 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Reasoning and Generalization in Text-to-SQL via Self-Enhanced Fine-Tuning
Jun 14, 2026Text-to-SQL aims to translate natural language questions into executable SQL queries over structured databases, enabling non-expert users to access data intuitively. While recent advances in large language models (LLMs) have shown promise in this task, existing LLM-based approaches often struggle to strike a balance between strong reasoning capabilities and robust generalization. To address these limitations, we propose CoTE-SQL to enhance the LLM-based text-to-SQL generation with three key innovations: (i) self-enhanced reasoning traces distilled from LLMs without human annotation, (ii) structured chain-of-thought (CoT) prompting with modular decomposition and examples retrieval, and (iii) error-aware revision based on SQL execution feedback. Extensive experiments on the Spider and Bird benchmarks demonstrate that CoTE-SQL achieves new state-of-the-art performance among methods built on open-source LLMs with comparable model sizes on Bird (53.39% EX / 59.02 VES) and strong results on Spider (79.60% EX / 77.19 VES), with especially significant gains on complex queries. Results highlight the effectiveness of combining self-enhancement, structured reasoning, and execution-time feedback within an LLM-based framework for text-to-SQL design.
Why Are DMD Students Lazy? Understanding the Copying Behavior in Few-Step Distillation
Jun 01, 2026Distribution Matching Distillation (DMD) compresses pretrained diffusion models into efficient few-step generators by aligning their noised distributions across all scales. In principle, such distribution-level supervision remains agnostic to specific noise-data pairings of the teacher; this provides the student the freedom to remap latent noise, a behavior consistently observed in low-dimensional settings. Surprisingly, we find that in high-dimensional settings, distilled students spontaneously reproduce the original noise-data pairings of the teacher, a phenomenon we term copying. We demonstrate that copying is neither a byproduct of adversarial objectives nor a result of teacher memorization. Instead, our evidence suggests that copying is an emergent property arising from the limited geometric freedom of the student model during high-dimensional distillation.
FLiP: Privacy-Preserving Federated Learning based on the Principle of Least Privileg
Oct 25, 2024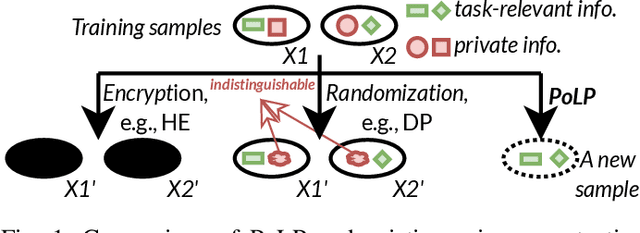
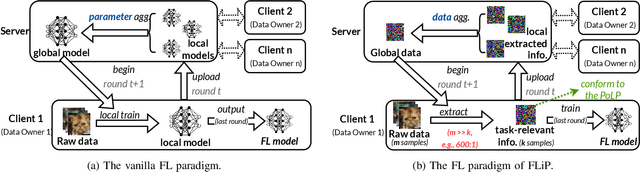
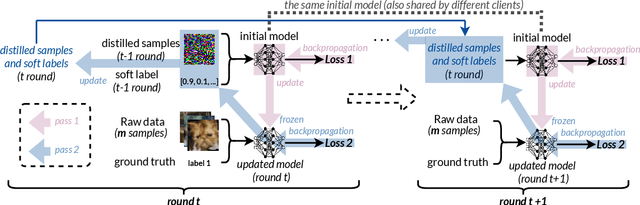

Federated Learning (FL) allows users to share knowledge instead of raw data to train a model with high accuracy. Unfortunately, during the training, users lose control over the knowledge shared, which causes serious data privacy issues. We hold that users are only willing and need to share the essential knowledge to the training task to obtain the FL model with high accuracy. However, existing efforts cannot help users minimize the shared knowledge according to the user intention in the FL training procedure. This work proposes FLiP, which aims to bring the principle of least privilege (PoLP) to FL training. The key design of FLiP is applying elaborate information reduction on the training data through a local-global dataset distillation design. We measure the privacy performance through attribute inference and membership inference attacks. Extensive experiments show that FLiP strikes a good balance between model accuracy and privacy protection.
CoAst: Validation-Free Contribution Assessment for Federated Learning based on Cross-Round Valuation
Sep 04, 2024



In the federated learning (FL) process, since the data held by each participant is different, it is necessary to figure out which participant has a higher contribution to the model performance. Effective contribution assessment can help motivate data owners to participate in the FL training. Research works in this field can be divided into two directions based on whether a validation dataset is required. Validation-based methods need to use representative validation data to measure the model accuracy, which is difficult to obtain in practical FL scenarios. Existing validation-free methods assess the contribution based on the parameters and gradients of local models and the global model in a single training round, which is easily compromised by the stochasticity of model training. In this work, we propose CoAst, a practical method to assess the FL participants' contribution without access to any validation data. The core idea of CoAst involves two aspects: one is to only count the most important part of model parameters through a weights quantization, and the other is a cross-round valuation based on the similarity between the current local parameters and the global parameter updates in several subsequent communication rounds. Extensive experiments show that CoAst has comparable assessment reliability to existing validation-based methods and outperforms existing validation-free methods.
