 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Evaluation of Engineering Artificial General Intelligence
May 15, 2025
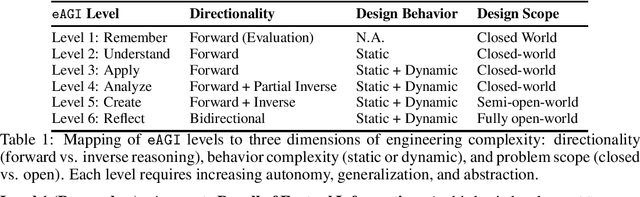

We discuss the challenges and propose a framework for evaluating engineering artificial general intelligence (eAGI) agents. We consider eAGI as a specialization of artificial general intelligence (AGI), deemed capable of addressing a broad range of problems in the engineering of physical systems and associated controllers. We exclude software engineering for a tractable scoping of eAGI and expect dedicated software engineering AI agents to address the software implementation challenges. Similar to human engineers, eAGI agents should possess a unique blend of background knowledge (recall and retrieve) of facts and methods, demonstrate familiarity with tools and processes, exhibit deep understanding of industrial components and well-known design families, and be able to engage in creative problem solving (analyze and synthesize), transferring ideas acquired in one context to another. Given this broad mandate, evaluating and qualifying the performance of eAGI agents is a challenge in itself and, arguably, a critical enabler to developing eAGI agents. In this paper, we address this challenge by proposing an extensible evaluation framework that specializes and grounds Bloom's taxonomy - a framework for evaluating human learning that has also been recently used for evaluating LLMs - in an engineering design context. Our proposed framework advances the state of the art in benchmarking and evaluation of AI agents in terms of the following: (a) developing a rich taxonomy of evaluation questions spanning from methodological knowledge to real-world design problems; (b) motivating a pluggable evaluation framework that can evaluate not only textual responses but also evaluate structured design artifacts such as CAD models and SysML models; and (c) outlining an automatable procedure to customize the evaluation benchmark to different engineering contexts.
CaloChallenge 2022: A Community Challenge for Fast Calorimeter Simulation
Oct 28, 2024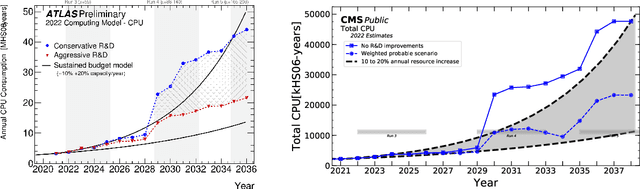
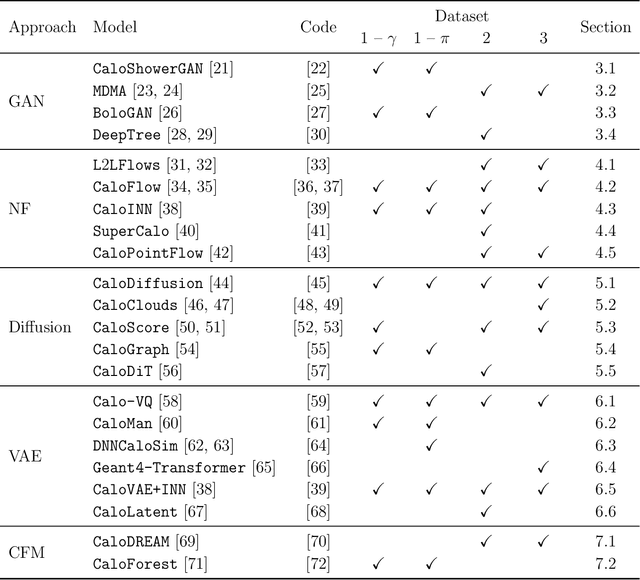
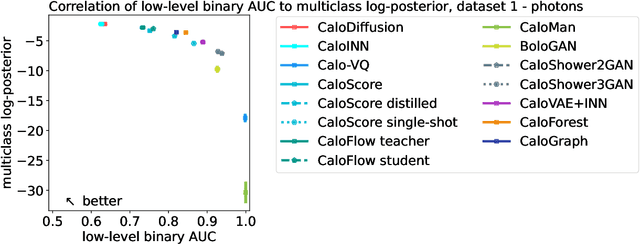
We present the results of the "Fast Calorimeter Simulation Challenge 2022" - the CaloChallenge. We study state-of-the-art generative models on four calorimeter shower datasets of increasing dimensionality, ranging from a few hundred voxels to a few tens of thousand voxels. The 31 individual submissions span a wide range of current popular generative architectures, including Variational AutoEncoders (VAEs), Generative Adversarial Networks (GANs), Normalizing Flows, Diffusion models, and models based on Conditional Flow Matching. We compare all submissions in terms of quality of generated calorimeter showers, as well as