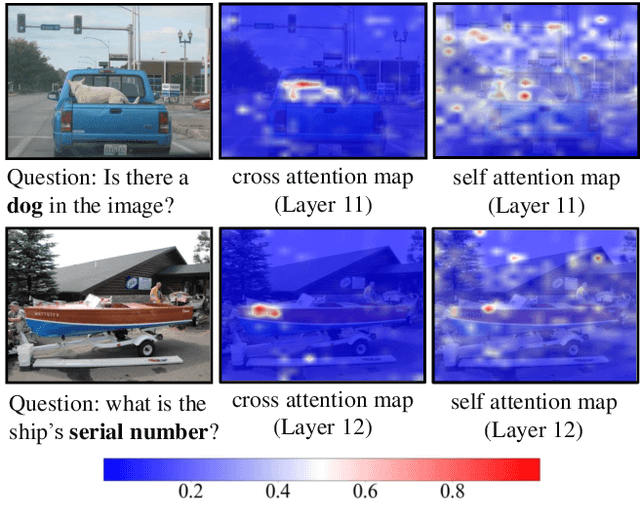



Recent progress in Multimodal Large Language Models(MLLMs) often use large image tokens to compensate the visual shortcoming of MLLMs, which not only exhibits obvious redundancy but also greatly exacerbates the already high computation. Token pruning is an effective solution for speeding up MLLMs, but when and how to drop tokens still remains a challenge. In this paper, we propose a novel and training-free approach for the effective visual token pruning of MLLMs, termed FitPrune, which can quickly produce a complete pruning recipe for MLLMs according to a pre-defined budget. Specifically, FitPrune considers token pruning as a statistical problem of MLLM and its objective is to find out an optimal pruning scheme that can minimize the divergence of the attention distributions before and after pruning. In practice, FitPrune can be quickly accomplished based on the attention statistics from a small batch of inference data, avoiding the expensive trials of MLLMs. According to the pruning recipe, an MLLM can directly remove the redundant visual tokens of different examples during inference. To validate FitPrune, we apply it to a set of recent MLLMs, including LLaVA-1.5, LLaVA-HR and LLaVA-NEXT, and conduct extensive experiments on a set of benchmarks. The experimental results show that our FitPrune can not only reduce the computational complexity to a large extent, while retaining high performance, e.g., -54.9% FLOPs for LLaVA-NEXT with only 0.5% accuracy drop. Notably, the pruning recipe can be obtained in about 5 minutes. Our code is available at https://github.com/ywh187/FitPrune.
Not All Attention is Needed: Parameter and Computation Efficient Transfer Learning for Multi-modal Large Language Models
Mar 22, 2024In this paper, we propose a novel parameter and computation efficient tuning method for Multi-modal Large Language Models (MLLMs), termed Efficient Attention Skipping (EAS). Concretely, we first reveal that multi-head attentions (MHAs), the main computational overhead of MLLMs, are often redundant to downstream tasks. Based on this observation, EAS evaluates the attention redundancy and skips the less important MHAs to speed up inference. Besides, we also propose a novel propagation-of-information adapter (PIA) to serve the attention skipping of EAS and keep parameter efficiency, which can be further re-parameterized into feed-forward networks (FFNs) for zero-extra latency. To validate EAS, we apply it to a recently proposed MLLM called LaVIN and a classic VL pre-trained model called METER, and conduct extensive experiments on a set of benchmarks. The experiments show that EAS not only retains high performance and parameter efficiency, but also greatly speeds up inference speed. For instance, LaVIN-EAS can obtain 89.98\% accuracy on ScineceQA while speeding up inference by 2.2 times to LaVIN