 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoveltyAgent: Autonomous Novelty Reporting Agent with Point-wise Novelty Analysis and Self-Validation
Mar 21, 2026The exponential growth of academic publications has led to a surge in papers of varying quality, increasing the cost of paper screening. Current approaches either use novelty assessment within general AI Reviewers or repurpose DeepResearch, which lacks domain-specific mechanisms and thus delivers lower-quality results. To bridge this gap, we introduce NoveltyAgent, a multi-agent system designed to generate comprehensive and faithful novelty reports, enabling thorough evaluation of a paper's originality. It decomposes manuscripts into discrete novelty points for fine-grained retrieval and comparison, and builds a comprehensive related-paper database while cross-referencing claims to ensure faithfulness. Furthermore, to address the challenge of evaluating such open-ended generation tasks, we propose a checklist-based evaluation framework, providing an unbiased paradigm for building reliable evaluations. Extensive experiments show that NoveltyAgent achieves state-of-the-art performance, outperforming GPT-5 DeepResearch by 10.15%. We hope this system will provide reliable, high-quality novelty analysis and help researchers quickly identify novel papers. Code and demo are available at https://github.com/SStan1/NoveltyAgent.
AQuilt: Weaving Logic and Self-Inspection into Low-Cost, High-Relevance Data Synthesis for Specialist LLMs
Jul 24, 2025Despite the impressive performance of large language models (LLMs) in general domains, they often underperform in specialized domains. Existing approaches typically rely on data synthesis methods and yield promising results by using unlabeled data to capture domain-specific features. However, these methods either incur high computational costs or suffer from performance limitations, while also demonstrating insufficient generalization across different tasks. To address these challenges, we propose AQuilt, a framework for constructing instruction-tuning data for any specialized domains from corresponding unlabeled data, including Answer, Question, Unlabeled data, Inspection, Logic, and Task type. By incorporating logic and inspection, we encourage reasoning processes and self-inspection to enhance model performance. Moreover, customizable task instructions enable high-quality data generation for any task. As a result, we construct a dataset of 703k examples to train a powerful data synthesis model. Experiments show that AQuilt is comparable to DeepSeek-V3 while utilizing just 17% of the production cost. Further analysis demonstrates that our generated data exhibits higher relevance to downstream tasks. Source code, models, and scripts are available at https://github.com/Krueske/AQuilt.
Order Acquisition Under Competitive Pressure: A Rapidly Adaptive Reinforcement Learning Approach for Ride-Hailing Subsidy Strategies
Jul 03, 2025The proliferation of ride-hailing aggregator platforms presents significant growth opportunities for ride-service providers by increasing order volume and gross merchandise value (GMV). On most ride-hailing aggregator platforms, service providers that offer lower fares are ranked higher in listings and, consequently, are more likely to be selected by passengers. This competitive ranking mechanism creates a strong incentive for service providers to adopt coupon strategies that lower prices to secure a greater number of orders, as order volume directly influences their long-term viability and sustainability. Thus, designing an effective coupon strategy that can dynamically adapt to market fluctuations while optimizing order acquisition under budget constraints is a critical research challenge. However, existing studies in this area remain scarce. To bridge this gap, we propose FCA-RL, a novel reinforcement learning-based subsidy strategy framework designed to rapidly adapt to competitors' pricing adjustments. Our approach integrates two key techniques: Fast Competition Adaptation (FCA), which enables swift responses to dynamic price changes, and Reinforced Lagrangian Adjustment (RLA), which ensures adherence to budget constraints while optimizing coupon decisions on new price landscape. Furthermore, we introduce RideGym, the first dedicated simulation environment tailored for ride-hailing aggregators, facilitating comprehensive evaluation and benchmarking of different pricing strategies without compromising real-world operational efficiency. Experimental results demonstrate that our proposed method consistently outperforms baseline approaches across diverse market conditions, highlighting its effectiveness in subsidy optimization for ride-hailing service providers.
Towards Adversarially Robust Deep Metric Learning
Jan 02, 2025Deep Metric Learning (DML) has shown remarkable successes in many domains by taking advantage of powerful deep neural networks. Deep neural networks are prone to adversarial attacks and could be easily fooled by adversarial examples. The current progress on this robustness issue is mainly about deep classification models but pays little attention to DML models. Existing works fail to thoroughly inspect the robustness of DML and neglect an important DML scenario, the clustering-based inference. In this work, we first point out the robustness issue of DML models in clustering-based inference scenarios. We find that, for the clustering-based inference, existing defenses designed DML are unable to be reused and the adaptions of defenses designed for deep classification models cannot achieve satisfactory robustness performance. To alleviate the hazard of adversarial examples, we propose a new defense, the Ensemble Adversarial Training (EAT), which exploits ensemble learning and adversarial training. EAT promotes the diversity of the ensemble, encouraging each model in the ensemble to have different robustness features, and employs a self-transferring mechanism to make full use of the robustness statistics of the whole ensemble in the update of every single model. We evaluate the EAT method on three widely-used datasets with two popular model architectures. The results show that the proposed EAT method greatly outperforms the adaptions of defenses designed for deep classification models.
FLiP: Privacy-Preserving Federated Learning based on the Principle of Least Privileg
Oct 25, 2024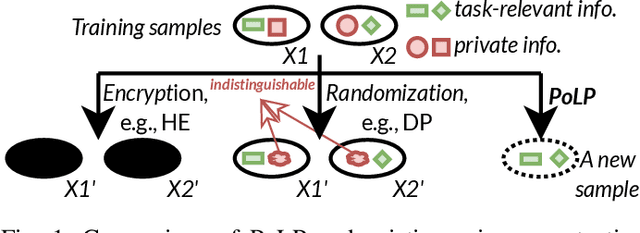
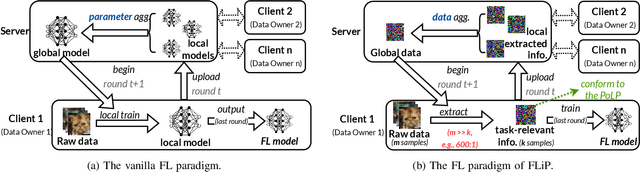
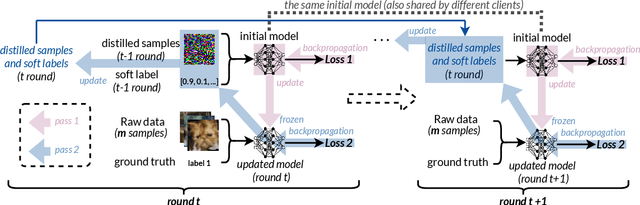

Federated Learning (FL) allows users to share knowledge instead of raw data to train a model with high accuracy. Unfortunately, during the training, users lose control over the knowledge shared, which causes serious data privacy issues. We hold that users are only willing and need to share the essential knowledge to the training task to obtain the FL model with high accuracy. However, existing efforts cannot help users minimize the shared knowledge according to the user intention in the FL training procedure. This work proposes FLiP, which aims to bring the principle of least privilege (PoLP) to FL training. The key design of FLiP is applying elaborate information reduction on the training data through a local-global dataset distillation design. We measure the privacy performance through attribute inference and membership inference attacks. Extensive experiments show that FLiP strikes a good balance between model accuracy and privacy protection.