shower generation time and model size. To assess the quality we use a broad range of different metrics including differences in 1-dimensional histograms of observables, KPD/FPD scores, AUCs of binary classifiers, and the log-posterior of a multiclass classifier. The results of the CaloChallenge provide the most complete and comprehensive survey of cutting-edge approaches to calorimeter fast simulation to date. In addition, our work provides a uniquely detailed perspective on the important problem of how to evaluate generative models. As such, the results presented here should be applicable for other domains that use generative AI and require fast and faithful generation of samples in a large phase space.
Calo-VQ: Vector-Quantized Two-Stage Generative Model in Calorimeter Simulation
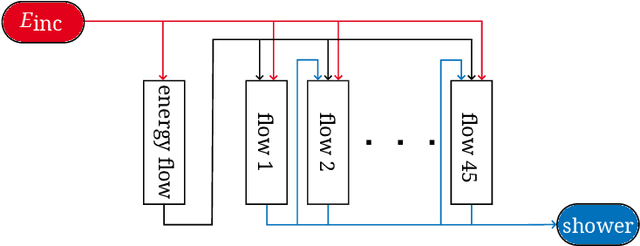
May 10, 2024We introduce a novel machine learning method developed for the fast simulation of calorimeter detector response, adapting vector-quantized variational autoencoder (VQ-VAE). Our model adopts a two-stage generation strategy: initially compressing geometry-aware calorimeter data into a discrete latent space, followed by the application of a sequence model to learn and generate the latent tokens. Extensive experimentation on the Calo-challenge dataset underscores the efficiency of our approach, showcasing a remarkable improvement in the generation speed compared with conventional method by a factor of 2000. Remarkably, our model achieves the generation of calorimeter showers within milliseconds. Furthermore, comprehensive quantitative evaluations across various metrics are performed to validate physics performance of generation.
Rethinking SO(3)-equivariance with Bilinear Tensor Networks
Mar 20, 2023



Many datasets in scientific and engineering applications are comprised of objects which have specific geometric structure. A common example is data which inhabits a representation of the group SO$(3)$ of 3D rotations: scalars, vectors, tensors, \textit{etc}. One way for a neural network to exploit prior knowledge of this structure is to enforce SO$(3)$-equivariance throughout its layers, and several such architectures have been proposed. While general methods for handling arbitrary SO$(3)$ representations exist, they computationally intensive and complicated to implement. We show that by judicious symmetry breaking, we can efficiently increase the expressiveness of a network operating only on vector and order-2 tensor representations of SO$(2)$. We demonstrate the method on an important problem from High Energy Physics known as \textit{b-tagging}, where particle jets originating from b-meson decays must be discriminated from an overwhelming QCD background. In this task, we find that augmenting a standard architecture with our method results in a \ensuremath{2.3\times} improvement in rejection score.
