 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal-Conditioned Generators of Deep Policies
Paper and Code
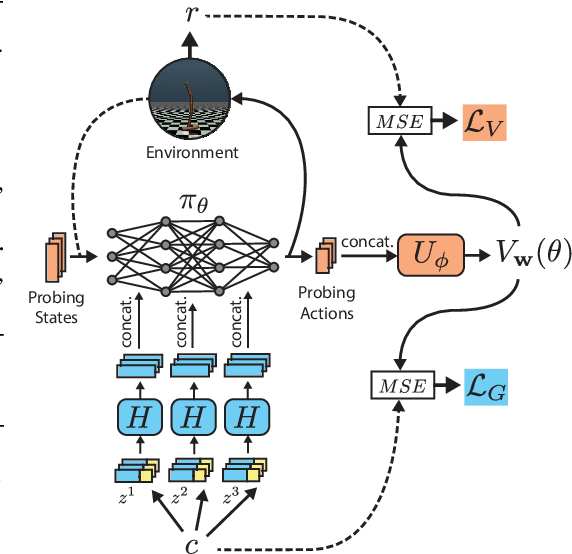

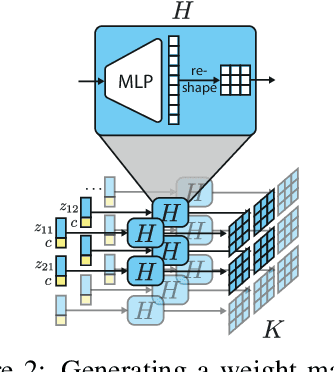
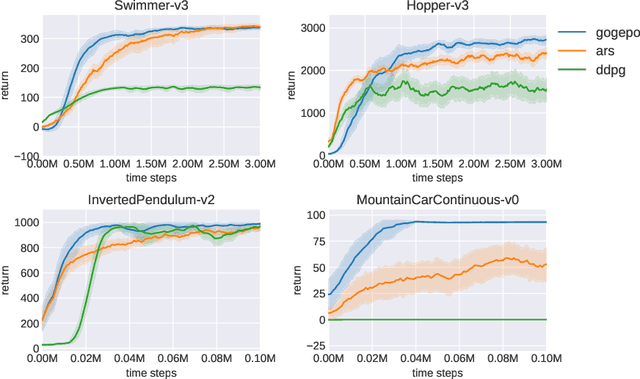
Goal-conditioned Reinforcement Learning (RL) aims at learning optimal policies, given goals encoded in special command inputs. Here we study goal-conditioned neural nets (NNs) that learn to generate deep NN policies in form of context-specific weight matrices, similar to Fast Weight Programmers and other methods from the 1990s. Using context commands of the form "generate a policy that achieves a desired expected return," our NN generators combine powerful exploration of parameter space with generalization across commands to iteratively find better and better policies. A form of weight-sharing HyperNetworks and policy embeddings scales our method to generate deep NNs. Experiments show how a single learned policy generator can produce policies that achieve any return seen during training. Finally, we evaluate our algorithm on a set of continuous control tasks where it exhibits competitive performance. Our code is public.