Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Prompt Array Keeps the Bias Away: Debiasing Vision-Language Models with Adversarial Learning
Apr 01, 2022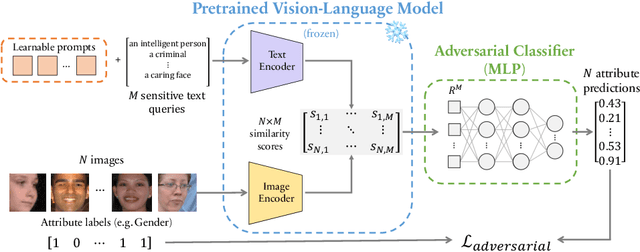

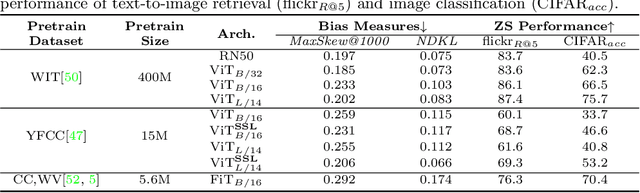

Vision-language models can encode societal biases and stereotypes, but there are challenges to measuring and mitigating these harms. Prior proposed bias measurements lack robustness and feature degradation occurs when mitigating bias without access to pretraining data. We address both of these challenges in this paper: First, we evaluate different bias measures and propose the use of retrieval metrics to image-text representations via a bias measuring framework. Second, we investigate debiasing methods and show that optimizing for adversarial loss via learnable token embeddings minimizes various bias measures without substantially degrading feature representations.
* 24 pages, 10 figures. For code and trained token embeddings, see
https://github.com/oxai/debias-vision-lang; Figure formatting and cropping
improved, corresponding author added, moved qualitative results from appendix
to results
Via