 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Concept Bottleneck Models
Jun 27, 2024



Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
Beyond Concept Bottleneck Models: How to Make Black Boxes Intervenable?
Jan 24, 2024Recently, interpretable machine learning has re-explored concept bottleneck models (CBM), comprising step-by-step prediction of the high-level concepts from the raw features and the target variable from the predicted concepts. A compelling advantage of this model class is the user's ability to intervene on the predicted concept values, affecting the model's downstream output. In this work, we introduce a method to perform such concept-based interventions on already-trained neural networks, which are not interpretable by design, given an annotated validation set. Furthermore, we formalise the model's intervenability as a measure of the effectiveness of concept-based interventions and leverage this definition to fine-tune black-box models. Empirically, we explore the intervenability of black-box classifiers on synthetic tabular and natural image benchmarks. We demonstrate that fine-tuning improves intervention effectiveness and often yields better-calibrated predictions. To showcase the practical utility of the proposed techniques, we apply them to deep chest X-ray classifiers and show that fine-tuned black boxes can be as intervenable and more performant than CBMs.
Signal Is Harder To Learn Than Bias: Debiasing with Focal Loss
May 31, 2023Spurious correlations are everywhere. While humans often do not perceive them, neural networks are notorious for learning unwanted associations, also known as biases, instead of the underlying decision rule. As a result, practitioners are often unaware of the biased decision-making of their classifiers. Such a biased model based on spurious correlations might not generalize to unobserved data, leading to unintended, adverse consequences. We propose Signal is Harder (SiH), a variational-autoencoder-based method that simultaneously trains a biased and unbiased classifier using a novel, disentangling reweighting scheme inspired by the focal loss. Using the unbiased classifier, SiH matches or improves upon the performance of state-of-the-art debiasing methods. To improve the interpretability of our technique, we propose a perturbation scheme in the latent space for visualizing the bias that helps practitioners become aware of the sources of spurious correlations.
Interpretable and Intervenable Ultrasonography-based Machine Learning Models for Pediatric Appendicitis
Feb 28, 2023Appendicitis is among the most frequent reasons for pediatric abdominal surgeries. With recent advances in machine learning, data-driven decision support could help clinicians diagnose and manage patients while reducing the number of non-critical surgeries. Previous decision support systems for appendicitis focused on clinical, laboratory, scoring and computed tomography data, mainly ignoring abdominal ultrasound, a noninvasive and readily available diagnostic modality. To this end, we developed and validated interpretable machine learning models for predicting the diagnosis, management and severity of suspected appendicitis using ultrasound images. Our models were trained on a dataset comprising 579 pediatric patients with 1709 ultrasound images accompanied by clinical and laboratory data. Our methodological contribution is the generalization of concept bottleneck models to prediction problems with multiple views and incomplete concept sets. Notably, such models lend themselves to interpretation and interaction via high-level concepts understandable to clinicians without sacrificing performance or requiring time-consuming image annotation when deployed.
Introduction to Machine Learning for Physicians: A Survival Guide for Data Deluge
Dec 23, 2022
Many modern research fields increasingly rely on collecting and analysing massive, often unstructured, and unwieldy datasets. Consequently, there is growing interest in machine learning and artificial intelligence applications that can harness this `data deluge'. This broad nontechnical overview provides a gentle introduction to machine learning with a specific focus on medical and biological applications. We explain the common types of machine learning algorithms and typical tasks that can be solved, illustrating the basics with concrete examples from healthcare. Lastly, we provide an outlook on open challenges, limitations, and potential impacts of machine-learning-powered medicine.
