 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXD-MAP: Cross-Modal Domain Adaptation using Semantic Parametric Mapping
Jan 20, 2026Until open-world foundation models match the performance of specialized approaches, the effectiveness of deep learning models remains heavily dependent on dataset availability. Training data must align not only with the target object categories but also with the sensor characteristics and modalities. To bridge the gap between available datasets and deployment domains, domain adaptation strategies are widely used. In this work, we propose a novel approach to transferring sensor-specific knowledge from an image dataset to LiDAR, an entirely different sensing domain. Our method XD-MAP leverages detections from a neural network on camera images to create a semantic parametric map. The map elements are modeled to produce pseudo labels in the target domain without any manual annotation effort. Unlike previous domain transfer approaches, our method does not require direct overlap between sensors and enables extending the angular perception range from a front-view camera to a full 360 view. On our large-scale road feature dataset, XD-MAP outperforms single shot baseline approaches by +19.5 mIoU for 2D semantic segmentation, +19.5 PQth for 2D panoptic segmentation, and +32.3 mIoU in 3D semantic segmentation. The results demonstrate the effectiveness of our approach achieving strong performance on LiDAR data without any manual labeling.
SDTagNet: Leveraging Text-Annotated Navigation Maps for Online HD Map Construction
Jun 10, 2025Autonomous vehicles rely on detailed and accurate environmental information to operate safely. High definition (HD) maps offer a promising solution, but their high maintenance cost poses a significant barrier to scalable deployment. This challenge is addressed by online HD map construction methods, which generate local HD maps from live sensor data. However, these methods are inherently limited by the short perception range of onboard sensors. To overcome this limitation and improve general performance, recent approaches have explored the use of standard definition (SD) maps as prior, which are significantly easier to maintain. We propose SDTagNet, the first online HD map construction method that fully utilizes the information of widely available SD maps, like OpenStreetMap, to enhance far range detection accuracy. Our approach introduces two key innovations. First, in contrast to previous work, we incorporate not only polyline SD map data with manually selected classes, but additional semantic information in the form of textual annotations. In this way, we enrich SD vector map tokens with NLP-derived features, eliminating the dependency on predefined specifications or exhaustive class taxonomies. Second, we introduce a point-level SD map encoder together with orthogonal element identifiers to uniformly integrate all types of map elements. Experiments on Argoverse 2 and nuScenes show that this boosts map perception performance by up to +5.9 mAP (+45%) w.r.t. map construction without priors and up to +3.2 mAP (+20%) w.r.t. previous approaches that already use SD map priors. Code is available at https://github.com/immel-f/SDTagNet
Human-Aided Trajectory Planning for Automated Vehicles through Teleoperation and Arbitration Graphs
Feb 04, 2025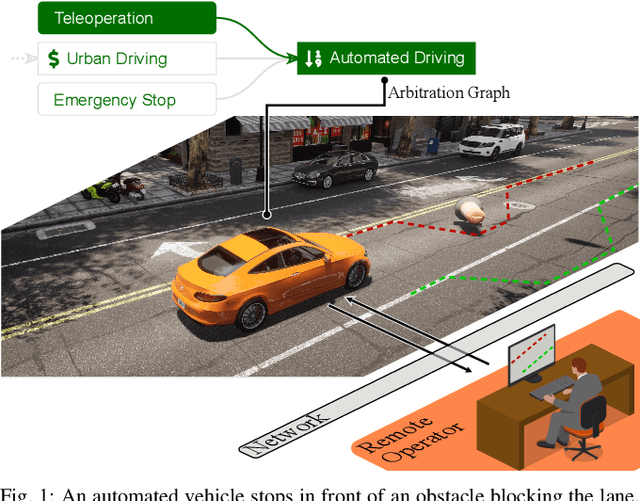


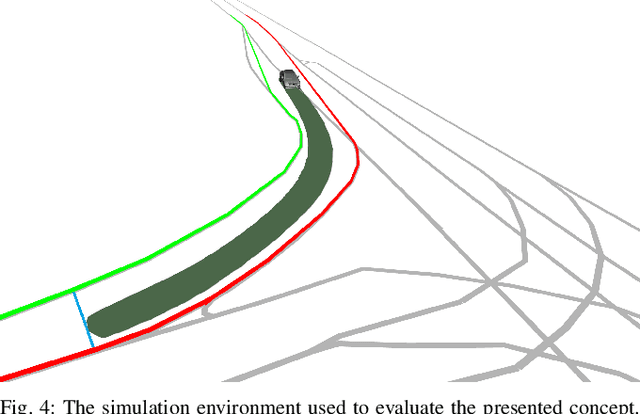