Self-supervised Incremental Deep Graph Learning for Ethereum Phishing Scam Detection
Jun 18, 2021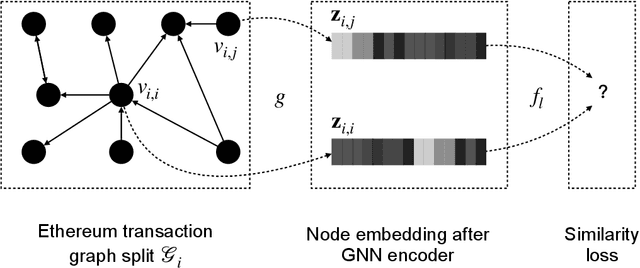

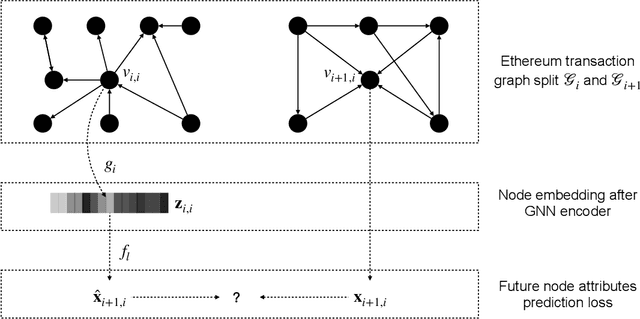
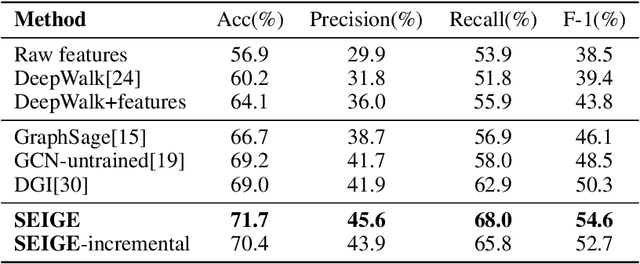
In recent years, phishing scams have become the crime type with the largest money involved on Ethereum, the second-largest blockchain platform. Meanwhile, graph neural network (GNN) has shown promising performance in various node classification tasks. However, for Ethereum transaction data, which could be naturally abstracted to a real-world complex graph, the scarcity of labels and the huge volume of transaction data make it difficult to take advantage of GNN methods. Here in this paper, to address the two challenges, we propose a Self-supervised Incremental deep Graph learning model (SIEGE), for the phishing scam detection problem on Ethereum. In our model, two pretext tasks designed from spatial and temporal perspectives help us effectively learn useful node embedding from the huge amount of unlabelled transaction data. And the incremental paradigm allows us to efficiently handle large-scale transaction data and help the model maintain good performance when the data distribution is drastically changing. We collect transaction records about half a year from Ethereum and our extensive experiments show that our model consistently outperforms strong baselines in both transductive and inductive settings.