Debiasing Deep Chest X-Ray Classifiers using Intra- and Post-processing Methods
Jul 26, 2022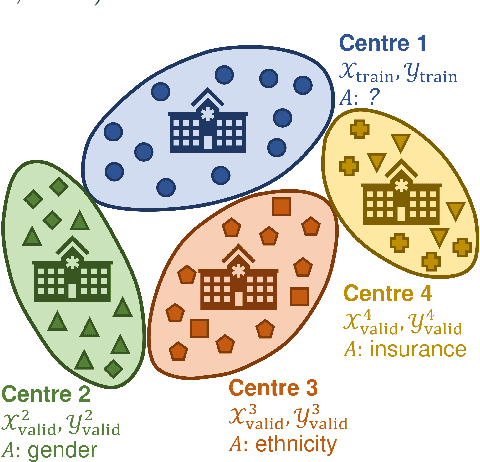
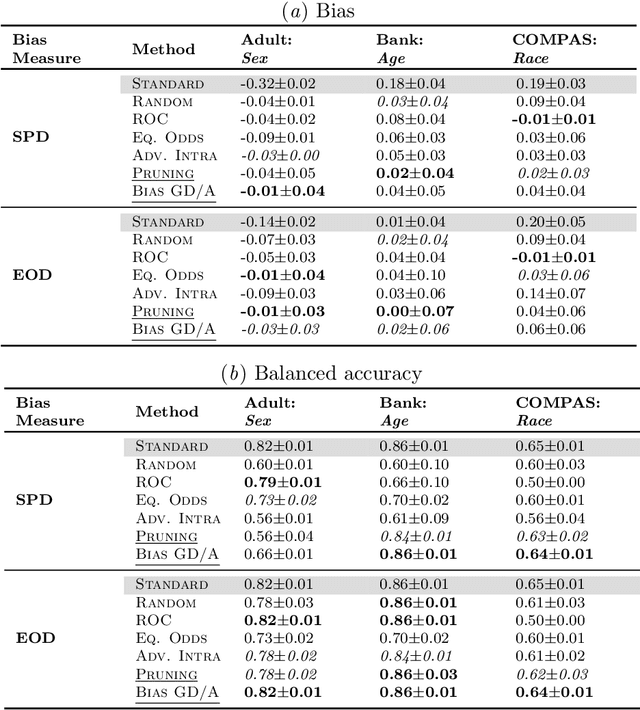
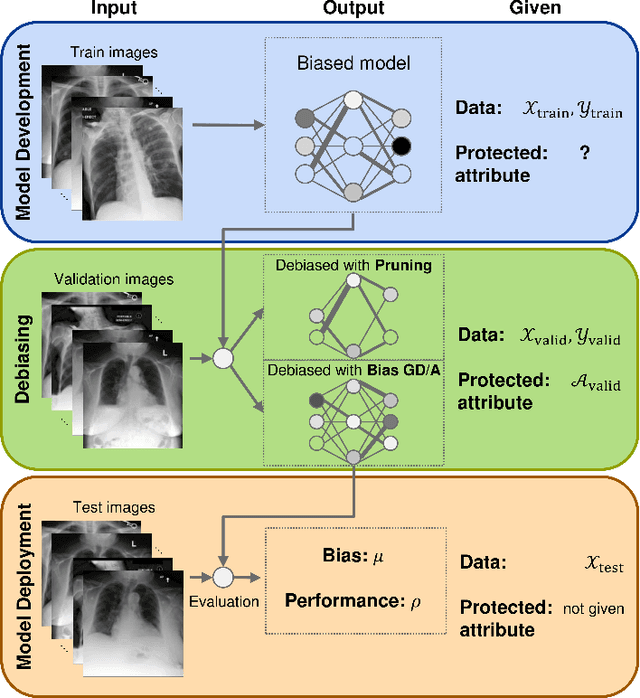
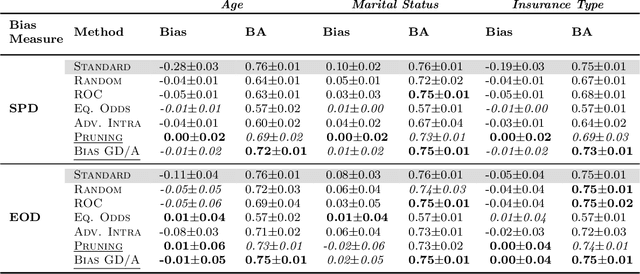
Deep neural networks for image-based screening and computer-aided diagnosis have achieved expert-level performance on various medical imaging modalities, including chest radiographs. Recently, several works have indicated that these state-of-the-art classifiers can be biased with respect to sensitive patient attributes, such as race or gender, leading to growing concerns about demographic disparities and discrimination resulting from algorithmic and model-based decision-making in healthcare. Fair machine learning has focused on mitigating such biases against disadvantaged or marginalised groups, mainly concentrating on tabular data or natural images. This work presents two novel intra-processing techniques based on fine-tuning and pruning an already-trained neural network. These methods are simple yet effective and can be readily applied post hoc in a setting where the protected attribute is unknown during the model development and test time. In addition, we compare several intra- and post-processing approaches applied to debiasing deep chest X-ray classifiers. To the best of our knowledge, this is one of the first efforts studying debiasing methods on chest radiographs. Our results suggest that the considered approaches successfully mitigate biases in fully connected and convolutional neural networks offering stable performance under various settings. The discussed methods can help achieve group fairness of deep medical image classifiers when deploying them in domains with different fairness considerations and constraints.