Symmetry Group Equivariant Architectures for Physics
Mar 11, 2022
Physical theories grounded in mathematical symmetries are an essential component of our understanding of a wide range of properties of the universe. Similarly, in the domain of machine learning, an awareness of symmetries such as rotation or permutation invariance has driven impressive performance breakthroughs in computer vision, natural language processing, and other important applications. In this report, we argue that both the physics community and the broader machine learning community have much to understand and potentially to gain from a deeper investment in research concerning symmetry group equivariant machine learning architectures. For some applications, the introduction of symmetries into the fundamental structural design can yield models that are more economical (i.e. contain fewer, but more expressive, learned parameters), interpretable (i.e. more explainable or directly mappable to physical quantities), and/or trainable (i.e. more efficient in both data and computational requirements). We discuss various figures of merit for evaluating these models as well as some potential benefits and limitations of these methods for a variety of physics applications. Research and investment into these approaches will lay the foundation for future architectures that are potentially more robust under new computational paradigms and will provide a richer description of the physical systems to which they are applied.
Particle Convolution for High Energy Physics
Jul 05, 2021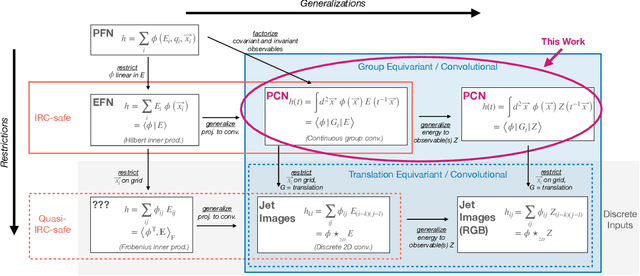
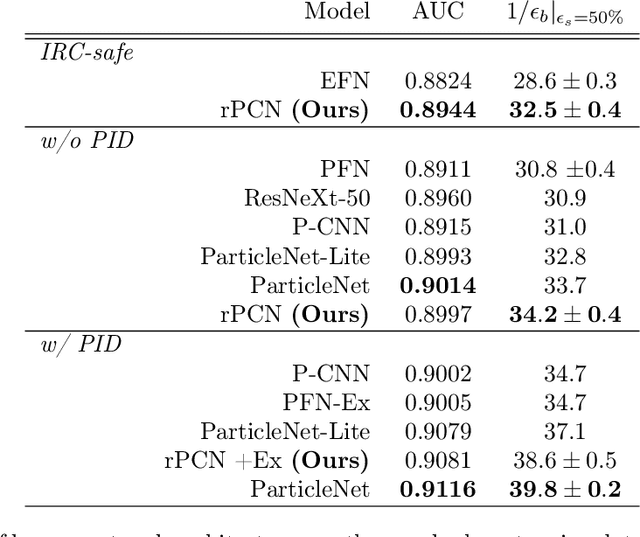

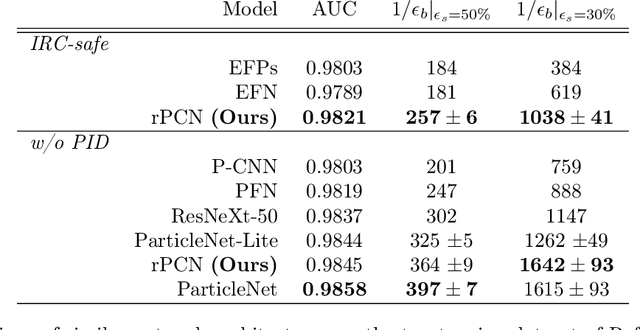
We introduce the Particle Convolution Network (PCN), a new type of equivariant neural network layer suitable for many tasks in jet physics. The particle convolution layer can be viewed as an extension of Deep Sets and Energy Flow network architectures, in which the permutation-invariant operator is promoted to a group convolution. While the PCN can be implemented for various kinds of symmetries, we consider the specific case of rotation about the jet axis the $\eta - \phi$ plane. In two standard benchmark tasks, q/g tagging and top tagging, we show that the rotational PCN (rPCN) achieves performance comparable to graph networks such as ParticleNet. Moreover, we show that it is possible to implement an IRC-safe rPCN, which significantly outperforms existing IRC-safe tagging methods on both tasks. We speculate that by generalizing the PCN to include additional convolutional symmetries relevant to jet physics, it may outperform the current state-of-the-art set by graph networks, while offering a new degree of control over physically-motivated inductive biases.
