 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Tuned Scene Generation
Jul 07, 2017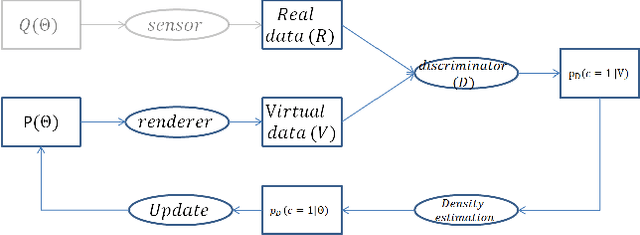
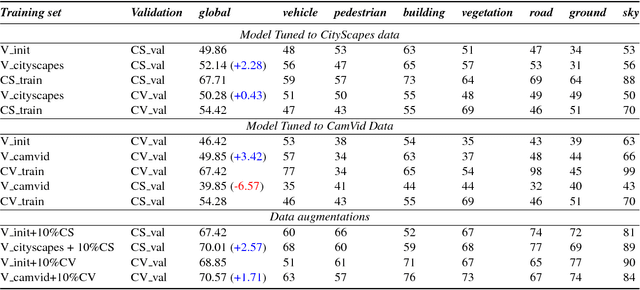

Generalization performance of trained computer vision systems that use computer graphics (CG) generated data is not yet effective due to the concept of 'domain-shift' between virtual and real data. Although simulated data augmented with a few real world samples has been shown to mitigate domain shift and improve transferability of trained models, guiding or bootstrapping the virtual data generation with the distributions learnt from target real world domain is desired, especially in the fields where annotating even few real images is laborious (such as semantic labeling, and intrinsic images etc.). In order to address this problem in an unsupervised manner, our work combines recent advances in CG (which aims to generate stochastic scene layouts coupled with large collections of 3D object models) and generative adversarial training (which aims train generative models by measuring discrepancy between generated and real data in terms of their separability in the space of a deep discriminatively-trained classifier). Our method uses iterative estimation of the posterior density of prior distributions for a generative graphical model. This is done within a rejection sampling framework. Initially, we assume uniform distributions as priors on the parameters of a scene described by a generative graphical model. As iterations proceed the prior distributions get updated to distributions that are closer to the (unknown) distributions of target data. We demonstrate the utility of adversarially tuned scene generation on two real-world benchmark datasets (CityScapes and CamVid) for traffic scene semantic labeling with a deep convolutional net (DeepLab). We realized performance improvements by 2.28 and 3.14 points (using the IoU metric) between the DeepLab models trained on simulated sets prepared from the scene generation models before and after tuning to CityScapes and CamVid respectively.
Model-driven Simulations for Deep Convolutional Neural Networks
May 31, 2016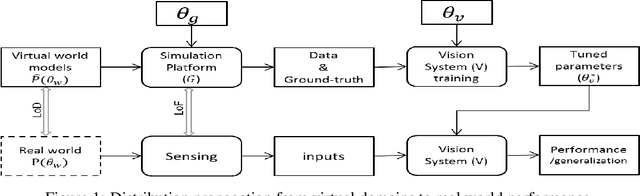
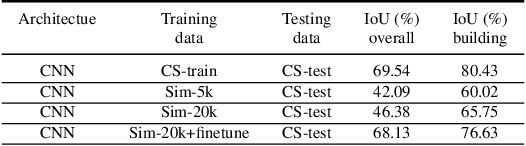


