 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvably Adaptive Linear Approximation for the Shapley Value and Beyond
Apr 09, 2026The Shapley value, and its broader family of semi-values, has received much attention in various attribution problems. A fundamental and long-standing challenge is their efficient approximation, since exact computation generally requires an exponential number of utility queries in the number of players $n$. To meet the challenges of large-scale applications, we explore the limits of efficiently approximating semi-values under a $Θ(n)$ space constraint. Building upon a vector concentration inequality, we establish a theoretical framework that enables sharper query complexities for existing unbiased randomized algorithms. Within this framework, we systematically develop a linear-space algorithm that requires $O(\frac{n}{ε^{2}}\log\frac{1}δ)$ utility queries to ensure $P(\|\hat{\boldsymbolφ}-\boldsymbolφ\|_{2}\geqε)\leq δ$ for all commonly used semi-values. In particular, our framework naturally bridges OFA, unbiased kernelSHAP, SHAP-IQ and the regression-adjusted approach, and definitively characterizes when paired sampling is beneficial. Moreover, our algorithm allows explicit minimization of the mean square error for each specific utility function. Accordingly, we introduce the first adaptive, linear-time, linear-space randomized algorithm, Adalina, that theoretically achieves improved mean square error. All of our theoretical findings are experimentally validated.
TreeGrad-Ranker: Feature Ranking via $O(L)$-Time Gradients for Decision Trees
Feb 12, 2026We revisit the use of probabilistic values, which include the well-known Shapley and Banzhaf values, to rank features for explaining the local predicted values of decision trees. The quality of feature rankings is typically assessed with the insertion and deletion metrics. Empirically, we observe that co-optimizing these two metrics is closely related to a joint optimization that selects a subset of features to maximize the local predicted value while minimizing it for the complement. However, we theoretically show that probabilistic values are generally unreliable for solving this joint optimization. Therefore, we explore deriving feature rankings by directly optimizing the joint objective. As the backbone, we propose TreeGrad, which computes the gradients of the multilinear extension of the joint objective in $O(L)$ time for decision trees with $L$ leaves; these gradients include weighted Banzhaf values. Building upon TreeGrad, we introduce TreeGrad-Ranker, which aggregates the gradients while optimizing the joint objective to produce feature rankings, and TreeGrad-Shap, a numerically stable algorithm for computing Beta Shapley values with integral parameters. In particular, the feature scores computed by TreeGrad-Ranker satisfy all the axioms uniquely characterizing probabilistic values, except for linearity, which itself leads to the established unreliability. Empirically, we demonstrate that the numerical error of Linear TreeShap can be up to $10^{15}$ times larger than that of TreeGrad-Shap when computing the Shapley value. As a by-product, we also develop TreeProb, which generalizes Linear TreeShap to support all probabilistic values. In our experiments, TreeGrad-Ranker performs significantly better on both insertion and deletion metrics. Our code is available at https://github.com/watml/TreeGrad.