Graph Neural Networks for Natural Language Processing: A Survey
Jun 10, 2021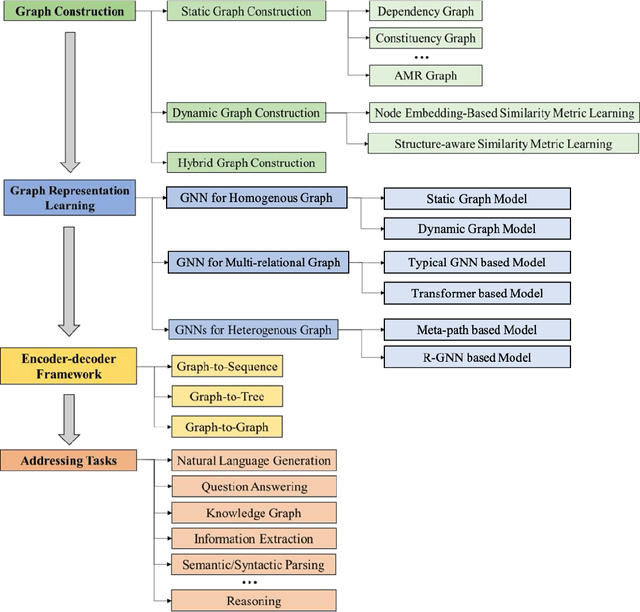
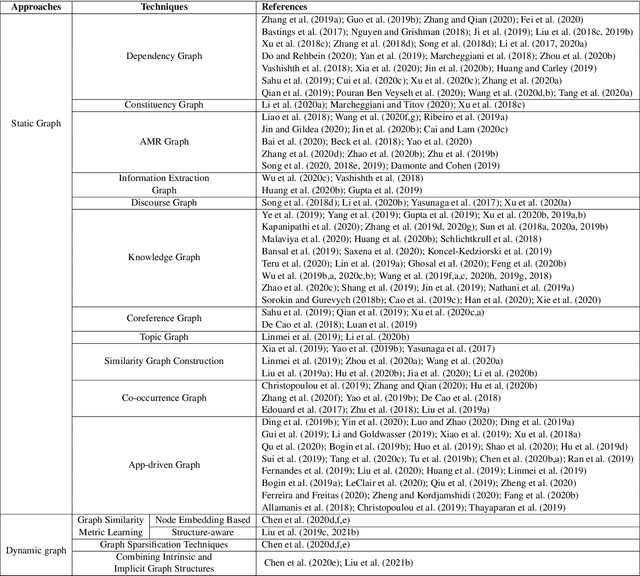
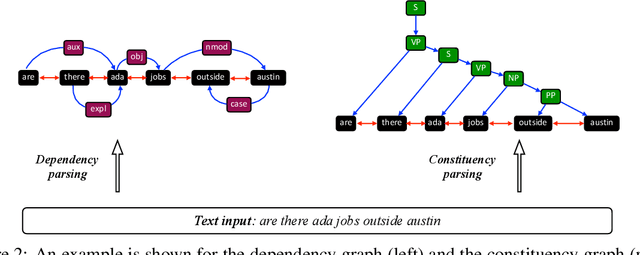

Deep learning has become the dominant approach in coping with various tasks in Natural LanguageProcessing (NLP). Although text inputs are typically represented as a sequence of tokens, there isa rich variety of NLP problems that can be best expressed with a graph structure. As a result, thereis a surge of interests in developing new deep learning techniques on graphs for a large numberof NLP tasks. In this survey, we present a comprehensive overview onGraph Neural Networks(GNNs) for Natural Language Processing. We propose a new taxonomy of GNNs for NLP, whichsystematically organizes existing research of GNNs for NLP along three axes: graph construction,graph representation learning, and graph based encoder-decoder models. We further introducea large number of NLP applications that are exploiting the power of GNNs and summarize thecorresponding benchmark datasets, evaluation metrics, and open-source codes. Finally, we discussvarious outstanding challenges for making the full use of GNNs for NLP as well as future researchdirections. To the best of our knowledge, this is the first comprehensive overview of Graph NeuralNetworks for Natural Language Processing.
Unsupervised Video Summarization with a Convolutional Attentive Adversarial Network
May 24, 2021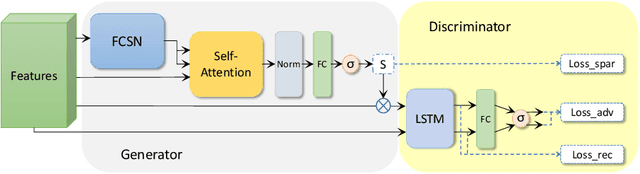
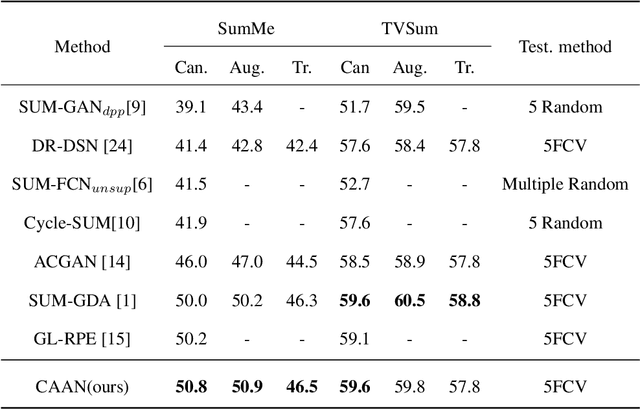
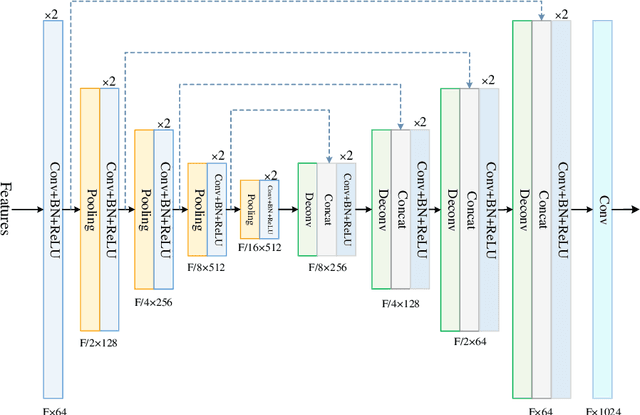
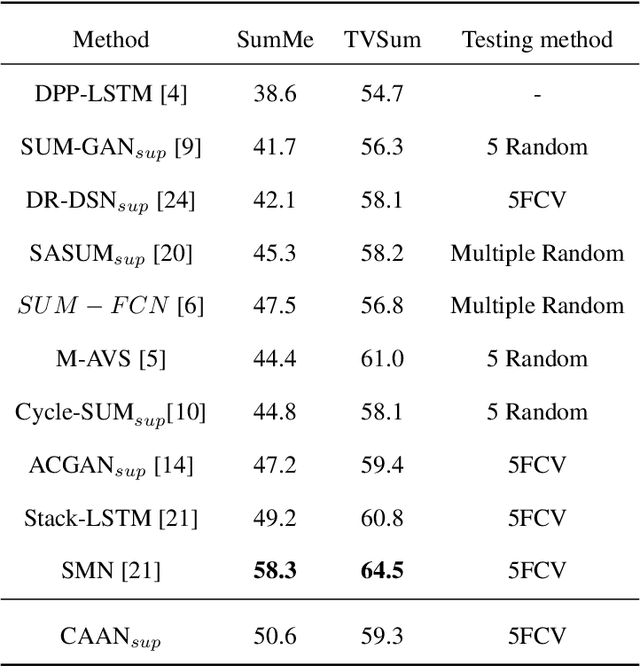
With the explosive growth of video data, video summarization, which attempts to seek the minimum subset of frames while still conveying the main story, has become one of the hottest topics. Nowadays, substantial achievements have been made by supervised learning techniques, especially after the emergence of deep learning. However, it is extremely expensive and difficult to collect human annotation for large-scale video datasets. To address this problem, we propose a convolutional attentive adversarial network (CAAN), whose key idea