 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSapling-NeRF: Geo-Localised Sapling Reconstruction in Forests for Ecological Monitoring
Feb 26, 2026Saplings are key indicators of forest regeneration and overall forest health. However, their fine-scale architectural traits are difficult to capture with existing 3D sensing methods, which make quantitative evaluation difficult. Terrestrial Laser Scanners (TLS), Mobile Laser Scanners (MLS), or traditional photogrammetry approaches poorly reconstruct thin branches, dense foliage, and lack the scale consistency needed for long-term monitoring. Implicit 3D reconstruction methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) are promising alternatives, but cannot recover the true scale of a scene and lack any means to be accurately geo-localised. In this paper, we present a pipeline which fuses NeRF, LiDAR SLAM, and GNSS to enable repeatable, geo-localised ecological monitoring of saplings. Our system proposes a three-level representation: (i) coarse Earth-frame localisation using GNSS, (ii) LiDAR-based SLAM for centimetre-accurate localisation and reconstruction, and (iii) NeRF-derived object-centric dense reconstruction of individual saplings. This approach enables repeatable quantitative evaluation and long-term monitoring of sapling traits. Our experiments in forest plots in Wytham Woods (Oxford, UK) and Evo (Finland) show that stem height, branching patterns, and leaf-to-wood ratios can be captured with increased accuracy as compared to TLS. We demonstrate that accurate stem skeletons and leaf distributions can be measured for saplings with heights between 0.5m and 2m in situ, giving ecologists access to richer structural and quantitative data for analysing forest dynamics.
The Oxford Spires Dataset: Benchmarking Large-Scale LiDAR-Visual Localisation, Reconstruction and Radiance Field Methods
Nov 15, 2024
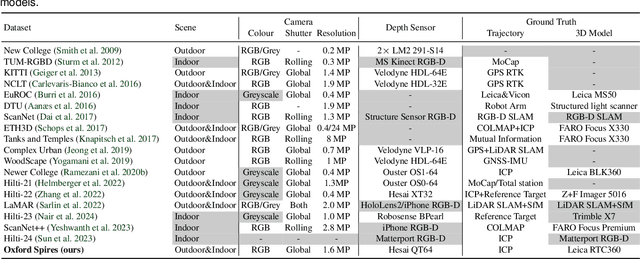
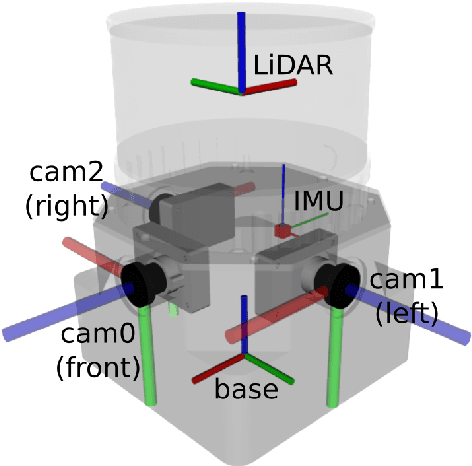
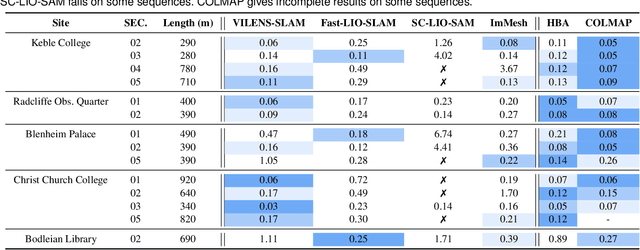
This paper introduces a large-scale multi-modal dataset captured in and around well-known landmarks in Oxford using a custom-built multi-sensor perception unit as well as a millimetre-accurate map from a Terrestrial LiDAR Scanner (TLS). The perception unit includes three synchronised global shutter colour cameras, an automotive 3D LiDAR scanner, and an inertial sensor - all precisely calibrated. We also establish benchmarks for tasks involving localisation, reconstruction, and novel-view synthesis, which enable the evaluation of Simultaneous Localisation and Mapping (SLAM) methods, Structure-from-Motion (SfM) and Multi-view Stereo (MVS) methods as well as radiance field methods such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting. To evaluate 3D reconstruction the TLS 3D models are used as ground truth. Localisation ground truth is computed by registering the mobile LiDAR scans to the TLS 3D models. Radiance field methods are evaluated not only with poses sampled from the input trajectory, but also from viewpoints that are from trajectories which are distant from the training poses. Our evaluation demonstrates a key limitation of state-of-the-art radiance field methods: we show that they tend to overfit to the training poses/images and do not generalise well to out-of-sequence poses. They also underperform in 3D reconstruction compared to MVS systems using the same visual inputs. Our dataset and benchmarks are intended to facilitate better integration of radiance field methods and SLAM systems. The raw and processed data, along with software for parsing and evaluation, can be accessed at https://dynamic.robots.ox.ac.uk/datasets/oxford-spires/.
