 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Self-Driving Trigger at the LHC: Adaptive Response in Real Time
Jan 13, 2026Real-time data filtering and selection -- or trigger -- systems at high-throughput scientific facilities such as the experiments at the Large Hadron Collider (LHC) must process extremely high-rate data streams under stringent bandwidth, latency, and storage constraints. Yet these systems are typically designed as static, hand-tuned menus of selection criteria grounded in prior knowledge and simulation. In this work, we further explore the concept of a self-driving trigger, an autonomous data-filtering framework that reallocates resources and adjusts thresholds dynamically in real-time to optimize signal efficiency, rate stability, and computational cost as instrumentation and environmental conditions evolve. We introduce a benchmark ecosystem to emulate realistic collider scenarios and demonstrate real-time optimization of a menu including canonical energy sum triggers as well as modern anomaly-detection algorithms that target non-standard event topologies using machine learning. Using simulated data streams and publicly available collision data from the Compact Muon Solenoid (CMS) experiment, we demonstrate the capability to dynamically and automatically optimize trigger performance under specific cost objectives without manual retuning. Our adaptive strategy shifts trigger design from static menus with heuristic tuning to intelligent, automated, data-driven control, unlocking greater flexibility and discovery potential in future high-energy physics analyses.
Navigation Around Unknown Space Objects Using Visible-Thermal Image Fusion
Dec 13, 2025As the popularity of on-orbit operations grows, so does the need for precise navigation around unknown resident space objects (RSOs) such as other spacecraft, orbital debris, and asteroids. The use of Simultaneous Localization and Mapping (SLAM) algorithms is often studied as a method to map out the surface of an RSO and find the inspector's relative pose using a lidar or conventional camera. However, conventional cameras struggle during eclipse or shadowed periods, and lidar, though robust to lighting conditions, tends to be heavier, bulkier, and more power-intensive. Thermal-infrared cameras can track the target RSO throughout difficult illumination conditions without these limitations. While useful, thermal-infrared imagery lacks the resolution and feature-richness of visible cameras. In this work, images of a target satellite in low Earth orbit are photo-realistically simulated in both visible and thermal-infrared bands. Pixel-level fusion methods are used to create visible/thermal-infrared composites that leverage the best aspects of each camera. Navigation errors from a monocular SLAM algorithm are compared between visible, thermal-infrared, and fused imagery in various lighting and trajectories. Fused imagery yields substantially improved navigation performance over visible-only and thermal-only methods.
Explainable Equivariant Neural Networks for Particle Physics: PELICAN
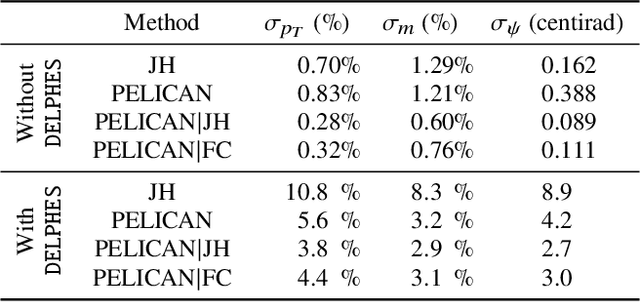
Jul 31, 2023We present a comprehensive study of the PELICAN machine learning algorithm architecture in the context of both tagging (classification) and reconstructing (regression) Lorentz-boosted top quarks, including the difficult task of specifically identifying and measuring the $W$-boson inside the dense environment of the boosted hadronic final state. PELICAN is a novel permutation equivariant and Lorentz invariant or covariant aggregator network designed to overcome common limitations found in architectures applied to particle physics problems. Compared to many approaches that use non-specialized architectures that neglect underlying physics principles and require very large numbers of parameters, PELICAN employs a fundamentally symmetry group-based architecture that demonstrates benefits in terms of reduced complexity, increased interpretability, and raw performance. When tested on the standard task of Lorentz-boosted top quark tagging, PELICAN outperforms existing competitors with much lower model complexity and high sample efficiency. On the less common and more complex task of four-momentum regression, PELICAN also outperforms hand-crafted algorithms. We discuss the implications of symmetry-restricted architectures for the wider field of machine learning for physics.
