 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Evolutionary Trajectory Generator: A General Approach for Quadrupedal Locomotion
Sep 16, 2021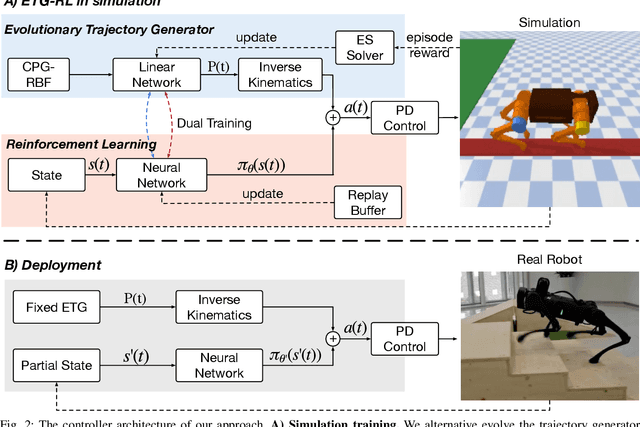
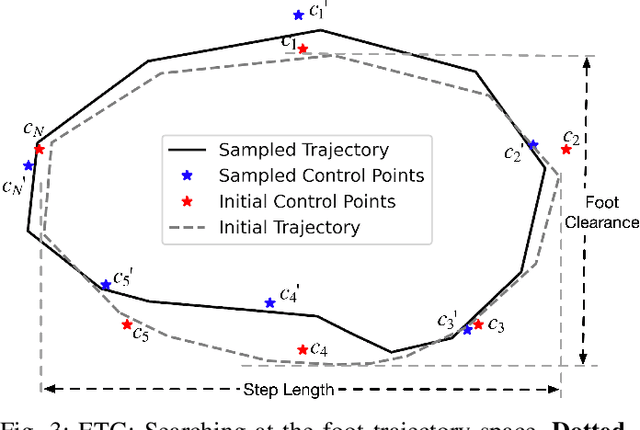
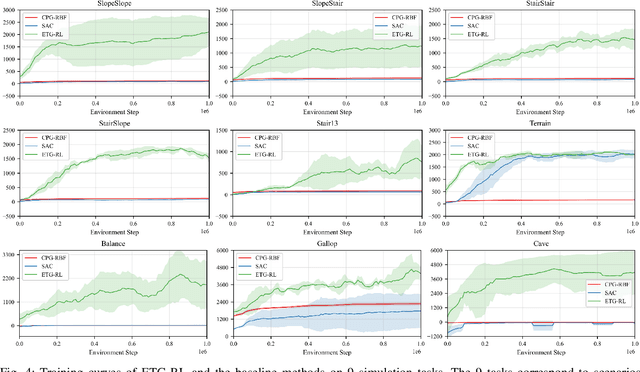
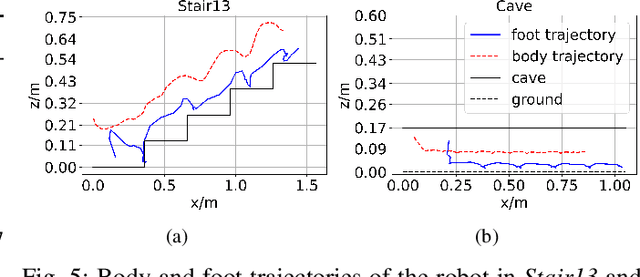
Recently reinforcement learning (RL) has emerged as a promising approach for quadrupedal locomotion, which can save the manual effort in conventional approaches such as designing skill-specific controllers. However, due to the complex nonlinear dynamics in quadrupedal robots and reward sparsity, it is still difficult for RL to learn effective gaits from scratch, especially in challenging tasks such as walking over the balance beam. To alleviate such difficulty, we propose a novel RL-based approach that contains an evolutionary foot trajectory generator. Unlike prior methods that use a fixed trajectory generator, the generator continually optimizes the shape of the output trajectory for the given task, providing diversified motion priors to guide the policy learning. The policy is trained with reinforcement learning to output residual control signals that fit different gaits. We then optimize the trajectory generator and policy network alternatively to stabilize the training and share the exploratory data to improve sample efficiency. As a result, our approach can solve a range of challenging tasks in simulation by learning from scratch, including walking on a balance beam and crawling through the cave. To further verify the effectiveness of our approach, we deploy the controller learned in the simulation on a 12-DoF quadrupedal robot, and it can successfully traverse challenging scenarios with efficient gaits.