LiLO: Lightweight and low-bias LiDAR Odometry method based on spherical range image filtering
Nov 13, 2023In unstructured outdoor environments, robotics requires accurate and efficient odometry with low computational time. Existing low-bias LiDAR odometry methods are often computationally expensive. To address this problem, we present a lightweight LiDAR odometry method that converts unorganized point cloud data into a spherical range image (SRI) and filters out surface, edge, and ground features in the image plane. This substantially reduces computation time and the required features for odometry estimation in LOAM-based algorithms. Our odometry estimation method does not rely on global maps or loop closure algorithms, which further reduces computational costs. Experimental results generate a translation and rotation error of 0.86\% and 0.0036{\deg}/m on the KITTI dataset with an average runtime of 78ms. In addition, we tested the method with our data, obtaining an average closed-loop error of 0.8m and a runtime of 27ms over eight loops covering 3.5Km.
Dynamically Weighted Factor-Graph for Feature-based Geo-localization
Nov 13, 2023Feature-based geo-localization relies on associating features extracted from aerial imagery with those detected by the vehicle's sensors. This requires that the type of landmarks must be observable from both sources. This no-variety of feature types generates poor representations that lead to outliers and deviations, produced by ambiguities and lack of detections respectively. To mitigate these drawbacks, in this paper, we present a dynamically weighted factor graph model for the vehicle's trajectory estimation. The weight adjustment in this implementation depends on information quantification in the detections performed using a LiDAR sensor. Also, a prior (GNSS-based) error estimation is included in the model. Then, when the representation becomes ambiguous or sparse, the weights are dynamically adjusted to rely on the corrected prior trajectory, mitigating in this way outliers and deviations. We compare our method against state-of-the-art geo-localization ones in a challenging ambiguous environment, where we also cause detection losses. We demonstrate mitigation of the mentioned drawbacks where the other methods fail.
ViKi-HyCo: A Hybrid-Control approach for complex car-like maneuvers
Nov 13, 2023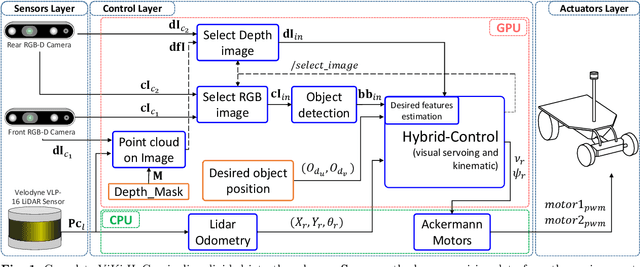


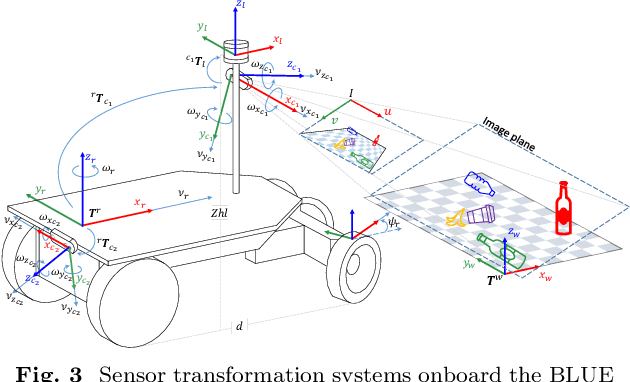
This paper presents ViKi-HyCo (Visual servoing and Kinematic Hybrid-Controller), an approach that generates the necessary maneuvers for the complex positioning of a non-holonomic mobile robot in outdoor environments, towards a target point based on the object detection, by combining an image based visual servoing (IBVS) and a kinematic controller. The method avoids the problems of the visual servoing controller when it loses the visual object detection features by switching to a kinematic controller. We also present object localization for outdoor environments employing the fusion of LiDAR and RGB-D cameras that estimates the spatial location of a target point for the kinematic controller, and also allows the dynamic calculation of a desired bounding box of the detected object for the calculation of velocities in the visual servoing controller. The presented approach does not require an object tracking algorithm and is applicable to any visually tracking robotic task where its kinematic model is known. The Hybrid-Control presents an error of 0.0428 \pm 0.0467 m in the X-axis and 0.0515 \pm 0.0323 m in the Y-axis at the end of a complete positioning task.