PELICAN: Permutation Equivariant and Lorentz Invariant or Covariant Aggregator Network for Particle Physics
Nov 01, 2022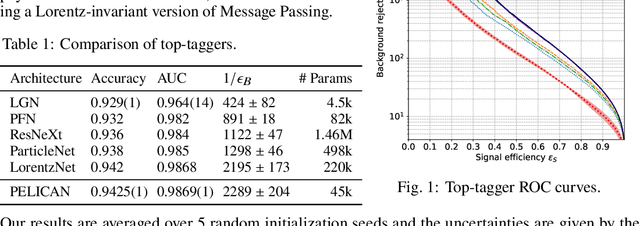
Many current approaches to machine learning in particle physics use generic architectures that require large numbers of parameters and disregard underlying physics principles, limiting their applicability as scientific modeling tools. In this work, we present a machine learning architecture that uses a set of inputs maximally reduced with respect to the full 6-dimensional Lorentz symmetry, and is fully permutation-equivariant throughout. We study the application of this network architecture to the standard task of top quark tagging and show that the resulting network outperforms all existing competitors despite much lower model complexity. In addition, we present a Lorentz-covariant variant of the same network applied to a 4-momentum regression task.
Innovations in trigger and data acquisition systems for next-generation physics facilities
Mar 17, 2022Data-intensive physics facilities are increasingly reliant on heterogeneous and large-scale data processing and computational systems in order to collect, distribute, process, filter, and analyze the ever increasing huge volumes of data being collected. Moreover, these tasks are often performed in hard real-time or quasi real-time processing pipelines that place extreme constraints on various parameters and design choices for those systems. Consequently, a large number and variety of challenges are faced to design, construct, and operate such facilities. This is especially true at the energy and intensity frontiers of particle physics where bandwidths of raw data can exceed 100 TB/s of heterogeneous, high-dimensional data sourced from 300M+ individual sensors. Data filtering and compression algorithms deployed at these facilities often operate at the level of 1 part in $10^5$, and once executed, these algorithms drive the data curation process, further highlighting the critical roles that these systems have in the physics impact of those endeavors. This White Paper aims to highlight the challenges that these facilities face in the design of the trigger and data acquisition instrumentation and systems, as well as in their installation, commissioning, integration and operation, and in building the domain knowledge and technical expertise required to do so.
Symmetry Group Equivariant Architectures for Physics
Mar 11, 2022
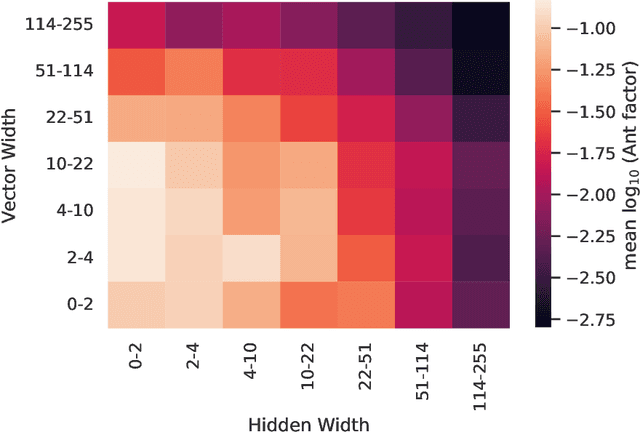
Physical theories grounded in mathematical symmetries are an essential component of our understanding of a wide range of properties of the universe. Similarly, in the domain of machine learning, an awareness of symmetries such as rotation or permutation invariance has driven impressive performance breakthroughs in computer vision, natural language processing, and other important applications. In this report, we argue that both the physics community and the broader machine learning community have much to understand and potentially to gain from a deeper investment in research concerning symmetry group equivariant machine learning architectures. For some applications, the introduction of symmetries into the fundamental structural design can yield models that are more economical (i.e. contain fewer, but more expressive, learned parameters), interpretable (i.e. more explainable or directly mappable to physical quantities), and/or trainable (i.e. more efficient in both data and computational requirements). We discuss various figures of merit for evaluating these models as well as some potential benefits and limitations of these methods for a variety of physics applications. Research and investment into these approaches will lay the foundation for future architectures that are potentially more robust under new computational paradigms and will provide a richer description of the physical systems to which they are applied.
