 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Clustering: New Bounds and Objective
Nov 12, 2021Hierarchical Clustering has been studied and used extensively as a method for analysis of data. More recently, Dasgupta [2016] defined a precise objective function. Given a set of $n$ data points with a weight function $w_{i,j}$ for each two items $i$ and $j$ denoting their similarity/dis-similarity, the goal is to build a recursive (tree like) partitioning of the data points (items) into successively smaller clusters. He defined a cost function for a tree $T$ to be $Cost(T) = \sum_{i,j \in [n]} \big(w_{i,j} \times |T_{i,j}| \big)$ where $T_{i,j}$ is the subtree rooted at the least common ancestor of $i$ and $j$ and presented the first approximation algorithm for such clustering. Then Moseley and Wang [2017] considered the dual of Dasgupta's objective function for similarity-based weights and showed that both random partitioning and average linkage have approximation ratio $1/3$ which has been improved in a series of works to $0.585$ [Alon et al. 2020]. Later Cohen-Addad et al. [2019] considered the same objective function as Dasgupta's but for dissimilarity-based metrics, called $Rev(T)$. It is shown that both random partitioning and average linkage have ratio $2/3$ which has been only slightly improved to $0.667078$ [Charikar et al. SODA2020]. Our first main result is to consider $Rev(T)$ and present a more delicate algorithm and careful analysis that achieves approximation $0.71604$. We also introduce a new objective function for dissimilarity-based clustering. For any tree $T$, let $H_{i,j}$ be the number of $i$ and $j$'s common ancestors. Intuitively, items that are similar are expected to remain within the same cluster as deep as possible. So, for dissimilarity-based metrics, we suggest the cost of each tree $T$, which we want to minimize, to be $Cost_H(T) = \sum_{i,j \in [n]} \big(w_{i,j} \times H_{i,j} \big)$. We present a $1.3977$-approximation for this objective.
Local Search Yields a PTAS for k-Means in Doubling Metrics
Jan 09, 2017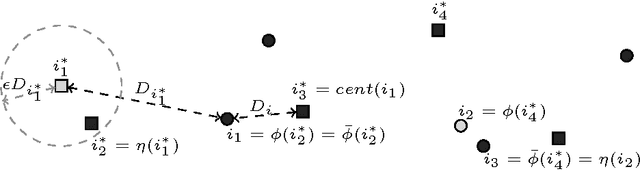



The most well known and ubiquitous clustering problem encountered in nearly every branch of science is undoubtedly $k$-means: given a set of data points and a parameter $k$, select $k$ centres and partition the data points into $k$ clusters around these centres so that the sum of squares of distances of the points to their cluster centre is minimized. Typically these data points lie $\mathbb{R}^d$ for some $d\geq 2$. $k$-means and the first algorithms for it were introduced in the 1950's. Since then, hundreds of papers have studied this problem and many algorithms have been proposed for it. The most commonly used algorithm is known as Lloyd-Forgy, which is also referred to as "the" $k$-means algorithm, and various extensions of it often work very well in practice. However, they may produce solutions whose cost is arbitrarily large compared to the optimum solution. Kanungo et al. [2004] analyzed a simple local search heuristic to get a polynomial-time algorithm with approximation ratio $9+\epsilon$ for any fixed $\epsilon>0$ for $k$-means in Euclidean space. Finding an algorithm with a better approximation guarantee has remained one of the biggest open questions in this area, in particular whether one can get a true PTAS for fixed dimension Euclidean space. We settle this problem by showing that a simple local search algorithm provides a PTAS for $k$-means in $\mathbb{R}^d$ for any fixed $d$. More precisely, for any error parameter $\epsilon>0$, the local search algorithm that considers swaps of up to $\rho=d^{O(d)}\cdot{\epsilon}^{-O(d/\epsilon)}$ centres at a time finds a solution using exactly $k$ centres whose cost is at most a $(1+\epsilon)$-factor greater than the optimum. Finally, we provide the first demonstration that local search yields a PTAS for the uncapacitated facility location problem and $k$-median with non-uniform opening costs in doubling metrics.