A Deep Variational Approach to Clustering Survival Data
Jun 10, 2021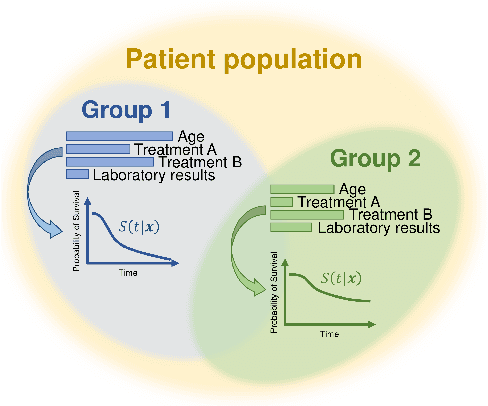

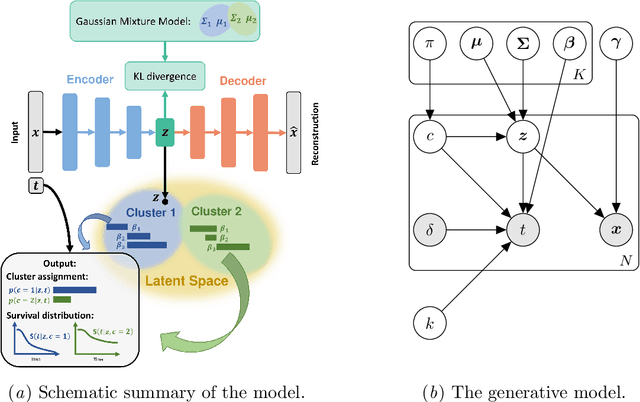
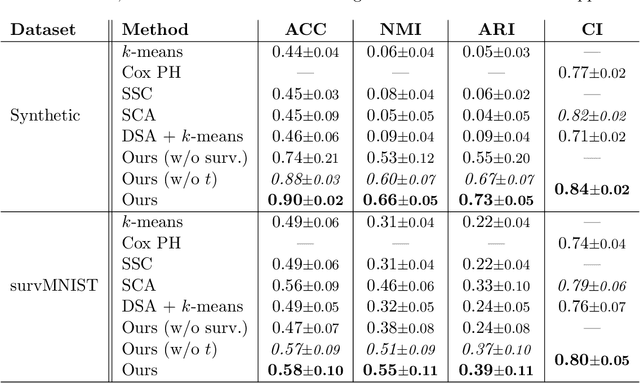
Survival analysis has gained significant attention in the medical domain and has many far-reaching applications. Although a variety of machine learning methods have been introduced for tackling time-to-event prediction in unstructured data with complex dependencies, clustering of survival data remains an under-explored problem. The latter is particularly helpful in discovering patient subpopulations whose survival is regulated by different generative mechanisms, a critical problem in precision medicine. To this end, we introduce a novel probabilistic approach to cluster survival data in a variational deep clustering setting. Our proposed method employs a deep generative model to uncover the underlying distribution of both the explanatory variables and the potentially censored survival times. We compare our model to the related work on survival clustering in comprehensive experiments on a range of synthetic, semi-synthetic, and real-world datasets. Our proposed method performs better at identifying clusters and is competitive at predicting survival times in terms of the concordance index and relative absolute error. To further demonstrate the usefulness of our approach, we show that our method identifies meaningful clusters from an observational cohort of hemodialysis patients that are consistent with previous clinical findings.