AI Safety for High Energy Physics
Oct 18, 2019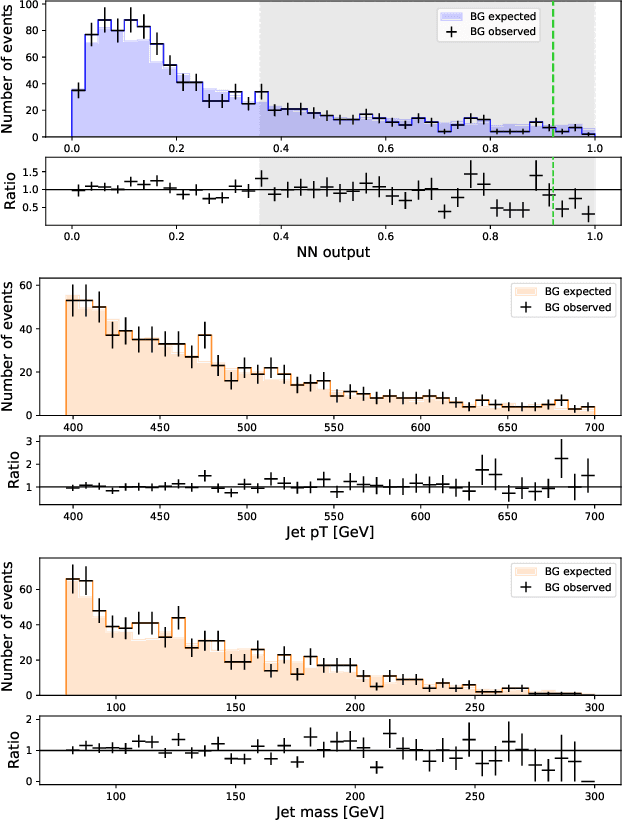
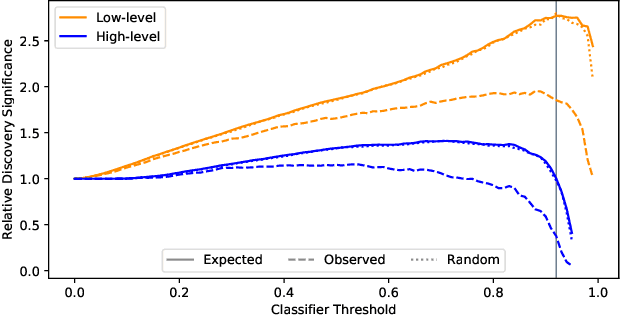

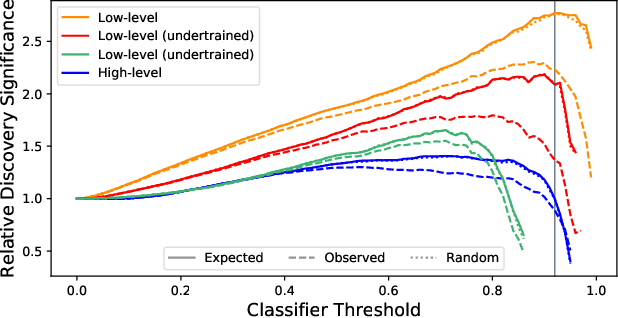
The field of high-energy physics (HEP), along with many scientific disciplines, is currently experiencing a dramatic influx of new methodologies powered by modern machine learning techniques. Over the last few years, a growing body of HEP literature has focused on identifying promising applications of deep learning in particular, and more recently these techniques are starting to be realized in an increasing number of experimental measurements. The overall conclusion from this impressive and extensive set of studies is that rarer and more complex physics signatures can be identified with the new set of powerful tools from deep learning. However, there is an unstudied systematic risk associated with combining the traditional HEP workflow and deep learning with high-dimensional data. In particular, calibrating and validating the response of deep neural networks is in general not experimentally feasible, and therefore current methods may be biased in ways that are not covered by current uncertainty estimates. By borrowing ideas from AI safety, we illustrate these potential issues and propose a method to bound the size of unaccounted for uncertainty. In addition to providing a pragmatic diagnostic, this work will hopefully begin a dialogue within the community about the robust application of deep learning to experimental analyses.