One Sample Fits All: Approximating All Probabilistic Values Simultaneously and Efficiently
Oct 31, 2024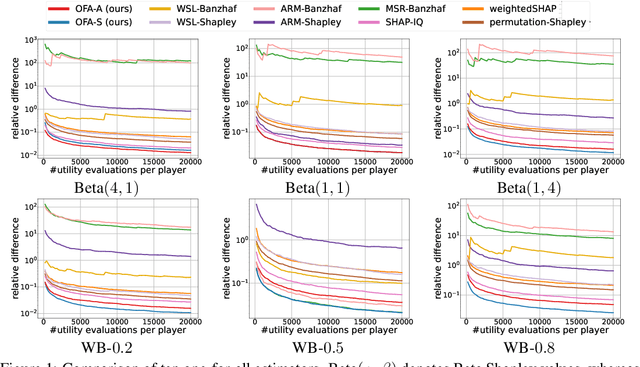

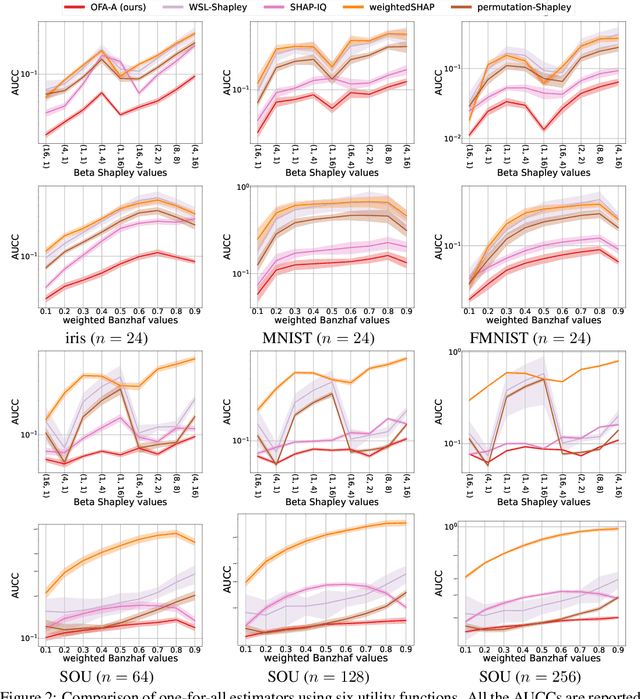
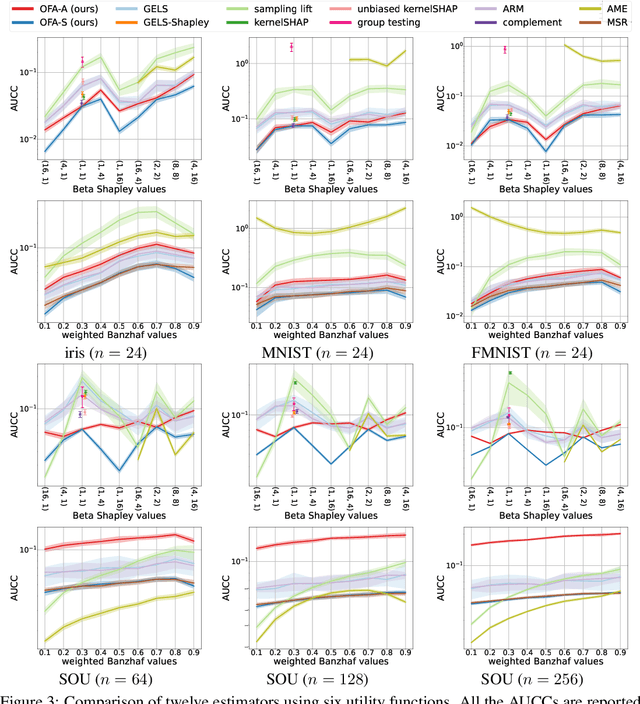
The concept of probabilistic values, such as Beta Shapley values and weighted Banzhaf values, has gained recent attention in applications like feature attribution and data valuation. However, exact computation of these values is often exponentially expensive, necessitating approximation techniques. Prior research has shown that the choice of probabilistic values significantly impacts downstream performance, with no universally superior option. Consequently, one may have to approximate multiple candidates and select the best-performing one. Although there have been many efforts to develop efficient estimators, none are intended to approximate all probabilistic values both simultaneously and efficiently. In this work, we embark on the first exploration of achieving this goal. Adhering to the principle of maximum sample reuse, we propose a one-sample-fits-all framework parameterized by a sampling vector to approximate intermediate terms that can be converted to any probabilistic value without amplifying scalars. Leveraging the concept of $ (\epsilon, \delta) $-approximation, we theoretically identify a key formula that effectively determines the convergence rate of our framework. By optimizing the sampling vector using this formula, we obtain i) a one-for-all estimator that achieves the currently best time complexity for all probabilistic values on average, and ii) a faster generic estimator with the sampling vector optimally tuned for each probabilistic value. Particularly, our one-for-all estimator achieves the fastest convergence rate on Beta Shapley values, including the well-known Shapley value, both theoretically and empirically. Finally, we establish a connection between probabilistic values and the least square regression used in (regularized) datamodels, showing that our one-for-all estimator can solve a family of datamodels simultaneously.