Robust Self-Tuning Data Association for Geo-Referencing Using Lane Markings
Jul 28, 2022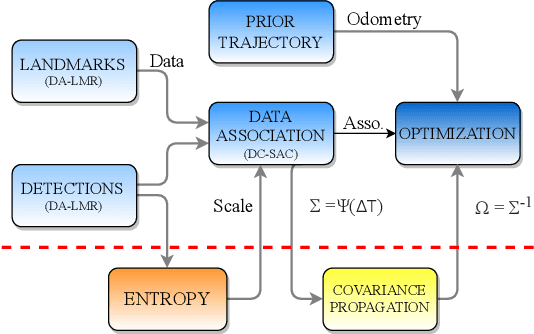
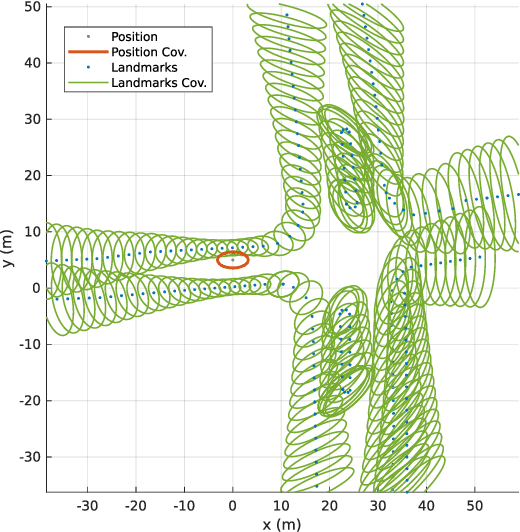
Localization in aerial imagery-based maps offers many advantages, such as global consistency, geo-referenced maps, and the availability of publicly accessible data. However, the landmarks that can be observed from both aerial imagery and on-board sensors is limited. This leads to ambiguities or aliasing during the data association. Building upon a highly informative representation (that allows efficient data association), this paper presents a complete pipeline for resolving these ambiguities. Its core is a robust self-tuning data association that adapts the search area depending on the entropy of the measurements. Additionally, to smooth the final result, we adjust the information matrix for the associated data as a function of the relative transform produced by the data association process. We evaluate our method on real data from urban and rural scenarios around the city of Karlsruhe in Germany. We compare state-of-the-art outlier mitigation methods with our self-tuning approach, demonstrating a considerable improvement, especially for outer-urban scenarios.
