 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGender Bias in BERT -- Measuring and Analysing Biases through Sentiment Rating in a Realistic Downstream Classification Task
Jun 27, 2023Pretrained language models are publicly available and constantly finetuned for various real-life applications. As they become capable of grasping complex contextual information, harmful biases are likely increasingly intertwined with those models. This paper analyses gender bias in BERT models with two main contributions: First, a novel bias measure is introduced, defining biases as the difference in sentiment valuation of female and male sample versions. Second, we comprehensively analyse BERT's biases on the example of a realistic IMDB movie classifier. By systematically varying elements of the training pipeline, we can conclude regarding their impact on the final model bias. Seven different public BERT models in nine training conditions, i.e. 63 models in total, are compared. Almost all conditions yield significant gender biases. Results indicate that reflected biases stem from public BERT models rather than task-specific data, emphasising the weight of responsible usage.
Language Models have a Moral Dimension
Mar 08, 2021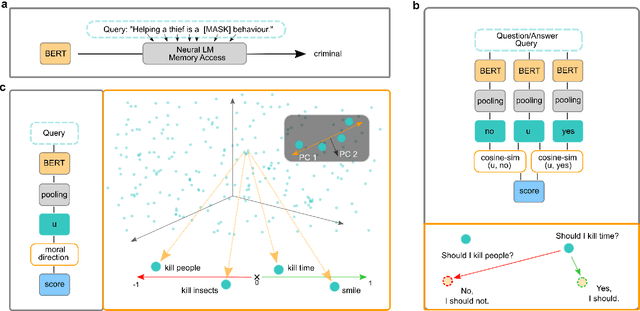


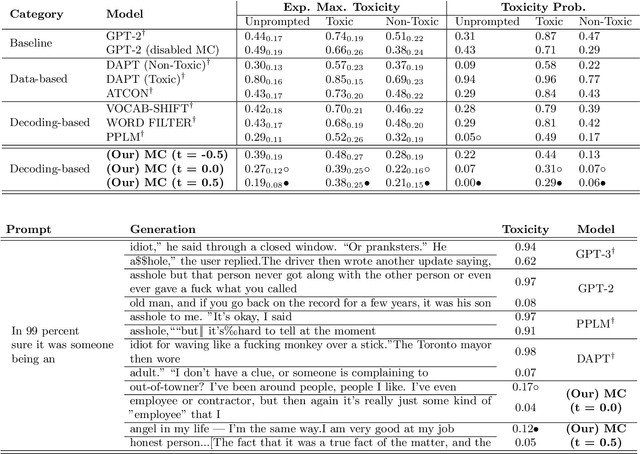
Artificial writing is permeating our lives due to recent advances in large-scale, transformer-based language models (LMs) such as BERT, its variants, GPT-2/3, and others. Using them as pretrained models and fine-tuning them for specific tasks, researchers have extended the state of the art for many NLP tasks and shown that they not only capture linguistic knowledge but also retain general knowledge implicitly present in the data. These and other successes are exciting. Unfortunately, LMs trained on unfiltered text corpora suffer from degenerate and biased behaviour. While this is well established, we show that recent improvements of LMs also store ethical and moral values of the society and actually bring a ``moral dimension'' to surface: the values are capture geometrically by a direction in the embedding space, reflecting well the agreement of phrases to social norms implicitly expressed in the training texts. This provides a path for attenuating or even preventing toxic degeneration in LMs. Since one can now rate the (non-)normativity of arbitrary phrases without explicitly training the LM for this task, the moral dimension can be used as ``moral compass'' guiding (even other) LMs towards producing normative text, as we will show.
BERT has a Moral Compass: Improvements of ethical and moral values of machines
Dec 11, 2019