The RATTLE Motion Planning Algorithm for Robust Online Parametric Model Improvement with On-Orbit Validation
Mar 03, 2022
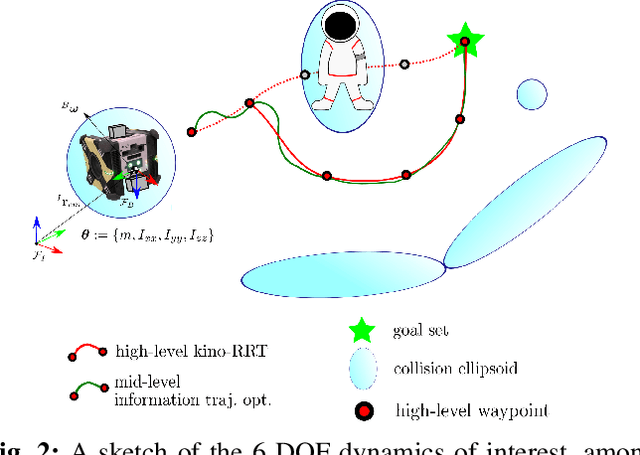
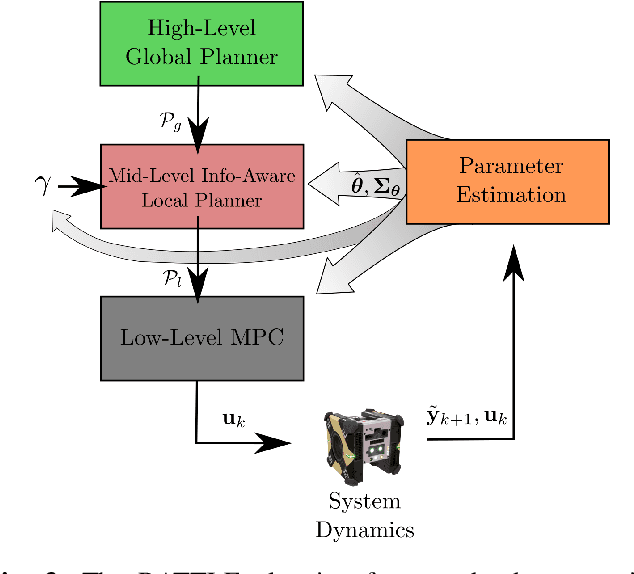
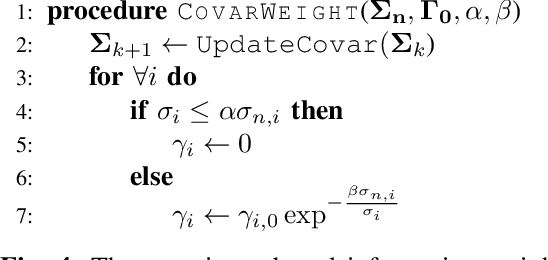
Certain forms of uncertainty that robotic systems encounter can be explicitly learned within the context of a known model, like parametric model uncertainties such as mass and moments of inertia. Quantifying such parametric uncertainty is important for more accurate prediction of the system behavior, leading to safe and precise task execution. In tandem, providing a form of robustness guarantee against prevailing uncertainty levels like environmental disturbances and current model knowledge is also desirable. To that end, the authors' previously proposed RATTLE algorithm, a framework for online information-aware motion planning, is outlined and extended to enhance its applicability to real robotic systems. RATTLE provides a clear tradeoff between information-seeking motion and traditional goal-achieving motion and features online-updateable models. Additionally, online-updateable low level control robustness guarantees and a new method for automatic adjustment of information content down to a specified estimation precision is proposed. Results of extensive experimentation in microgravity using the Astrobee robots aboard the International Space Station and practical implementation details are presented, demonstrating RATTLE's capabilities for real-time, robust, online-updateable, and model information-seeking motion planning capabilities under parametric uncertainty.