Interpretable Models for Granger Causality Using Self-explaining Neural Networks
Jan 19, 2021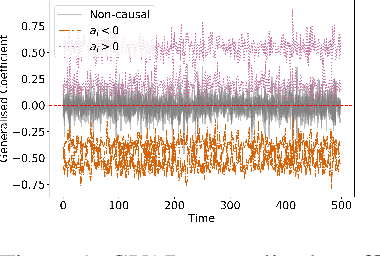
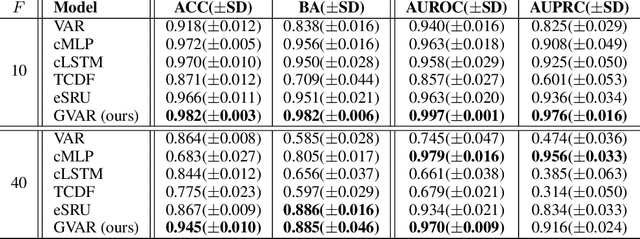


Exploratory analysis of time series data can yield a better understanding of complex dynamical systems. Granger causality is a practical framework for analysing interactions in sequential data, applied in a wide range of domains. In this paper, we propose a novel framework for inferring multivariate Granger causality under nonlinear dynamics based on an extension of self-explaining neural networks. This framework is more interpretable than other neural-network-based techniques for inferring Granger causality, since in addition to relational inference, it also allows detecting signs of Granger-causal effects and inspecting their variability over time. In comprehensive experiments on simulated data, we show that our framework performs on par with several powerful baseline methods at inferring Granger causality and that it achieves better performance at inferring interaction signs. The results suggest that our framework is a viable and more interpretable alternative to sparse-input neural networks for inferring Granger causality.
Interpretability and Explainability: A Machine Learning Zoo Mini-tour
Dec 03, 2020
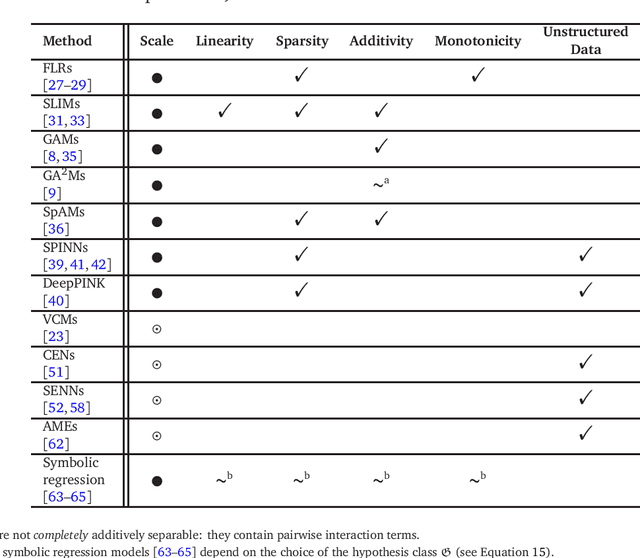
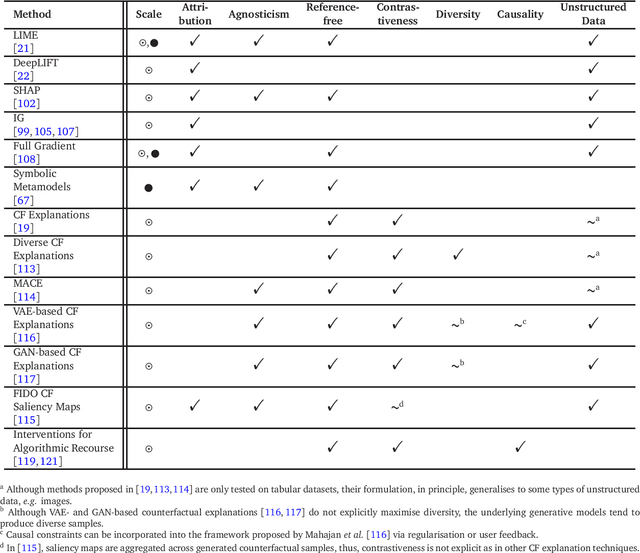
In this review, we examine the problem of designing interpretable and explainable machine learning models. Interpretability and explainability lie at the core of many machine learning and statistical applications in medicine, economics, law, and natural sciences. Although interpretability and explainability have escaped a clear universal definition, many techniques motivated by these properties have been developed over the recent 30 years with the focus currently shifting towards deep learning methods. In this review, we emphasise the divide between interpretability and explainability and illustrate these two different research directions with concrete examples of the state-of-the-art. The review is intended for a general machine learning audience with interest in exploring the problems of interpretation and explanation beyond logistic regression or random forest variable importance. This work is not an exhaustive literature survey, but rather a primer focusing selectively on certain lines of research which the authors found interesting or informative.