 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale 3D Semantic Reconstruction for Automated Driving Vehicles with Adaptive Truncated Signed Distance Function
Paper and Code
Feb 28, 2022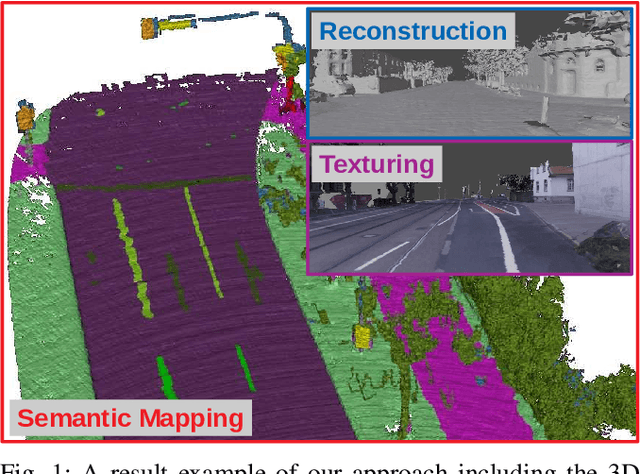

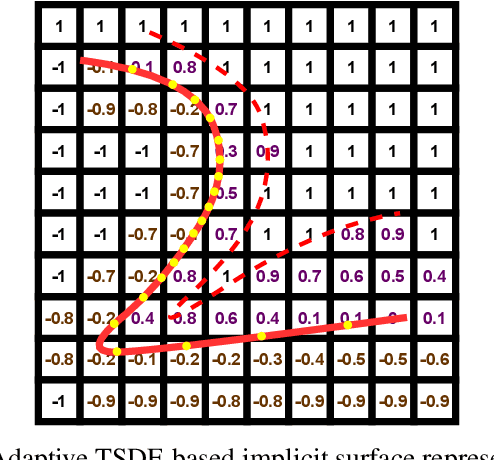

The Large-scale 3D reconstruction, texturing and semantic mapping are nowadays widely used for automated driving vehicles, virtual reality and automatic data generation. However, most approaches are developed for RGB-D cameras with colored dense point clouds and not suitable for large-scale outdoor environments using sparse LiDAR point clouds. Since a 3D surface can be usually observed from multiple camera images with different view poses, an optimal image patch selection for the texturing and an optimal semantic class estimation for the semantic mapping are still challenging. To address these problems, we propose a novel 3D reconstruction, texturing and semantic mapping system using LiDAR and camera sensors. An Adaptive Truncated Signed Distance Function is introduced to describe surfaces implicitly, which can deal with different LiDAR point sparsities and improve model quality. The from this implicit function extracted triangle mesh map is then textured from a series of registered camera images by applying an optimal image patch selection strategy. Besides that, a Markov Random Field-based data fusion approach is proposed to estimate the optimal semantic class for each triangle mesh. Our approach is evaluated on a synthetic dataset, the KITTI dataset and a dataset recorded with our experimental vehicle. The results show that the 3D models generated using our approach are more accurate in comparison to using other state-of-the-art approaches. The texturing and semantic mapping achieve also very promising results.