Scaling Value Iteration Networks to 5000 Layers for Extreme Long-Term Planning
Jun 12, 2024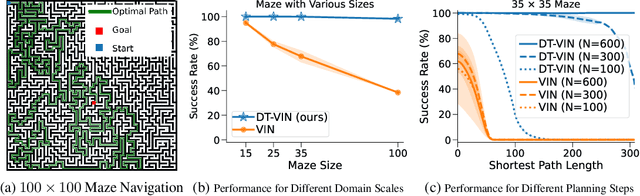

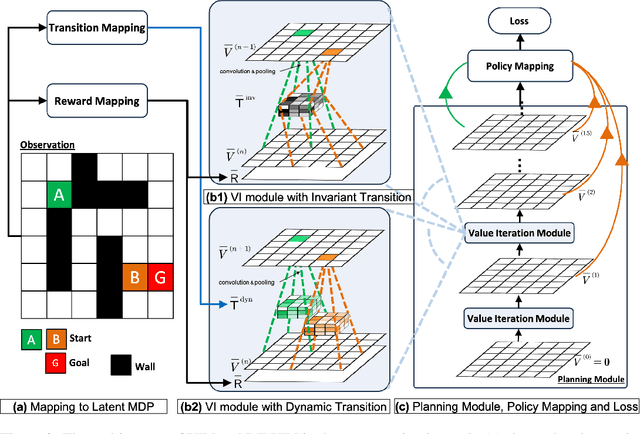

The Value Iteration Network (VIN) is an end-to-end differentiable architecture that performs value iteration on a latent MDP for planning in reinforcement learning (RL). However, VINs struggle to scale to long-term and large-scale planning tasks, such as navigating a $100\times 100$ maze -- a task which typically requires thousands of planning steps to solve. We observe that this deficiency is due to two issues: the representation capacity of the latent MDP and the planning module's depth. We address these by augmenting the latent MDP with a dynamic transition kernel, dramatically improving its representational capacity, and, to mitigate the vanishing gradient problem, introducing an "adaptive highway loss" that constructs skip connections to improve gradient flow. We evaluate our method on both 2D maze navigation environments and the ViZDoom 3D navigation benchmark. We find that our new method, named Dynamic Transition VIN (DT-VIN), easily scales to 5000 layers and casually solves challenging versions of the above tasks. Altogether, we believe that DT-VIN represents a concrete step forward in performing long-term large-scale planning in RL environments.
Highway Value Iteration Networks
Jun 05, 2024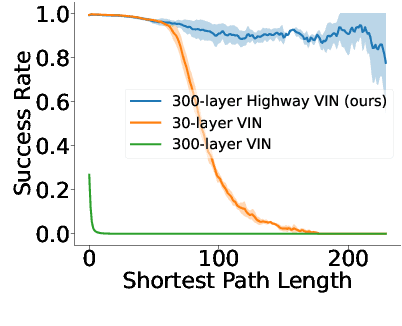



Value iteration networks (VINs) enable end-to-end learning for planning tasks by employing a differentiable "planning module" that approximates the value iteration algorithm. However, long-term planning remains a challenge because training very deep VINs is difficult. To address this problem, we embed highway value iteration -- a recent algorithm designed to facilitate long-term credit assignment -- into the structure of VINs. This improvement augments the "planning module" of the VIN with three additional components: 1) an "aggregate gate," which constructs skip connections to improve information flow across many layers; 2) an "exploration module," crafted to increase the diversity of information and gradient flow in spatial dimensions; 3) a "filter gate" designed to ensure safe exploration. The resulting novel highway VIN can be trained effectively with hundreds of layers using standard backpropagation. In long-term planning tasks requiring hundreds of planning steps, deep highway VINs outperform both traditional VINs and several advanced, very deep NNs.