Teleoperation enables remote human support of automated vehicles in scenarios where the automation is not able to find an appropriate solution. Remote assistance concepts, where operators provide discrete inputs to aid specific automation modules like planning, is gaining interest due to its reduced workload on the human remote operator and improved safety. However, these concepts are challenging to implement and maintain due to their deep integration and interaction with the automated driving system. In this paper, we propose a solution to facilitate the implementation of remote assistance concepts that intervene on planning level and extend the operational design domain of the vehicle at runtime. Using arbitration graphs, a modular decision-making framework, we integrate remote assistance into an existing automated driving system without modifying the original software components. Our simulative implementation demonstrates this approach in two use cases, allowing operators to adjust planner constraints and enable trajectory generation beyond nominal operational design domains.
M3TR: Generalist HD Map Construction with Variable Map Priors
Nov 15, 2024Autonomous vehicles require road information for their operation, usually in form of HD maps. Since offline maps eventually become outdated or may only be partially available, online HD map construction methods have been proposed to infer map information from live sensor data. A key issue remains how to exploit such partial or outdated map information as a prior. We introduce M3TR (Multi-Masking Map Transformer), a generalist approach for HD map construction both with and without map priors. We address shortcomings in ground truth generation for Argoverse 2 and nuScenes and propose the first realistic scenarios with semantically diverse map priors. Examining various query designs, we use an improved method for integrating prior map elements into a HD map construction model, increasing performance by +4.3 mAP. Finally, we show that training across all prior scenarios yields a single Generalist model, whose performance is on par with previous Expert models that can handle only one specific type of map prior. M3TR thus is the first model capable of leveraging variable map priors, making it suitable for real-world deployment. Code is available at https://github.com/immel-f/m3tr
Robust Self-Tuning Data Association for Geo-Referencing Using Lane Markings
Jul 28, 2022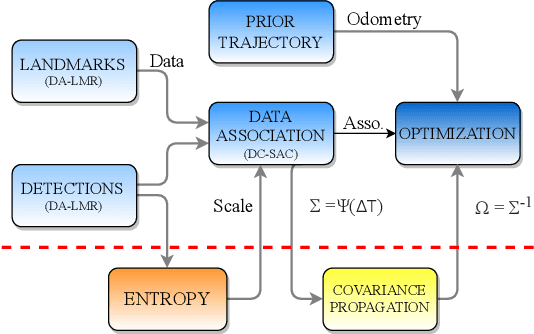
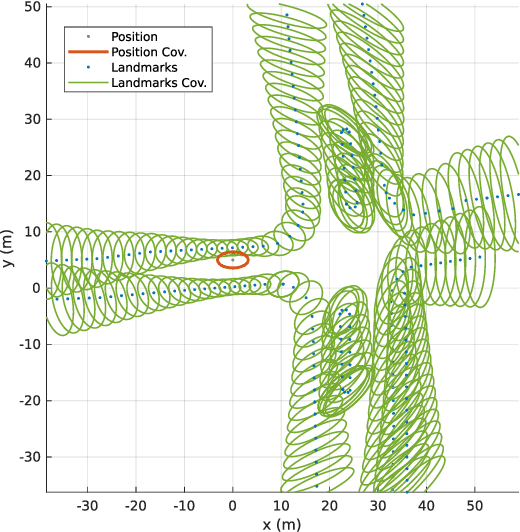
Localization in aerial imagery-based maps offers many advantages, such as global consistency, geo-referenced maps, and the availability of publicly accessible data. However, the landmarks that can be observed from both aerial imagery and on-board sensors is limited. This leads to ambiguities or aliasing during the data association. Building upon a highly informative representation (that allows efficient data association), this paper presents a complete pipeline for resolving these ambiguities. Its core is a robust self-tuning data association that adapts the search area depending on the entropy of the measurements. Additionally, to smooth the final result, we adjust the information matrix for the associated data as a function of the relative transform produced by the data association process. We evaluate our method on real data from urban and rural scenarios around the city of Karlsruhe in Germany. We compare state-of-the-art outlier mitigation methods with our self-tuning approach, demonstrating a considerable improvement, especially for outer-urban scenarios.