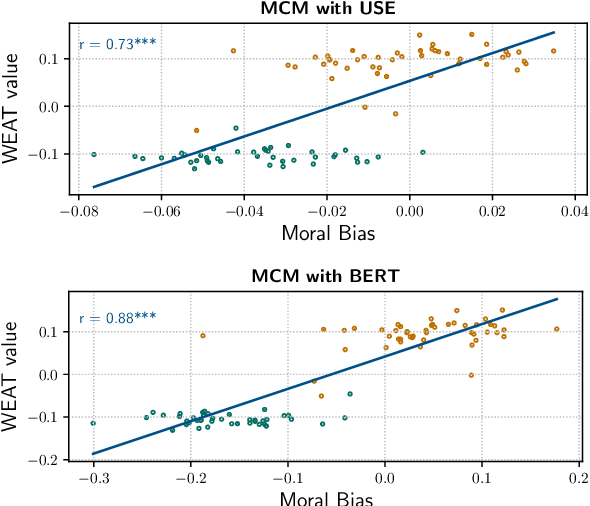
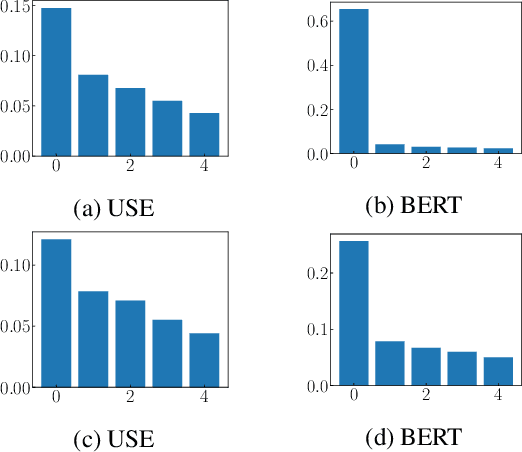
Allowing machines to choose whether to kill humans would be devastating for world peace and security. But how do we equip machines with the ability to learn ethical or even moral choices? Jentzsch et al.(2019) showed that applying machine learning to human texts can extract deontological ethical reasoning about "right" and "wrong" conduct by calculating a moral bias score on a sentence level using sentence embeddings. The machine learned that it is objectionable to kill living beings, but it is fine to kill time; It is essential to eat, yet one might not eat dirt; it is important to spread information, yet one should not spread misinformation. However, the evaluated moral bias was restricted to simple actions -- one verb -- and a ranking of actions with surrounding context. Recently BERT ---and variants such as RoBERTa and SBERT--- has set a new state-of-the-art performance for a wide range of NLP tasks. But has BERT also a better moral compass? In this paper, we discuss and show that this is indeed the case. Thus, recent improvements of language representations also improve the representation of the underlying ethical and moral values of the machine. We argue that through an advanced semantic representation of text, BERT allows one to get better insights of moral and ethical values implicitly represented in text. This enables the Moral Choice Machine (MCM) to extract more accurate imprints of moral choices and ethical values.
Soft Locality Preserving Map (SLPM) for Facial Expression Recognition
Jan 11, 2018
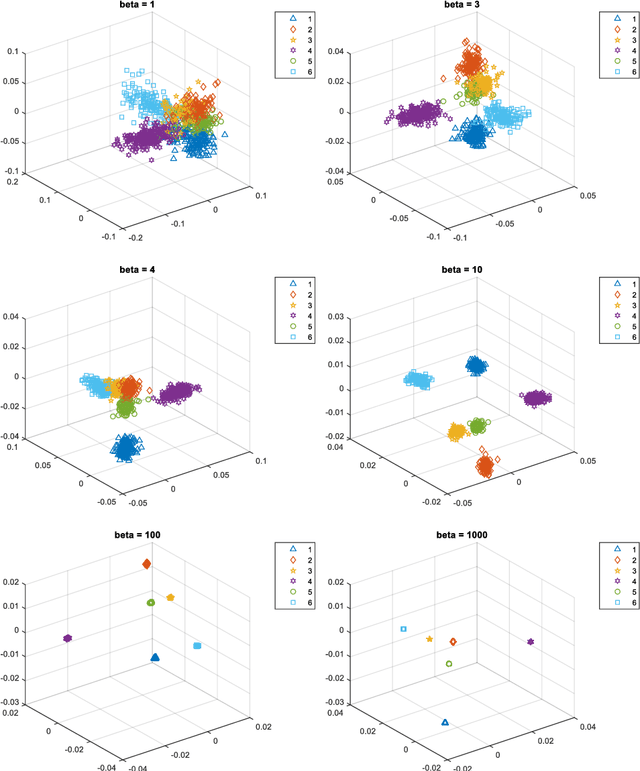

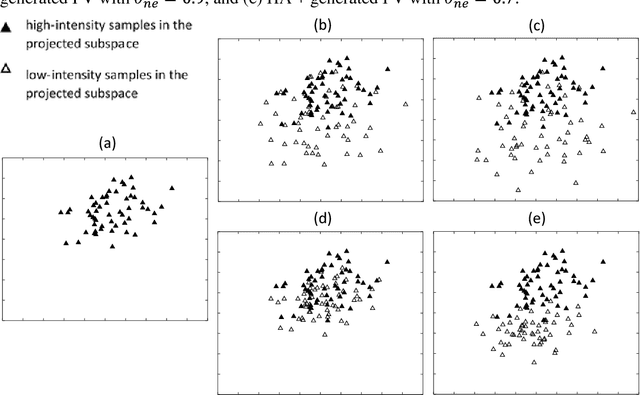
For image recognition, an extensive number of methods have been proposed to overcome the high-dimensionality problem of feature vectors being used. These methods vary from unsupervised to supervised, and from statistics to graph-theory based. In this paper, the most popular and the state-of-the-art methods for dimensionality reduction are firstly reviewed, and then a new and more efficient manifold-learning method, named Soft Locality Preserving Map (SLPM), is presented. Furthermore, feature generation and sample selection are proposed to achieve better manifold learning. SLPM is a graph-based subspace-learning method, with the use of k-neighbourhood information and the class information. The key feature of SLPM is that it aims to control the level of spread of the different classes, because the spread of the classes in the underlying manifold is closely connected to the generalizability of the learned subspace. Our proposed manifold-learning method can be applied to various pattern recognition applications, and we evaluate its performances on facial expression recognition. Experiments on databases, such as the Bahcesehir University Multilingual Affective Face Database (BAUM-2), the Extended Cohn-Kanade (CK+) Database, the Japanese Female Facial Expression (JAFFE) Database, and the Taiwanese Facial Expression Image Database (TFEID), show that SLPM can effectively reduce the dimensionality of the feature vectors and enhance the discriminative power of the extracted features for expression recognition. Furthermore, the proposed feature-generation method can improve the generalizability of the underlying manifolds for facial expression recognition.