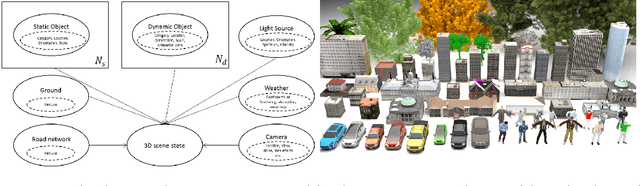
The use of simulated virtual environments to train deep convolutional neural networks (CNN) is a currently active practice to reduce the (real)data-hungriness of the deep CNN models, especially in application domains in which large scale real data and/or groundtruth acquisition is difficult or laborious. Recent approaches have attempted to harness the capabilities of existing video games, animated movies to provide training data with high precision groundtruth. However, a stumbling block is in how one can certify generalization of the learned models and their usefulness in real world data sets. This opens up fundamental questions such as: What is the role of photorealism of graphics simulations in training CNN models? Are the trained models valid in reality? What are possible ways to reduce the performance bias? In this work, we begin to address theses issues systematically in the context of urban semantic understanding with CNNs. Towards this end, we (a) propose a simple probabilistic urban scene model, (b) develop a parametric rendering tool to synthesize the data with groundtruth, followed by (c) a systematic exploration of the impact of level-of-realism on the generality of the trained CNN model to real world; and domain adaptation concepts to minimize the performance bias.
Cardiac Motion Analysis by Temporal Flow Graphs
Apr 24, 2016



Cardiac motion analysis from B-mode ultrasound sequence is a key task in assessing the health of the heart. The paper proposes a new methodology for cardiac motion analysis based on the temporal behaviour of points of interest on the myocardium. We define a new signal called the Temporal Flow Graph (TFG) which depicts the movement of a point of interest over time. It is a graphical representation derived from a flow field and describes the temporal evolution of a point. We prove that TFG for an object undergoing periodic motion is also periodic. This principle can be utilized to derive both global and local information from a given sequence. We demonstrate this for detecting motion irregularities at the sequence, as well as regional levels on real and synthetic data. A coarse localisation of anatomical landmarks such as centres of left/right cavities and valve points is also demonstrated using TFGs.
Model Validation for Vision Systems via Graphics Simulation
Dec 04, 2015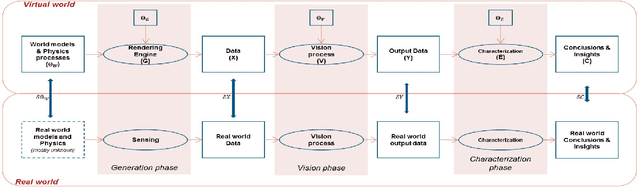
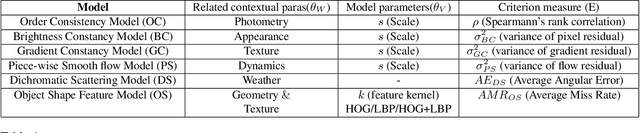

