 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Deep Learning Meets Data Alignment: A Review on Deep Registration Networks
Mar 06, 2020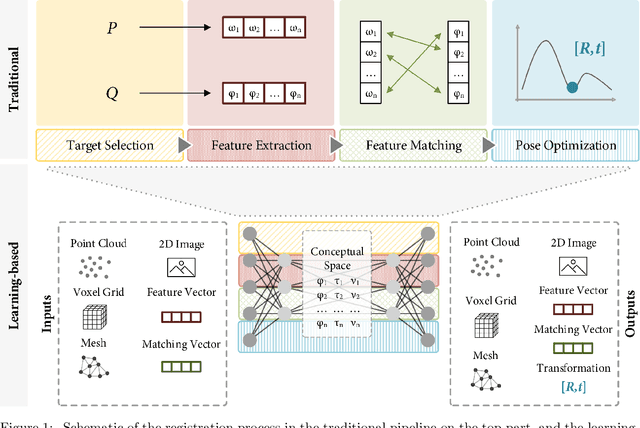

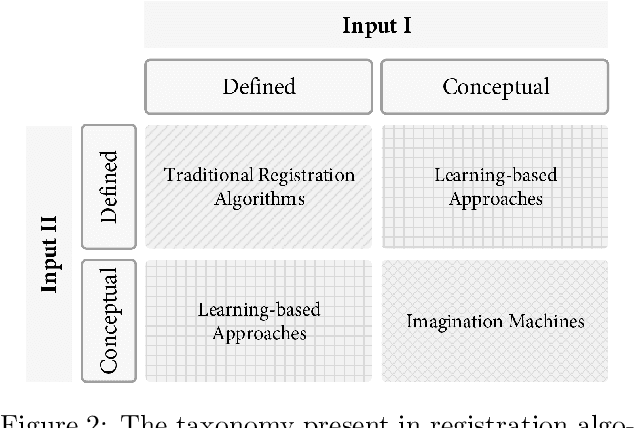

Registration is the process that computes the transformation that aligns sets of data. Commonly, a registration process can be divided into four main steps: target selection, feature extraction, feature matching, and transform computation for the alignment. The accuracy of the result depends on multiple factors, the most significant are the quantity of input data, the presence of noise, outliers and occlusions, the quality of the extracted features, real-time requirements and the type of transformation, especially those ones defined by multiple parameters, like non-rigid deformations. Recent advancements in machine learning could be a turning point in these issues, particularly with the development of deep learning (DL) techniques, which are helping to improve multiple computer vision problems through an abstract understanding of the input data. In this paper, a review of deep learning-based registration methods is presented. We classify the different papers proposing a framework extracted from the traditional registration pipeline to analyse the new learning-based proposal strengths. Deep Registration Networks (DRNs) try to solve the alignment task either replacing part of the traditional pipeline with a network or fully solving the registration problem. The main conclusions extracted are, on the one hand, 1) learning-based registration techniques cannot always be clearly classified in the traditional pipeline. 2) These approaches allow more complex inputs like conceptual models as well as the traditional 3D datasets. 3) In spite of the generality of learning, the current proposals are still ad hoc solutions. Finally, 4) this is a young topic that still requires a large effort to reach general solutions able to cope with the problems that affect traditional approaches.
3D non-rigid registration using color: Color Coherent Point Drift
Feb 05, 2018



Research into object deformations using computer vision techniques has been under intense study in recent years. A widely used technique is 3D non-rigid registration to estimate the transformation between two instances of a deforming structure. Despite many previous developments on this topic, it remains a challenging problem. In this paper we propose a novel approach to non-rigid registration combining two data spaces in order to robustly calculate the correspondences and transformation between two data sets. In particular, we use point color as well as 3D location as these are the common outputs of RGB-D cameras. We have propose the Color Coherent Point Drift (CCPD) algorithm (an extension of the CPD method [1]). Evaluation is performed using synthetic and real data. The synthetic data includes easy shapes that allow evaluation of the effect of noise, outliers and missing data. Moreover, an evaluation of realistic figures obtained using Blensor is carried out. Real data acquired using a general purpose Primesense Carmine sensor is used to validate the CCPD for real shapes. For all tests, the proposed method is compared to the original CPD showing better results in registration accuracy in most cases.
A Review on Deep Learning Techniques Applied to Semantic Segmentation
Apr 22, 2017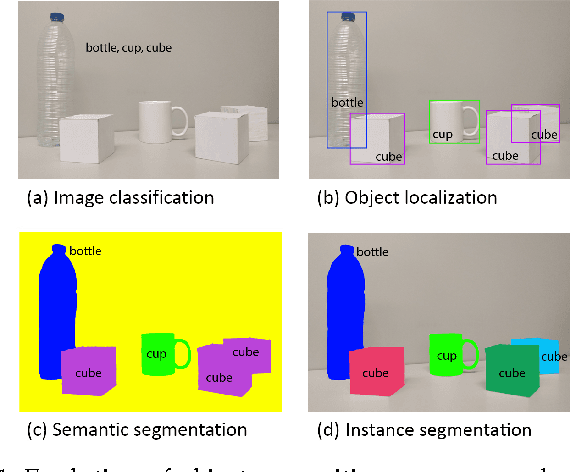
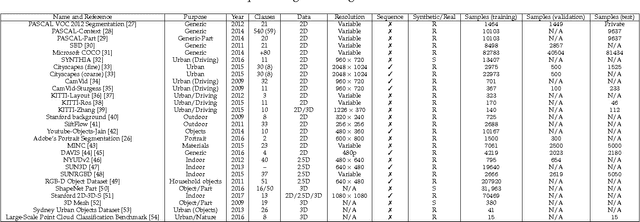
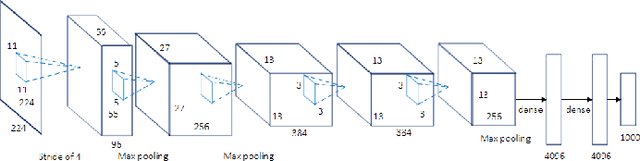
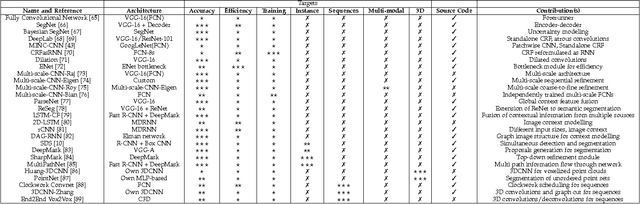
Image semantic segmentation is more and more being of interest for computer vision and machine learning researchers. Many applications on the rise need accurate and efficient segmentation mechanisms: autonomous driving, indoor navigation, and even virtual or augmented reality systems to name a few. This demand coincides with the rise of deep learning approaches in almost every field or application target related to computer vision, including semantic segmentation or scene understanding. This paper provides a review on deep learning methods for semantic segmentation applied to various application areas. Firstly, we describe the terminology of this field as well as mandatory background concepts. Next, the main datasets and challenges are exposed to help researchers decide which are the ones that best suit their needs and their targets. Then, existing methods are reviewed, highlighting their contributions and their significance in the field. Finally, quantitative results are given for the described methods and the datasets in which they were evaluated, following up with a discussion of the results. At last, we point out a set of promising future works and draw our own conclusions about the state of the art of semantic segmentation using deep learning techniques.