 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Representation Learning for Online Handwriting Text Classification
Paper and Code
Oct 10, 2023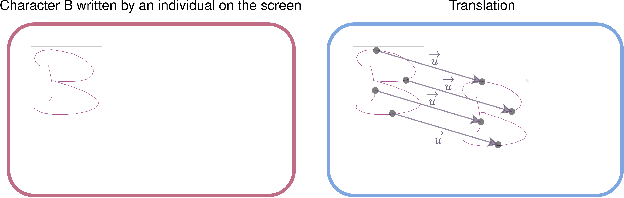
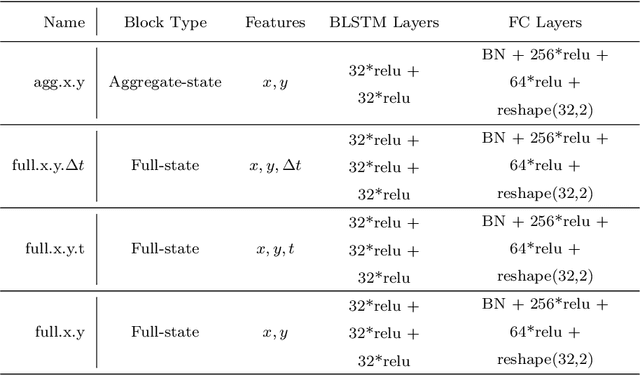
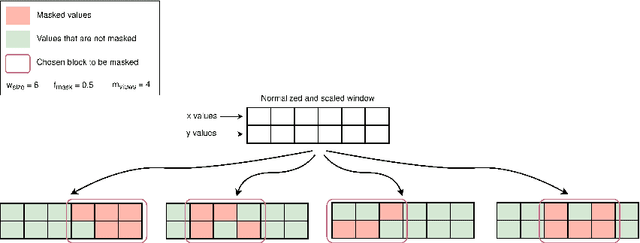
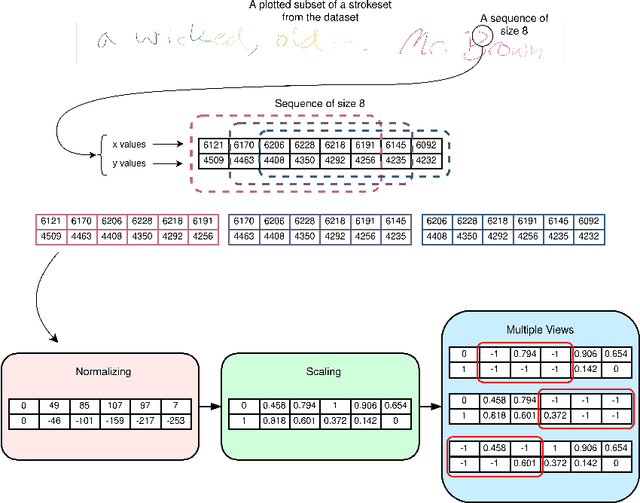
Self-supervised learning offers an efficient way of extracting rich representations from various types of unlabeled data while avoiding the cost of annotating large-scale datasets. This is achievable by designing a pretext task to form pseudo labels with respect to the modality and domain of the data. Given the evolving applications of online handwritten texts, in this study, we propose the novel Part of Stroke Masking (POSM) as a pretext task for pretraining models to extract informative representations from the online handwriting of individuals in English and Chinese languages, along with two suggested pipelines for fine-tuning the pretrained models. To evaluate the quality of the extracted representations, we use both intrinsic and extrinsic evaluation methods. The pretrained models are fine-tuned to achieve state-of-the-art results in tasks such as writer identification, gender classification, and handedness classification, also highlighting the superiority of utilizing the pretrained models over the models trained from scratch.