Nyström Subspace Learning for Large-scale SVMs
Feb 20, 2020
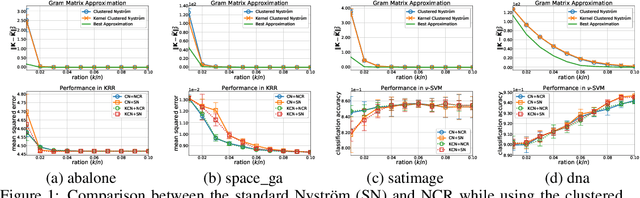
As an implementation of the Nystr\"{o}m method, Nystr\"{o}m computational regularization (NCR) imposed on kernel classification and kernel ridge regression has proven capable of achieving optimal bounds in the large-scale statistical learning setting, while enjoying much better time complexity. In this study, we propose a Nystr\"{o}m subspace learning (NSL) framework to reveal that all you need for employing the Nystr\"{o}m method, including NCR, upon any kernel SVM is to use the efficient off-the-shelf linear SVM solvers as a black box. Based on our analysis, the bounds developed for the Nystr\"{o}m method are linked to NSL, and the analytical difference between two distinct implementations of the Nystr\"{o}m method is clearly presented. Besides, NSL also leads to sharper theoretical results for the clustered Nystr\"{o}m method. Finally, both regression and classification tasks are performed to compare two implementations of the Nystr\"{o}m method.
A Graph-Based Decoding Model for Incomplete Multi-Subject fMRI Functional Alignment
May 28, 2019
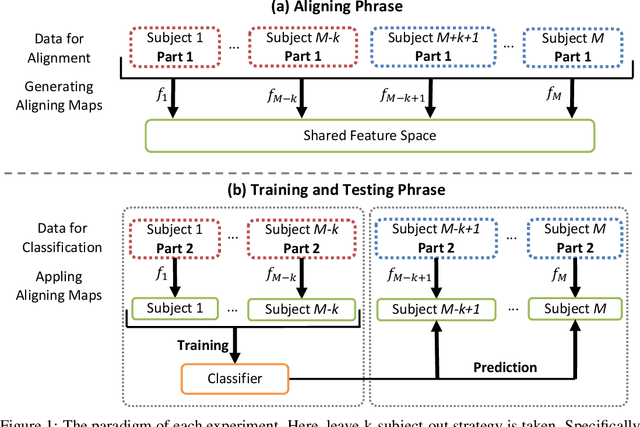
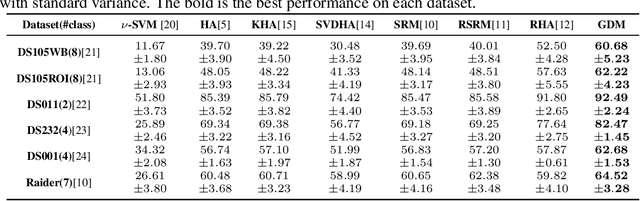
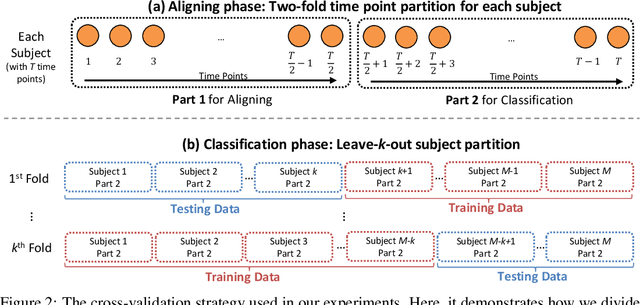
Aggregating multi-subject fMRI data is indispensable for generating valid and general inferences from patterns distributed across human brains. The disparities in anatomical structures and functional topographies of human brains call for aligning fMRI data across subjects. However, the existing functional alignment methods cannot tackle various kinds of fMRI datasets today, especially when they are incomplete, i.e., some of the subjects probably lack the responses to some stimuli, or different subjects might follow different sequences of stimuli. In this paper, a cross-subject graph that depicts the (dis)similarities between samples across subjects is taken as prior information for developing a more flexible framework that suits an assortment of fMRI datasets. However, the high dimension of fMRI data and the use of multiple subjects makes the crude framework time-consuming or unpractical. Therefore, we regularize the framework so that a feasible kernel-based optimization, which permits non-linear feature extraction, could be theoretically developed. Specifically, a low-dimension assumption is imposed on each new feature space to avoid overfitting caused by the high-spatial-low-temporal resolution of fMRI data. Empirical studies confirm that the proposed method under both incompleteness and completeness can achieve better performance than other state-of-the-art functional alignment methods under completeness.