 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Glucose-Only Assessment: Advancing Nocturnal Hypoglycemia Prediction in Children with Type 1 Diabetes
Apr 12, 2025The dead-in-bed syndrome describes the sudden and unexplained death of young individuals with Type 1 Diabetes (T1D) without prior long-term complications. One leading hypothesis attributes this phenomenon to nocturnal hypoglycemia (NH), a dangerous drop in blood glucose during sleep. This study aims to improve NH prediction in children with T1D by leveraging physiological data and machine learning (ML) techniques. We analyze an in-house dataset collected from 16 children with T1D, integrating physiological metrics from wearable sensors. We explore predictive performance through feature engineering, model selection, architectures, and oversampling. To address data limitations, we apply transfer learning from a publicly available adult dataset. Our results achieve an AUROC of 0.75 +- 0.21 on the in-house dataset, further improving to 0.78 +- 0.05 with transfer learning. This research moves beyond glucose-only predictions by incorporating physiological parameters, showcasing the potential of ML to enhance NH detection and improve clinical decision-making for pediatric diabetes management.
A Deep Variational Approach to Clustering Survival Data
Jun 10, 2021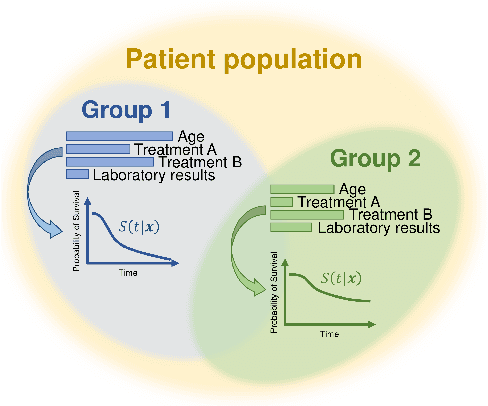

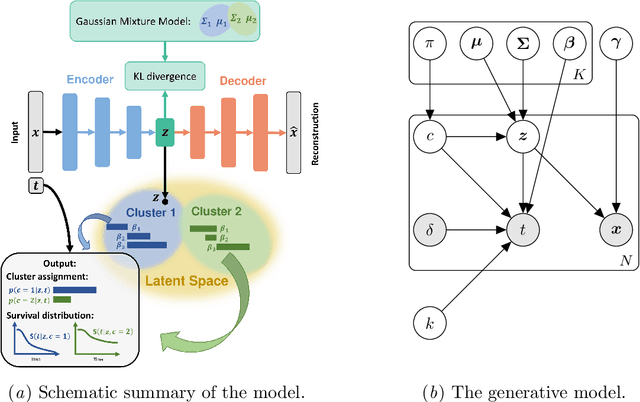
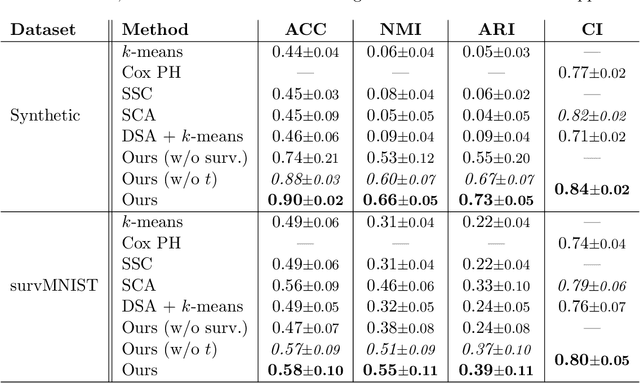
Survival analysis has gained significant attention in the medical domain and has many far-reaching applications. Although a variety of machine learning methods have been introduced for tackling time-to-event prediction in unstructured data with complex dependencies, clustering of survival data remains an under-explored problem. The latter is particularly helpful in discovering patient subpopulations whose survival is regulated by different generative mechanisms, a critical problem in precision medicine. To this end, we introduce a novel probabilistic approach to cluster survival data in a variational deep clustering setting. Our proposed method employs a deep generative model to uncover the underlying distribution of both the explanatory variables and the potentially censored survival times. We compare our model to the related work on survival clustering in comprehensive experiments on a range of synthetic, semi-synthetic, and real-world datasets. Our proposed method performs better at identifying clusters and is competitive at predicting survival times in terms of the concordance index and relative absolute error. To further demonstrate the usefulness of our approach, we show that our method identifies meaningful clusters from an observational cohort of hemodialysis patients that are consistent with previous clinical findings.