Beyond Imitation: Generative and Variational Choreography via Machine Learning
Jul 11, 2019

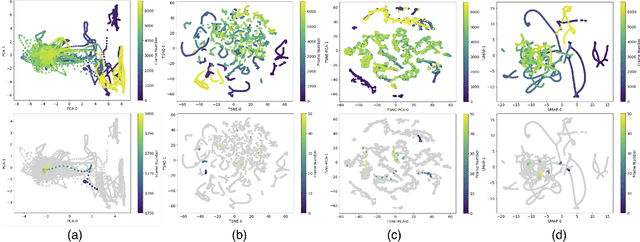
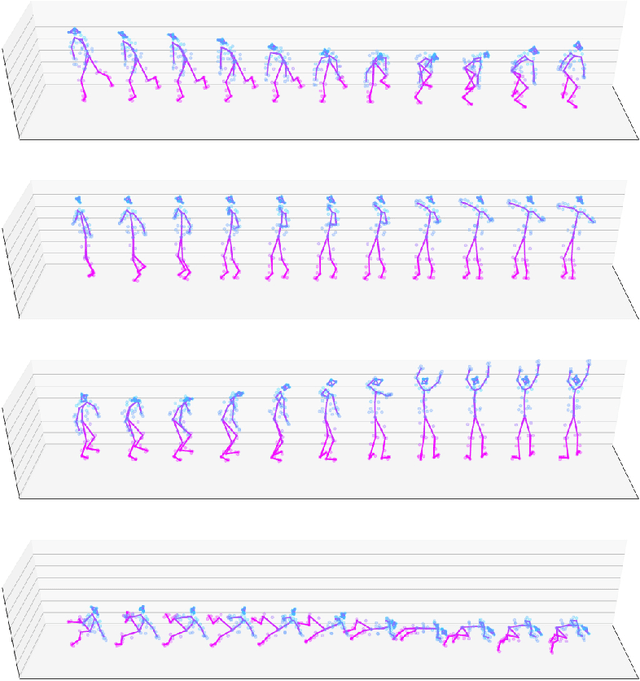
Our team of dance artists, physicists, and machine learning researchers has collectively developed several original, configurable machine-learning tools to generate novel sequences of choreography as well as tunable variations on input choreographic sequences. We use recurrent neural network and autoencoder architectures from a training dataset of movements captured as 53 three-dimensional points at each timestep. Sample animations of generated sequences and an interactive version of our model can be found at http: //www.beyondimitation.com.
Muon Trigger for Mobile Phones
Sep 25, 2017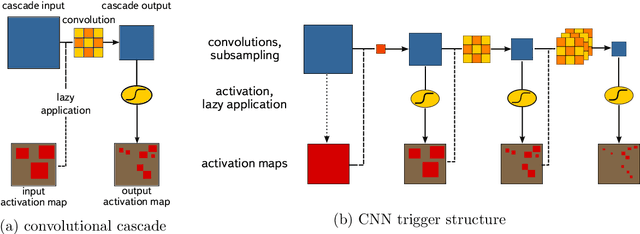

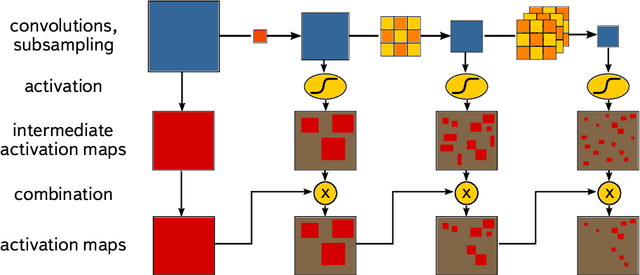

The CRAYFIS experiment proposes to use privately owned mobile phones as a ground detector array for Ultra High Energy Cosmic Rays. Upon interacting with Earth's atmosphere, these events produce extensive particle showers which can be detected by cameras on mobile phones. A typical shower contains minimally-ionizing particles such as muons. As these particles interact with CMOS image sensors, they may leave tracks of faintly-activated pixels that are sometimes hard to distinguish from random detector noise. Triggers that rely on the presence of very bright pixels within an image frame are not efficient in this case. We present a trigger algorithm based on Convolutional Neural Networks which selects images containing such tracks and are evaluated in a lazy manner: the response of each successive layer is computed only if activation of the current layer satisfies a continuation criterion. Usage of neural networks increases the sensitivity considerably comparable with image thresholding, while the lazy evaluation allows for execution of the trigger under the limited computational power of mobile phones.
