 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoving SLAM: Fully Unsupervised Deep Learning in Non-Rigid Scenes
Paper and Code
Jun 01, 2021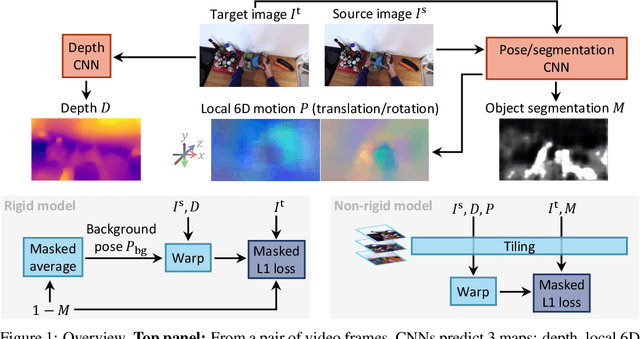
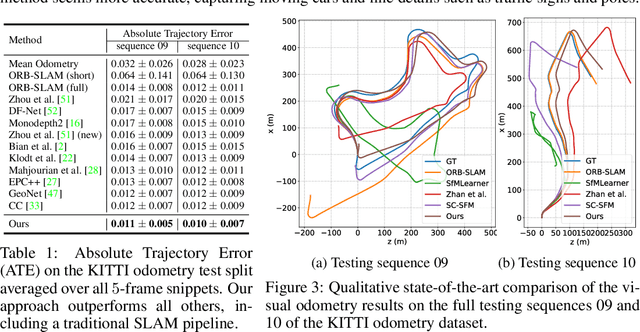
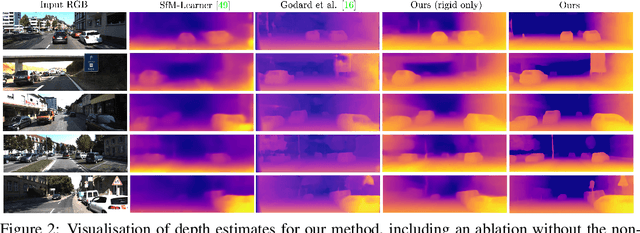
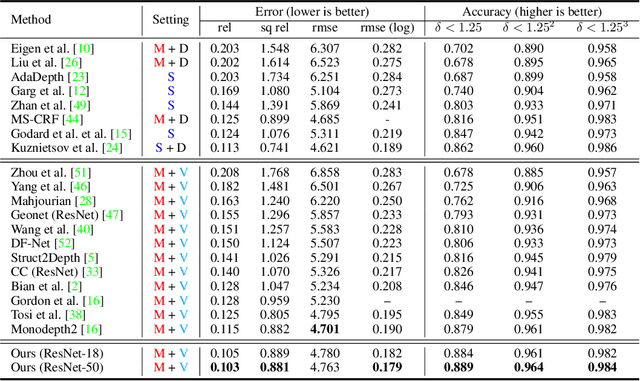
We propose a method to train deep networks to decompose videos into 3D geometry (camera and depth), moving objects, and their motions, with no supervision. We build on the idea of view synthesis, which uses classical camera geometry to re-render a source image from a different point-of-view, specified by a predicted relative pose and depth map. By minimizing the error between the synthetic image and the corresponding real image in a video, the deep network that predicts pose and depth can be trained completely unsupervised. However, the view synthesis equations rely on a strong assumption: that objects do not move. This rigid-world assumption limits the predictive power, and rules out learning about objects automatically. We propose a simple solution: minimize the error on small regions of the image instead. While the scene as a whole may be non-rigid, it is always possible to find small regions that are approximately rigid, such as inside a moving object. Our network can then predict different poses for each region, in a sliding window from a learned dense pose map. This represents a significantly richer model, including 6D object motions, with little additional complexity. We achieve very competitive performance on unsupervised odometry and depth prediction on KITTI. We also demonstrate new capabilities on EPIC-Kitchens, a challenging dataset of indoor videos, where there is no ground truth information for depth, odometry, object segmentation or motion. Yet all are recovered automatically by our method.