 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Video Summarization with a Convolutional Attentive Adversarial Network
May 24, 2021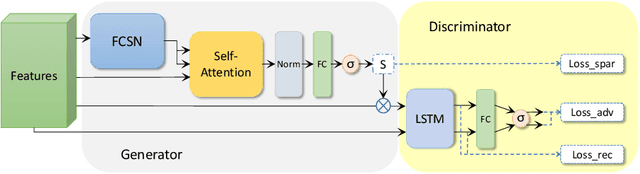
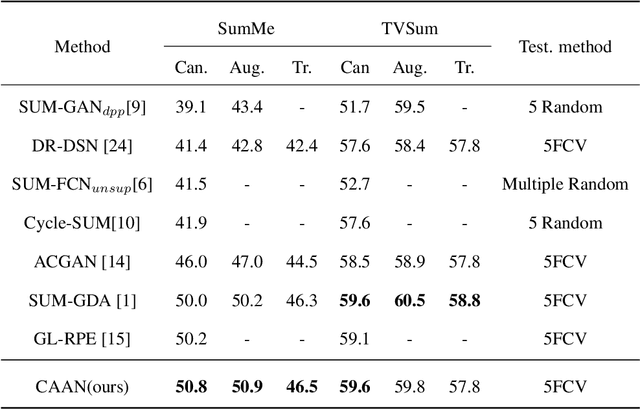
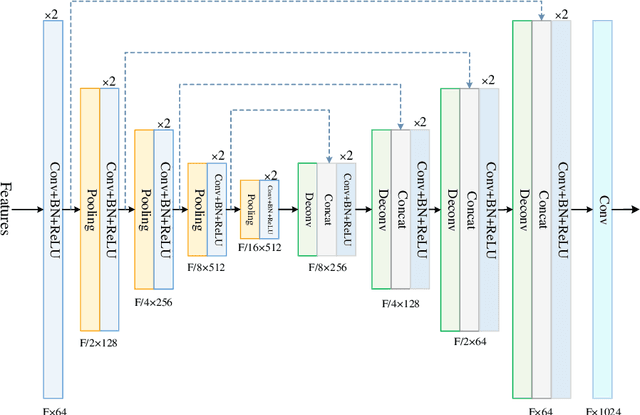
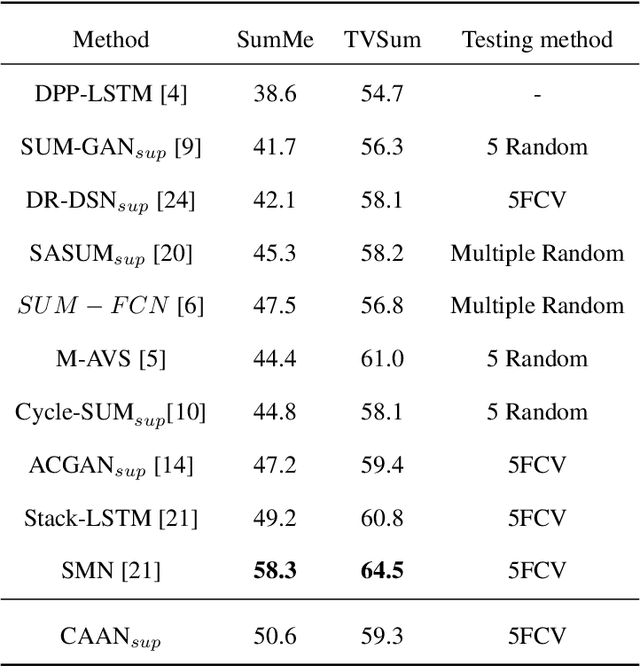
With the explosive growth of video data, video summarization, which attempts to seek the minimum subset of frames while still conveying the main story, has become one of the hottest topics. Nowadays, substantial achievements have been made by supervised learning techniques, especially after the emergence of deep learning. However, it is extremely expensive and difficult to collect human annotation for large-scale video datasets. To address this problem, we propose a convolutional attentive adversarial network (CAAN), whose key idea is to build a deep summarizer in an unsupervised way. Upon the generative adversarial network, our overall framework consists of a generator and a discriminator. The former predicts importance scores for all frames of a video while the latter tries to distinguish the score-weighted frame features from original frame features. Specifically, the generator employs a fully convolutional sequence network to extract global representation of a video, and an attention-based network to output normalized importance scores. To learn the parameters, our objective function is composed of three loss functions, which can guide the frame-level importance score prediction collaboratively. To validate this proposed method, we have conducted extensive experiments on two public benchmarks SumMe and TVSum. The results show the superiority of our proposed method against other state-of-the-art unsupervised approaches. Our method even outperforms some published supervised approaches.