Large-Scale 3D Semantic Reconstruction for Automated Driving Vehicles with Adaptive Truncated Signed Distance Function
Feb 28, 2022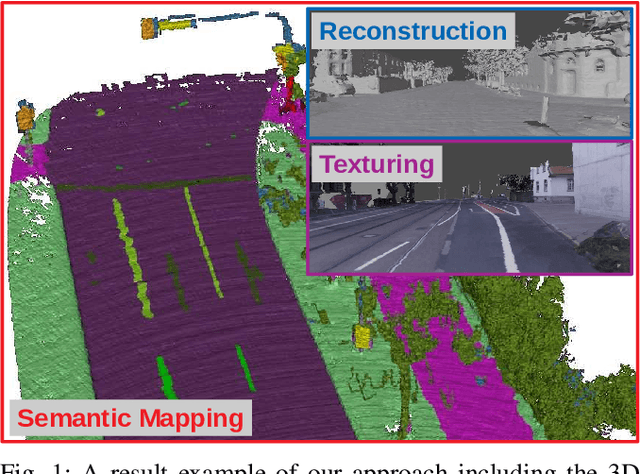

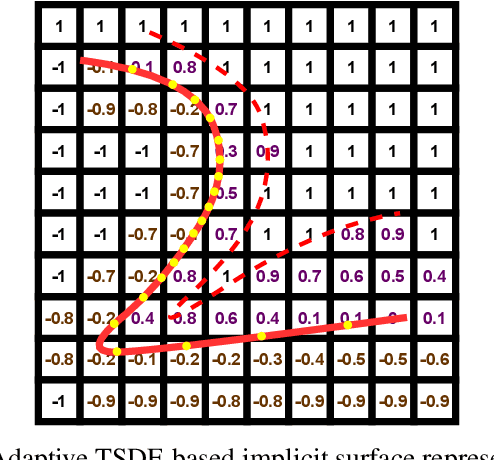

The Large-scale 3D reconstruction, texturing and semantic mapping are nowadays widely used for automated driving vehicles, virtual reality and automatic data generation. However, most approaches are developed for RGB-D cameras with colored dense point clouds and not suitable for large-scale outdoor environments using sparse LiDAR point clouds. Since a 3D surface can be usually observed from multiple camera images with different view poses, an optimal image patch selection for the texturing and an optimal semantic class estimation for the semantic mapping are still challenging. To address these problems, we propose a novel 3D reconstruction, texturing and semantic mapping system using LiDAR and camera sensors. An Adaptive Truncated Signed Distance Function is introduced to describe surfaces implicitly, which can deal with different LiDAR point sparsities and improve model quality. The from this implicit function extracted triangle mesh map is then textured from a series of registered camera images by applying an optimal image patch selection strategy. Besides that, a Markov Random Field-based data fusion approach is proposed to estimate the optimal semantic class for each triangle mesh. Our approach is evaluated on a synthetic dataset, the KITTI dataset and a dataset recorded with our experimental vehicle. The results show that the 3D models generated using our approach are more accurate in comparison to using other state-of-the-art approaches. The texturing and semantic mapping achieve also very promising results.