is to build a deep summarizer in an unsupervised way. Upon the generative adversarial network, our overall framework consists of a generator and a discriminator. The former predicts importance scores for all frames of a video while the latter tries to distinguish the score-weighted frame features from original frame features. Specifically, the generator employs a fully convolutional sequence network to extract global representation of a video, and an attention-based network to output normalized importance scores. To learn the parameters, our objective function is composed of three loss functions, which can guide the frame-level importance score prediction collaboratively. To validate this proposed method, we have conducted extensive experiments on two public benchmarks SumMe and TVSum. The results show the superiority of our proposed method against other state-of-the-art unsupervised approaches. Our method even outperforms some published supervised approaches.
Graph-to-Tree Neural Networks for Learning Structured Input-Output Translation with Applications to Semantic Parsing and Math Word Problem
Apr 07, 2020
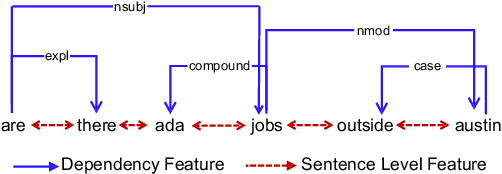
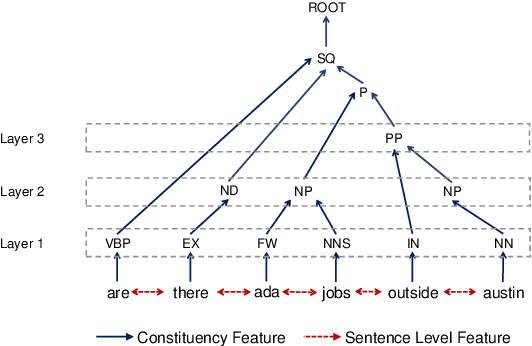
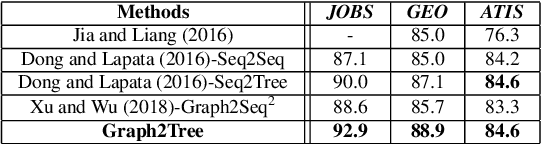
The celebrated Seq2Seq technique and its numerous variants achieve excellent performance on many tasks such as neural machine translation, semantic parsing, and math word problem solving. However, these models either only consider input objects as sequences while ignoring the important structural information for encoding, or they simply treat output objects as sequence outputs instead of structural objects for decoding. In this paper, we present a novel Graph-to-Tree Neural Networks, namely Graph2Tree consisting of a graph encoder and a hierarchical tree decoder, that encodes an augmented graph-structured input and decodes a tree-structured output. In particular, we investigated our model for solving two problems, neural semantic parsing and math word problem. Our extensive experiments demonstrate that our Graph2Tree model outperforms or matches the performance of other state-of-the-art models on these tasks.