Decorrelated Jet Substructure Tagging using Adversarial Neural Networks
Mar 10, 2017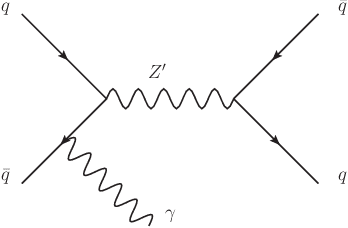
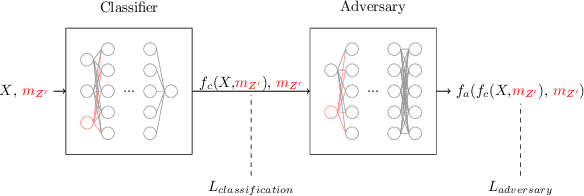
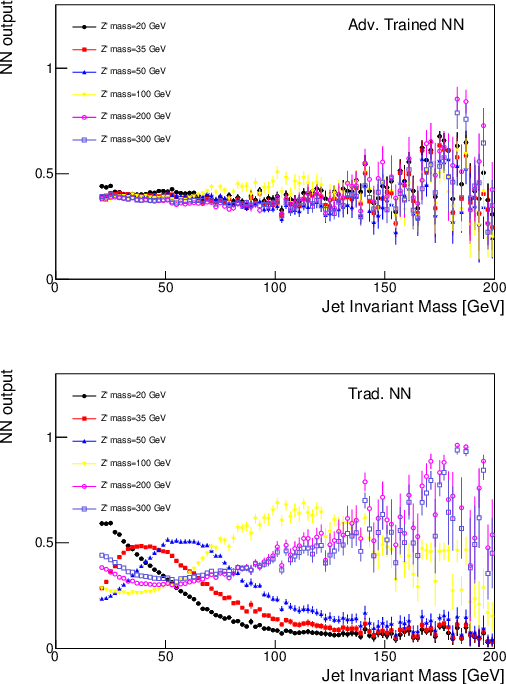
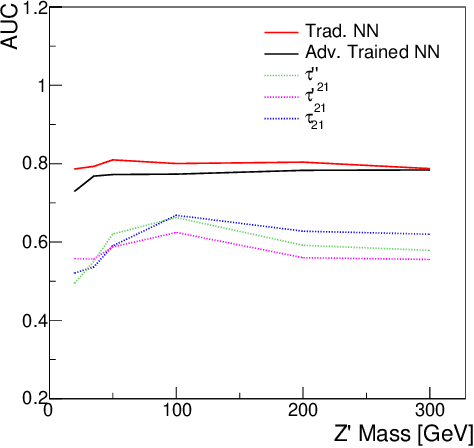
We describe a strategy for constructing a neural network jet substructure tagger which powerfully discriminates boosted decay signals while remaining largely uncorrelated with the jet mass. This reduces the impact of systematic uncertainties in background modeling while enhancing signal purity, resulting in improved discovery significance relative to existing taggers. The network is trained using an adversarial strategy, resulting in a tagger that learns to balance classification accuracy with decorrelation. As a benchmark scenario, we consider the case where large-radius jets originating from a boosted resonance decay are discriminated from a background of nonresonant quark and gluon jets. We show that in the presence of systematic uncertainties on the background rate, our adversarially-trained, decorrelated tagger considerably outperforms a conventionally trained neural network, despite having a slightly worse signal-background separation power. We generalize the adversarial training technique to include a parametric dependence on the signal hypothesis, training a single network that provides optimized, interpolatable decorrelated jet tagging across a continuous range of hypothetical resonance masses, after training on discrete choices of the signal mass.