Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-framing Incremental Deep Language Models for Dialogue Processing with Multi-task Learning
Paper and Code
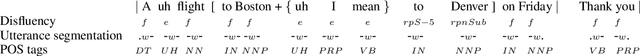
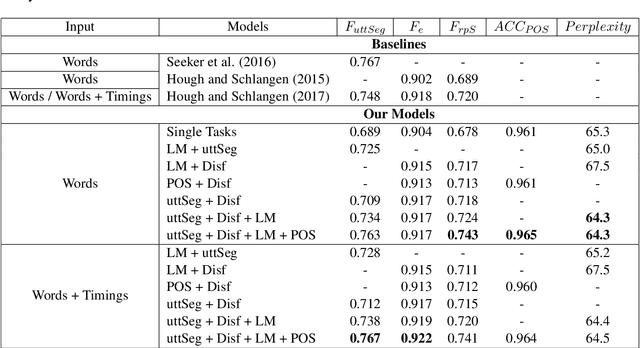
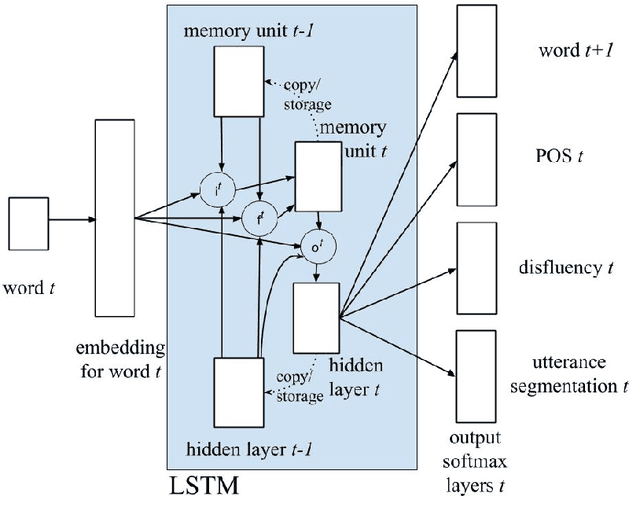
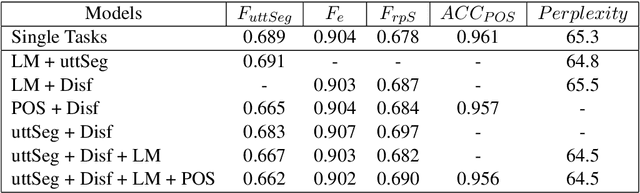
We present a multi-task learning framework to enable the training of one universal incremental dialogue processing model with four tasks of disfluency detection, language modelling, part-of-speech tagging, and utterance segmentation in a simple deep recurrent setting. We show that these tasks provide positive inductive biases to each other with the optimal contribution of each one relying on the severity of the noise from the task. Our live multi-task model outperforms similar individual tasks, delivers competitive performance, and is beneficial for future use in conversational agents in psychiatric treatment.
* The 28th International Conference on Computational Linguistics
(COLING 2020)
View paper on