Online Information-Aware Motion Planning with Inertial Parameter Learning for Robotic Free-Flyers
Dec 11, 2021
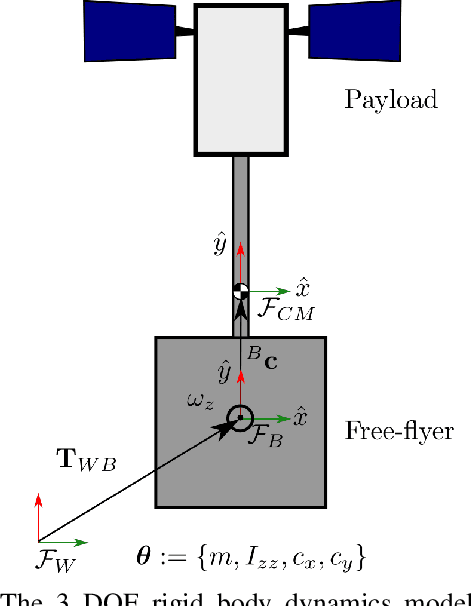
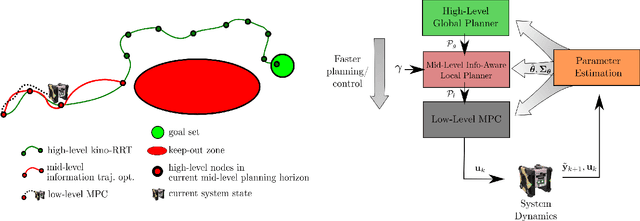

Space free-flyers like the Astrobee robots currently operating aboard the International Space Station must operate with inherent system uncertainties. Parametric uncertainties like mass and moment of inertia are especially important to quantify in these safety-critical space systems and can change in scenarios such as on-orbit cargo movement, where unknown grappled payloads significantly change the system dynamics. Cautiously learning these uncertainties en route can potentially avoid time- and fuel-consuming pure system identification maneuvers. Recognizing this, this work proposes RATTLE, an online information-aware motion planning algorithm that explicitly weights parametric model-learning coupled with real-time replanning capability that can take advantage of improved system models. The method consists of a two-tiered (global and local) planner, a low-level model predictive controller, and an online parameter estimator that produces estimates of the robot's inertial properties for more informed control and replanning on-the-fly; all levels of the planning and control feature online update-able models. Simulation results of RATTLE for the Astrobee free-flyer grappling an uncertain payload are presented alongside results of a hardware demonstration showcasing the ability to explicitly encourage model parametric learning while achieving otherwise useful motion.
Towards an Interpretable Data-driven Trigger System for High-throughput Physics Facilities
Apr 14, 2021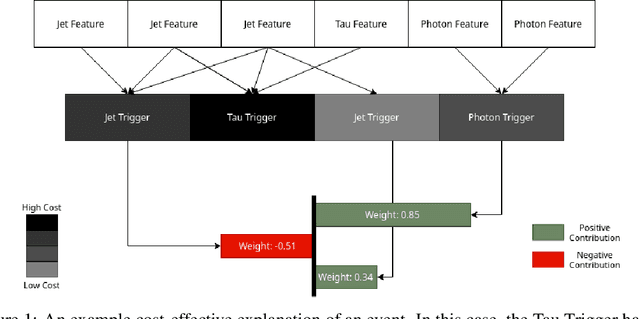
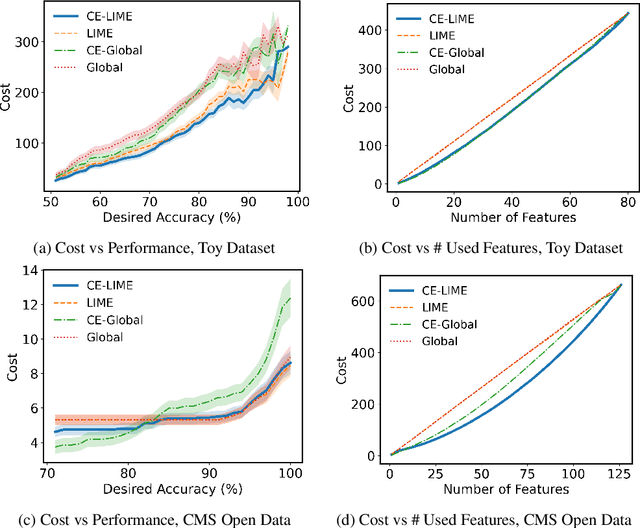
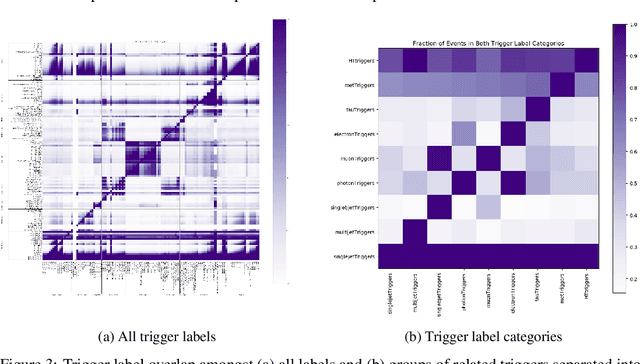
Data-intensive science is increasingly reliant on real-time processing capabilities and machine learning workflows, in order to filter and analyze the extreme volumes of data being collected. This is especially true at the energy and intensity frontiers of particle physics where bandwidths of raw data can exceed 100 Tb/s of heterogeneous, high-dimensional data sourced from hundreds of millions of individual sensors. In this paper, we introduce a new data-driven approach for designing and optimizing high-throughput data filtering and trigger systems such as those in use at physics facilities like the Large Hadron Collider (LHC). Concretely, our goal is to design a data-driven filtering system with a minimal run-time cost for determining which data event to keep, while preserving (and potentially improving upon) the distribution of the output as generated by the hand-designed trigger system. We introduce key insights from interpretable predictive modeling and cost-sensitive learning in order to account for non-local inefficiencies in the current paradigm and construct a cost-effective data filtering and trigger model that does not compromise physics coverage.