TEScalib: Targetless Extrinsic Self-Calibration of LiDAR and Stereo Camera for Automated Driving Vehicles with Uncertainty Analysis
Feb 28, 2022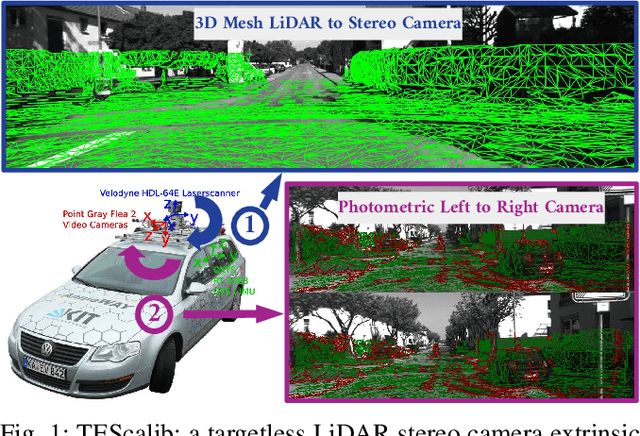
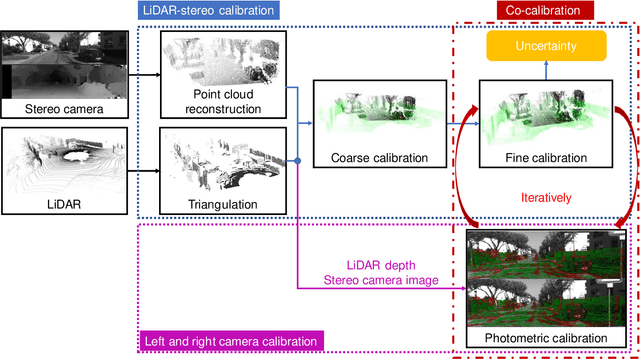
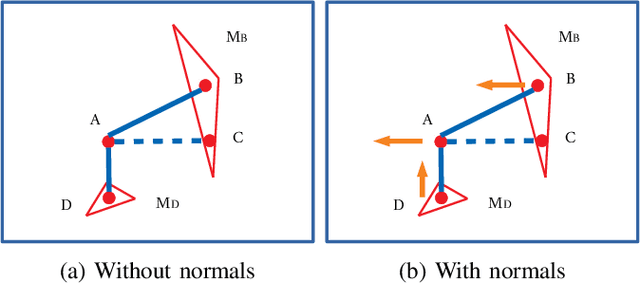
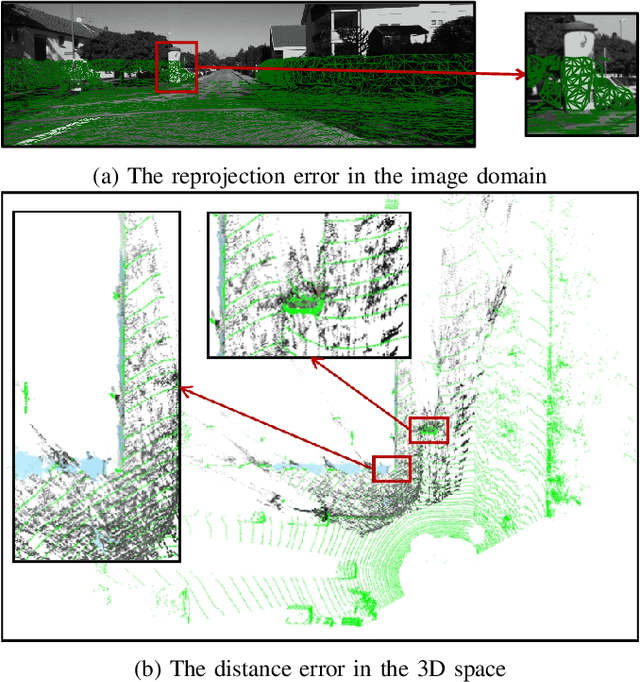
In this paper, we present TEScalib, a novel extrinsic self-calibration approach of LiDAR and stereo camera using the geometric and photometric information of surrounding environments without any calibration targets for automated driving vehicles. Since LiDAR and stereo camera are widely used for sensor data fusion on automated driving vehicles, their extrinsic calibration is highly important. However, most of the LiDAR and stereo camera calibration approaches are mainly target-based and therefore time consuming. Even the newly developed targetless approaches in last years are either inaccurate or unsuitable for driving platforms. To address those problems, we introduce TEScalib. By applying a 3D mesh reconstruction-based point cloud registration, the geometric information is used to estimate the LiDAR to stereo camera extrinsic parameters accurately and robustly. To calibrate the stereo camera, a photometric error function is builded and the LiDAR depth is involved to transform key points from one camera to another. During driving, these two parts are processed iteratively. Besides that, we also propose an uncertainty analysis for reflecting the reliability of the estimated extrinsic parameters. Our TEScalib approach evaluated on the KITTI dataset achieves very promising results.
