 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Augmentation Consistency for Adapting Semantic Segmentation
Paper and Code
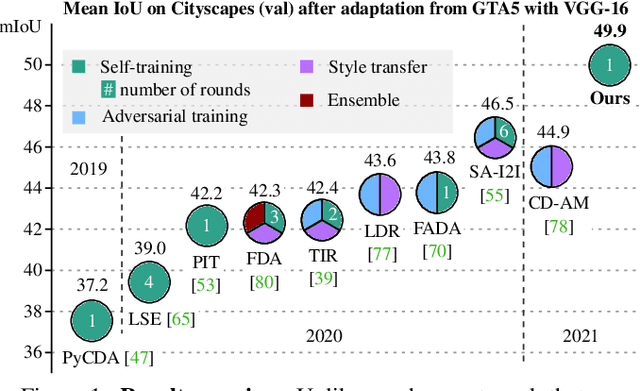


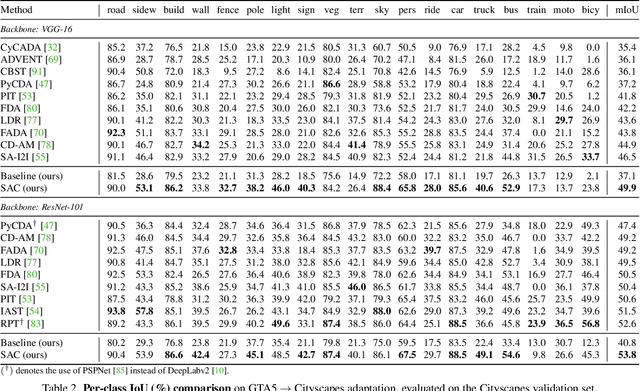
We propose an approach to domain adaptation for semantic segmentation that is both practical and highly accurate. In contrast to previous work, we abandon the use of computationally involved adversarial objectives, network ensembles and style transfer. Instead, we employ standard data augmentation techniques $-$ photometric noise, flipping and scaling $-$ and ensure consistency of the semantic predictions across these image transformations. We develop this principle in a lightweight self-supervised framework trained on co-evolving pseudo labels without the need for cumbersome extra training rounds. Simple in training from a practitioner's standpoint, our approach is remarkably effective. We achieve significant improvements of the state-of-the-art segmentation accuracy after adaptation, consistent both across different choices of the backbone architecture and adaptation scenarios.