 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-performance automated abstract screening with large language model ensembles
Nov 03, 2024



Large language models (LLMs) excel in tasks requiring processing and interpretation of input text. Abstract screening is a labour-intensive component of systematic review involving repetitive application of inclusion and exclusion criteria on a large volume of studies identified by a literature search. Here, LLMs (GPT-3.5 Turbo, GPT-4 Turbo, GPT-4o, Llama 3 70B, Gemini 1.5 Pro, and Claude Sonnet 3.5) were trialled on systematic reviews in a full issue of the Cochrane Library to evaluate their accuracy in zero-shot binary classification for abstract screening. Trials over a subset of 800 records identified optimal prompting strategies and demonstrated superior performance of LLMs to human researchers in terms of sensitivity (LLMmax = 1.000, humanmax = 0.775), precision (LLMmax = 0.927, humanmax = 0.911), and balanced accuracy (LLMmax = 0.904, humanmax = 0.865). The best performing LLM-prompt combinations were trialled across every replicated search result (n = 119,691), and exhibited consistent sensitivity (range 0.756-1.000) but diminished precision (range 0.004-0.096). 66 LLM-human and LLM-LLM ensembles exhibited perfect sensitivity with a maximal precision of 0.458, with less observed performance drop in larger trials. Significant variation in performance was observed between reviews, highlighting the importance of domain-specific validation before deployment. LLMs may reduce the human labour cost of systematic review with maintained or improved accuracy and sensitivity. Systematic review is the foundation of evidence-based medicine, and LLMs can contribute to increasing the efficiency and quality of this mode of research.
Privacy-aware Early Detection of COVID-19 through Adversarial Training
Jan 09, 2022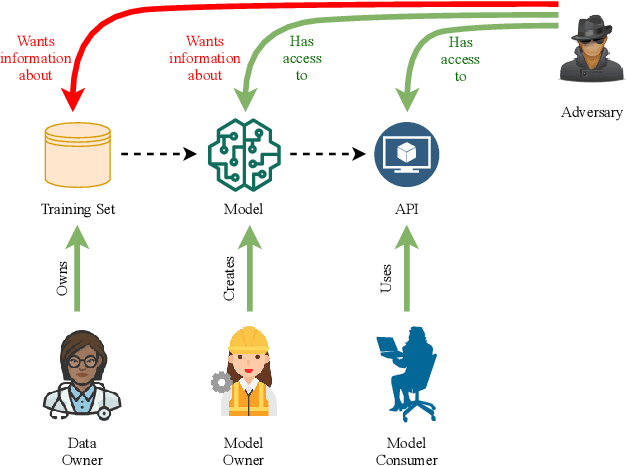
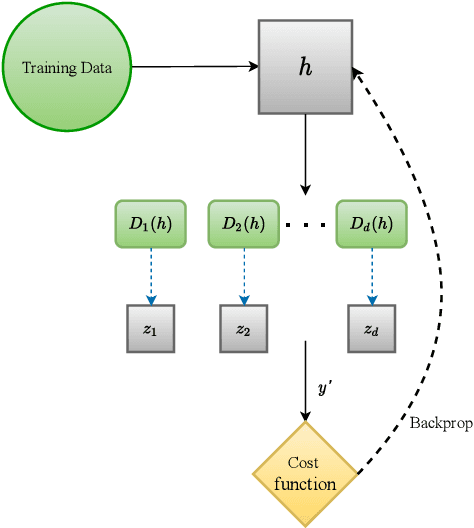

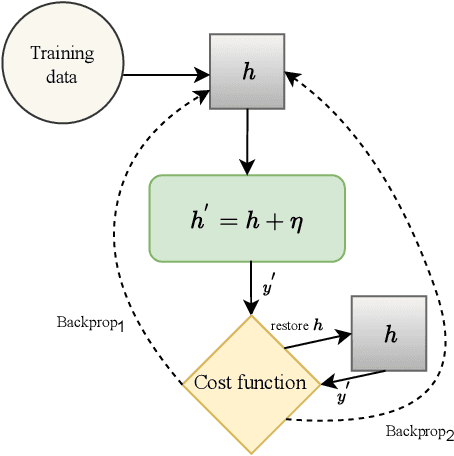
Early detection of COVID-19 is an ongoing area of research that can help with triage, monitoring and general health assessment of potential patients and may reduce operational strain on hospitals that cope with the coronavirus pandemic. Different machine learning techniques have been used in the literature to detect coronavirus using routine clinical data (blood tests, and vital signs). Data breaches and information leakage when using these models can bring reputational damage and cause legal issues for hospitals. In spite of this, protecting healthcare models against leakage of potentially sensitive information is an understudied research area. In this work, we examine two machine learning approaches, intended to predict a patient's COVID-19 status using routinely collected and readily available clinical data. We employ adversarial training to explore robust deep learning architectures that protect attributes related to demographic information about the patients. The two models we examine in this work are intended to preserve sensitive information against adversarial attacks and information leakage. In a series of experiments using datasets from the Oxford University Hospitals, Bedfordshire Hospitals NHS Foundation Trust, University Hospitals Birmingham NHS Foundation Trust, and Portsmouth Hospitals University NHS Trust we train and test two neural networks that predict PCR test results using information from basic laboratory blood tests, and vital signs performed on a patients' arrival to hospital. We assess the level of privacy each one of the models can provide and show the efficacy and robustness of our proposed architectures against a comparable baseline. One of our main contributions is that we specifically target the development of effective COVID-19 detection models with built-in mechanisms in order to selectively protect sensitive attributes against adversarial attacks.