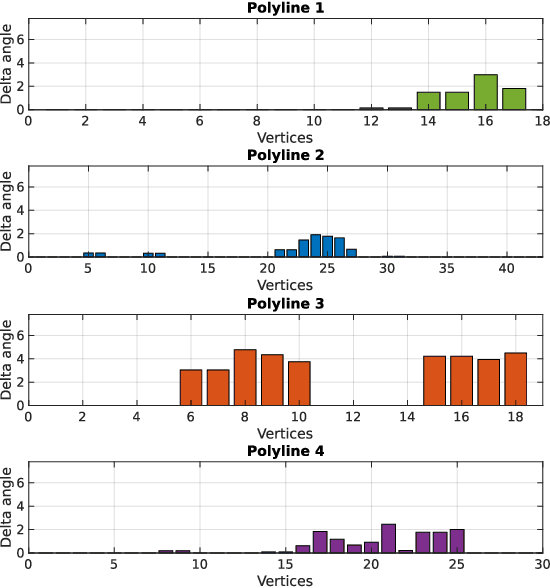
DA-LMR: A Robust Lane Markings Representation for Data Association Methods
Nov 17, 2021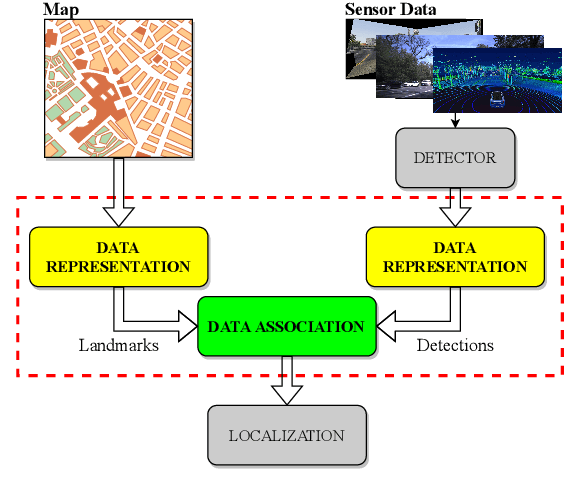
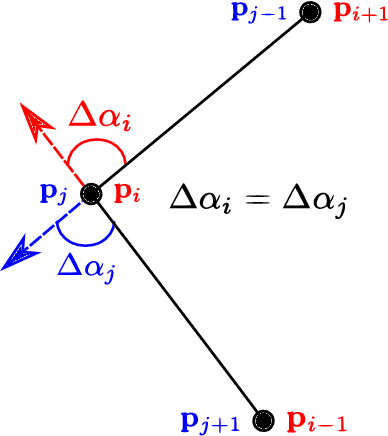

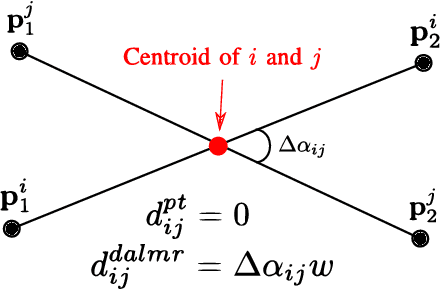
While complete localization approaches are widely studied in the literature, their data association and data representation subprocesses usually go unnoticed. However, both are a key part of the final pose estimation. In this work, we present DA-LMR (Delta-Angle Lane Markings Representation), a robust data representation in the context of localization approaches. We propose a representation of lane markings that encodes how a curve changes in each point and includes this information in an additional dimension, thus providing a more detailed geometric structure description of the data. We also propose DC-SAC (Distance-Compatible Sample Consensus), a data association method. This is a heuristic version of RANSAC that dramatically reduces the hypothesis space by distance compatibility restrictions. We compare the presented methods with some state-of-the-art data representation and data association approaches in different noisy scenarios. The DA-LMR and DC-SAC produce the most promising combination among those compared, reaching 98.1% in precision and 99.7% in recall for noisy data with 0.5m of standard deviation.