Proactive Interaction Framework for Intelligent Social Receptionist Robots
Dec 09, 2020
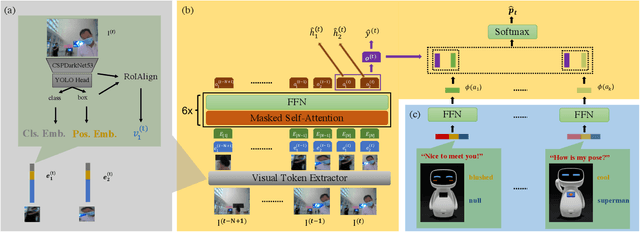

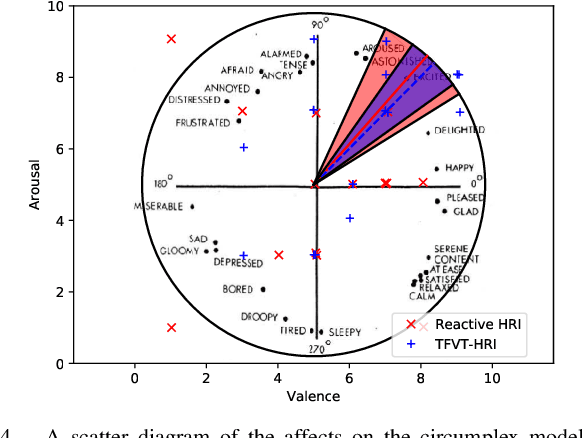
Proactive human-robot interaction (HRI) allows the receptionist robots to actively greet people and offer services based on vision, which has been found to improve acceptability and customer satisfaction. Existing approaches are either based on multi-stage decision processes or based on end-to-end decision models. However, the rule-based approaches require sedulous expert efforts and only handle minimal pre-defined scenarios. On the other hand, existing works with end-to-end models are limited to very general greetings or few behavior patterns (typically less than 10). To address those challenges, we propose a new end-to-end framework, the TransFormer with Visual Tokens for Human-Robot Interaction (TFVT-HRI). The proposed framework extracts visual tokens of relative objects from an RGB camera first. To ensure the correct interpretation of the scenario, a transformer decision model is then employed to process the visual tokens, which is augmented with the temporal and spatial information. It predicts the appropriate action to take in each scenario and identifies the right target. Our data is collected from an in-service receptionist robot in an office building, which is then annotated by experts for appropriate proactive behavior. The action set includes 1000+ diverse patterns by combining language, emoji expression, and body motions. We compare our model with other SOTA end-to-end models on both offline test sets and online user experiments in realistic office building environments to validate this framework. It is demonstrated that the decision model achieves SOTA performance in action triggering and selection, resulting in more humanness and intelligence when compared with the previous reactive reception policies.
Intervention Aided Reinforcement Learning for Safe and Practical Policy Optimization in Navigation
Nov 15, 2018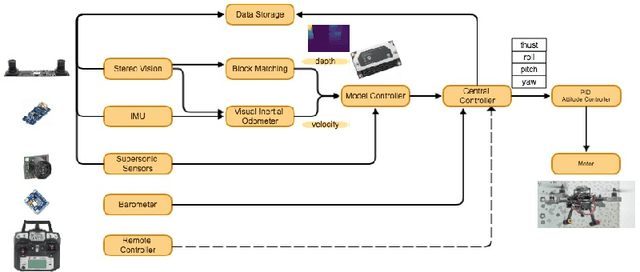

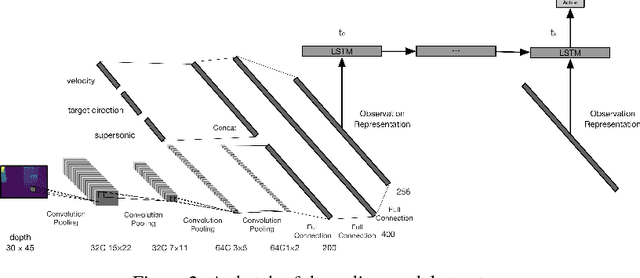
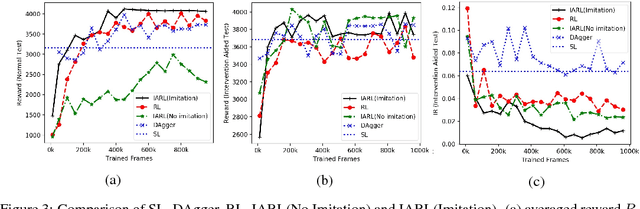
Combining deep neural networks with reinforcement learning has shown great potential in the next-generation intelligent control. However, there are challenges in terms of safety and cost in practical applications. In this paper, we propose the Intervention Aided Reinforcement Learning (IARL) framework, which utilizes human intervened robot-environment interaction to improve the policy. We used the Unmanned Aerial Vehicle (UAV) as the test platform. We built neural networks as our policy to map sensor readings to control signals on the UAV. Our experiment scenarios cover both simulation and reality. We show that our approach substantially reduces the human intervention and improves the performance in autonomous navigation, at the same time it ensures safety and keeps training cost acceptable.