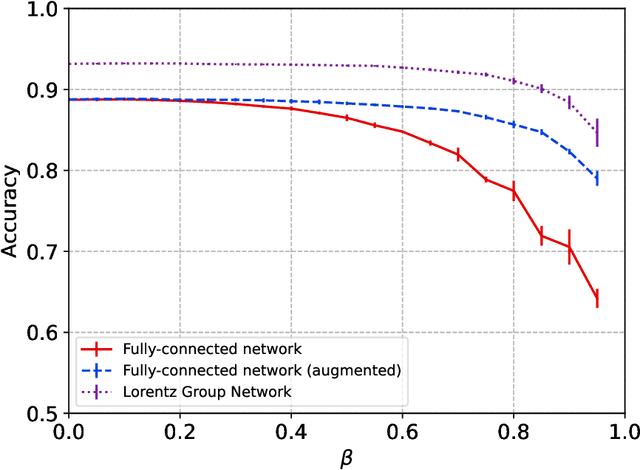
Lorentz Group Equivariant Neural Network for Particle Physics
Jun 08, 2020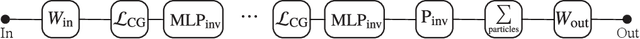
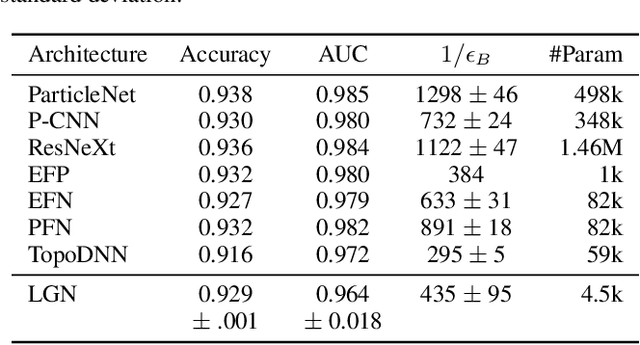
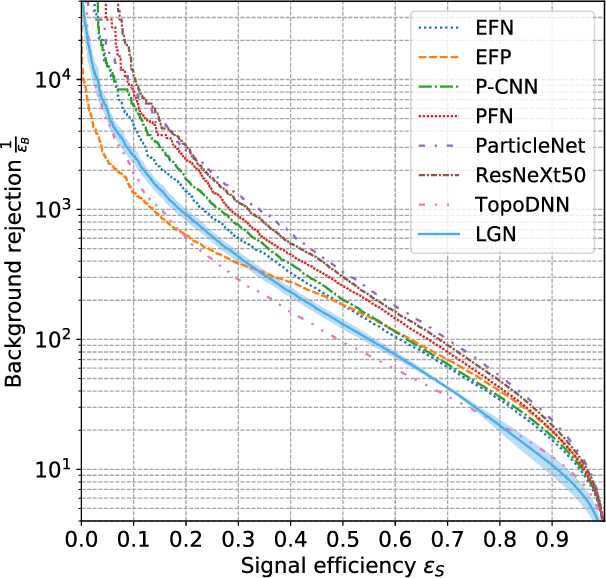
We present a neural network architecture that is fully equivariant with respect to transformations under the Lorentz group, a fundamental symmetry of space and time in physics. The architecture is based on the theory of the finite-dimensional representations of the Lorentz group and the equivariant nonlinearity involves the tensor product. For classification tasks in particle physics, we demonstrate that such an equivariant architecture leads to drastically simpler models that have relatively few learnable parameters and are much more physically interpretable than leading approaches that use CNNs and point cloud approaches. The competitive performance of the network is demonstrated on a public classification dataset [27] for tagging top quark decays given energy-momenta of jet constituents produced in proton-proton collisions.