DA-LMR: A Robust Lane Markings Representation for Data Association Methods
Nov 17, 2021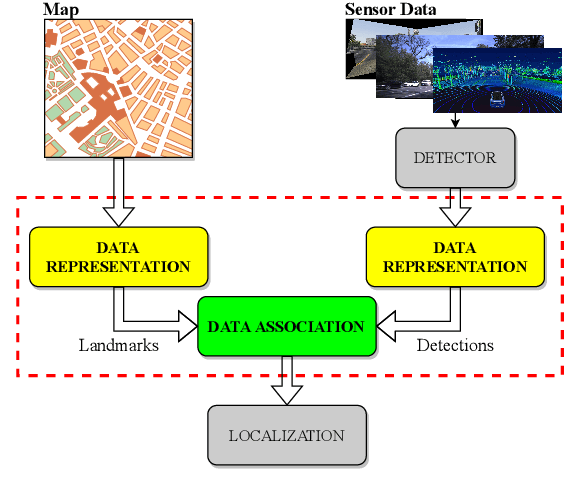
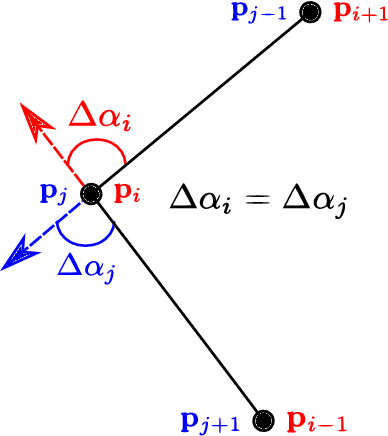

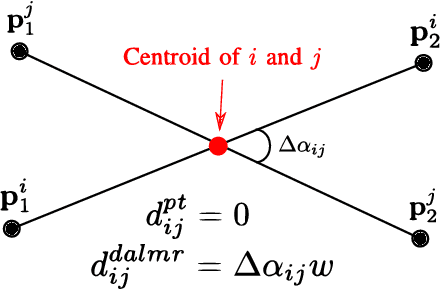
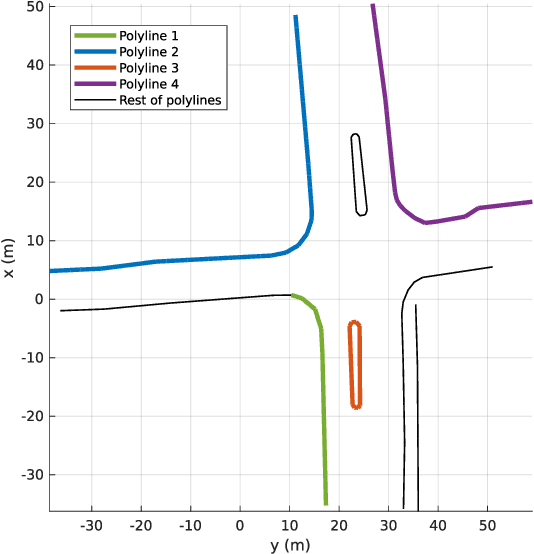
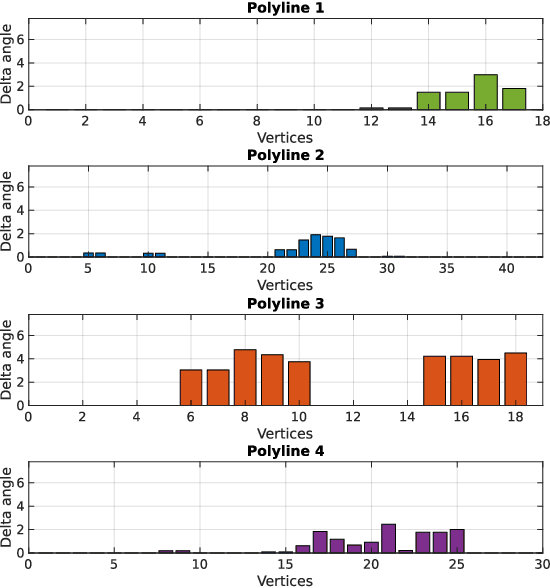
While complete localization approaches are widely studied in the literature, their data association and data representation subprocesses usually go unnoticed. However, both are a key part of the final pose estimation. In this work, we present DA-LMR (Delta-Angle Lane Markings Representation), a robust data representation in the context of localization approaches. We propose a representation of lane markings that encodes how a curve changes in each point and includes this information in an additional dimension, thus providing a more detailed geometric structure description of the data. We also propose DC-SAC (Distance-Compatible Sample Consensus), a data association method. This is a heuristic version of RANSAC that dramatically reduces the hypothesis space by distance compatibility restrictions. We compare the presented methods with some state-of-the-art data representation and data association approaches in different noisy scenarios. The DA-LMR and DC-SAC produce the most promising combination among those compared, reaching 98.1% in precision and 99.7% in recall for noisy data with 0.5m of standard deviation.