Rapid advances in computation, combined with latest advances in computer graphics simulations have facilitated the development of vision systems and training them in virtual environments. One major stumbling block is in certification of the designs and tuned parameters of these systems to work in real world. In this paper, we begin to explore the fundamental question: Which type of information transfer is more analogous to real world? Inspired from the performance characterization methodology outlined in the 90's, we note that insights derived from simulations can be qualitative or quantitative depending on the degree of the fidelity of models used in simulations and the nature of the questions posed by the experimenter. We adapt the methodology in the context of current graphics simulation tools for modeling data generation processes and, for systematic performance characterization and trade-off analysis for vision system design leading to qualitative and quantitative insights. In concrete, we examine invariance assumptions used in vision algorithms for video surveillance settings as a case study and assess the degree to which those invariance assumptions deviate as a function of contextual variables on both graphics simulations and in real data. As computer graphics rendering quality improves, we believe teasing apart the degree to which model assumptions are valid via systematic graphics simulation can be a significant aid to assisting more principled ways of approaching vision system design and performance modeling.
Simulations for Validation of Vision Systems
Dec 03, 2015
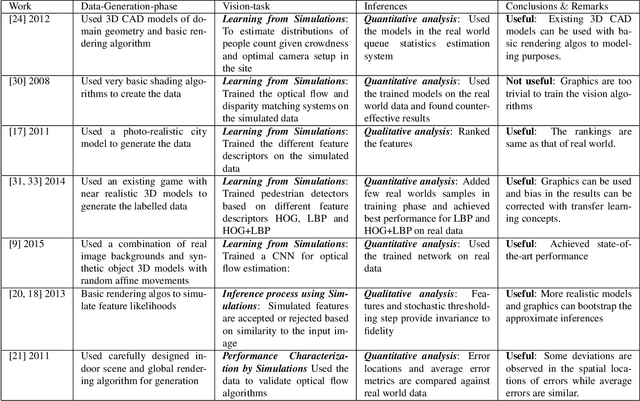
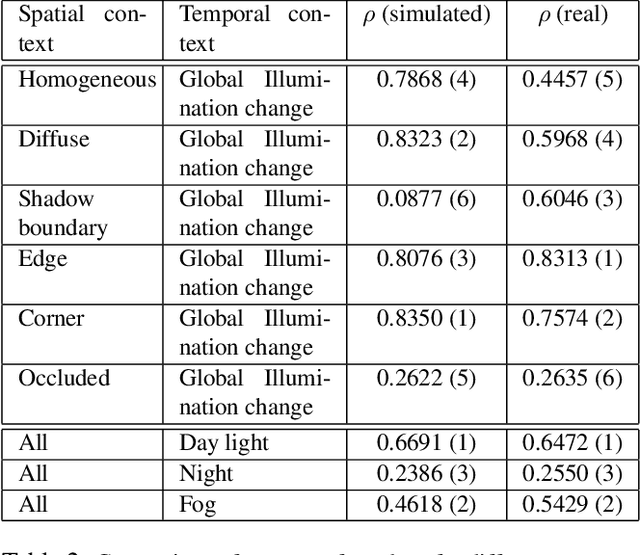

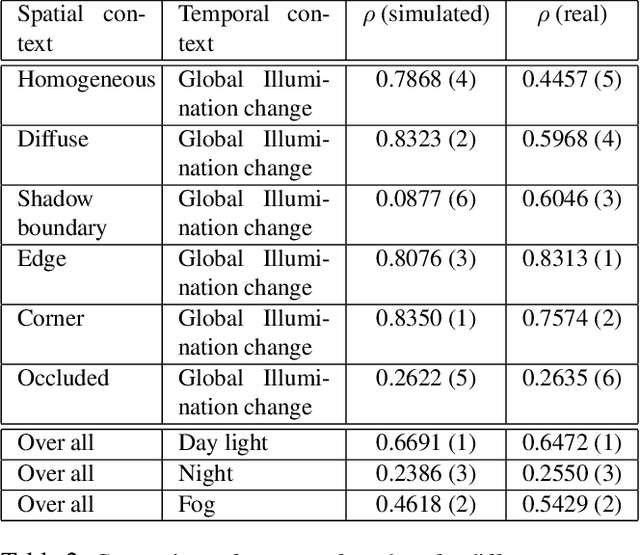
As the computer vision matures into a systems science and engineering discipline, there is a trend in leveraging latest advances in computer graphics simulations for performance evaluation, learning, and inference. However, there is an open question on the utility of graphics simulations for vision with apparently contradicting views in the literature. In this paper, we place the results from the recent literature in the context of performance characterization methodology outlined in the 90's and note that insights derived from simulations can be qualitative or quantitative depending on the degree of fidelity of models used in simulation and the nature of the question posed by the experimenter. We describe a simulation platform that incorporates latest graphics advances and use it for systematic performance characterization and trade-off analysis for vision system design. We verify the utility of the platform in a case study of validating a generative model inspired vision hypothesis, Rank-Order consistency model, in the contexts of global and local illumination changes, and bad weather, and high-frequency noise. Our approach establishes the link between alternative viewpoints, involving models with physics based semantics and signal and perturbation semantics and confirms insights in literature on robust change detection.