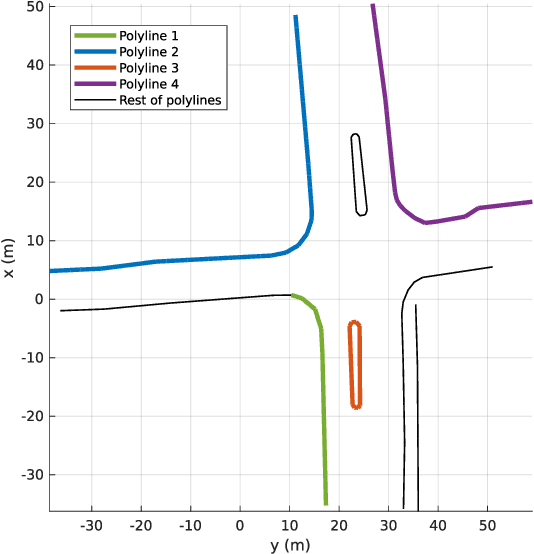
YOLinO: Generic Single Shot Polyline Detection in Real Time
Mar 26, 2021
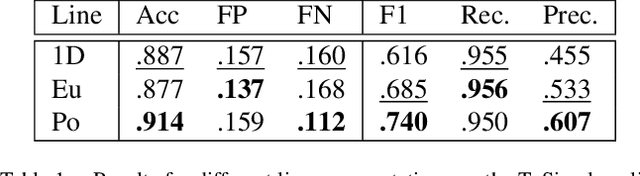
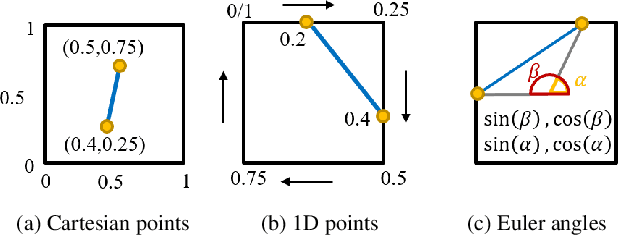
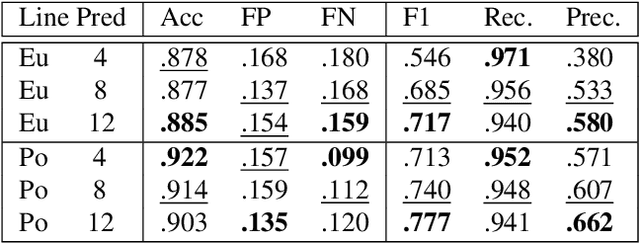
The detection of polylines in images is usually either bound to branchless polylines or formulated in a recurrent way, prohibiting their use in real-time systems. We propose an approach that transfers the idea of single shot object detection. Reformulating the problem of polyline detection as bottom-up composition of small line segments allows to detect bounded, dashed and continuous polylines with a single head. This has several major advantages over previous methods. Not only is the method at 187 fps more than suited for real-time applications with virtually any restriction on the shapes of the detected polylines. By predicting multiple line segments for each spatial cell, even branching or crossing polylines can be detected. We evaluate our approach on three different applications for road marking, lane border and center line detection. Hereby, we demonstrate the ability to generalize to different domains as well as both implicit and explicit polyline detection tasks.