 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechNet: Weakly Supervised, End-to-End Speech Recognition at Industrial Scale
Nov 21, 2022


End-to-end automatic speech recognition systems represent the state of the art, but they rely on thousands of hours of manually annotated speech for training, as well as heavyweight computation for inference. Of course, this impedes commercialization since most companies lack vast human and computational resources. In this paper, we explore training and deploying an ASR system in the label-scarce, compute-limited setting. To reduce human labor, we use a third-party ASR system as a weak supervision source, supplemented with labeling functions derived from implicit user feedback. To accelerate inference, we propose to route production-time queries across a pool of CUDA graphs of varying input lengths, the distribution of which best matches the traffic's. Compared to our third-party ASR, we achieve a relative improvement in word-error rate of 8% and a speedup of 600%. Our system, called SpeechNet, currently serves 12 million queries per day on our voice-enabled smart television. To our knowledge, this is the first time a large-scale, Wav2vec-based deployment has been described in the academic literature.
End-to-end Deep Object Tracking with Circular Loss Function for Rotated Bounding Box
Dec 17, 2020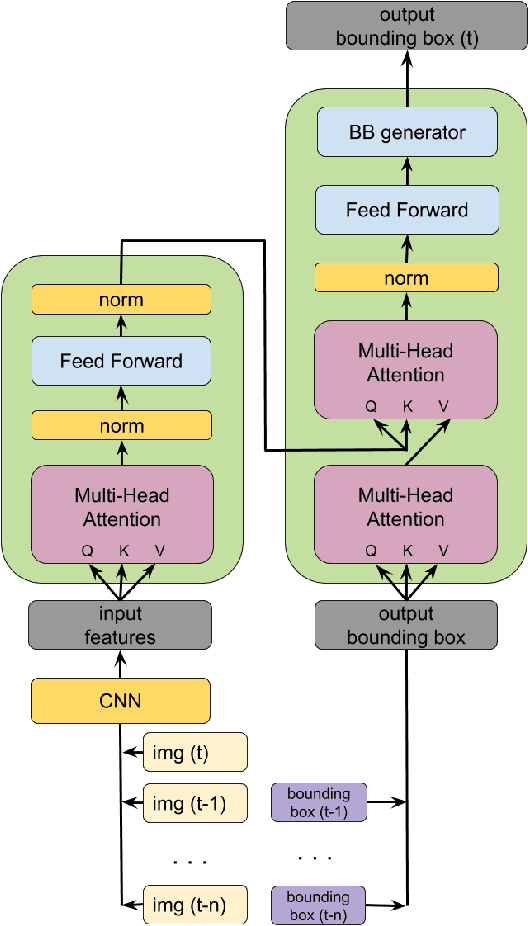
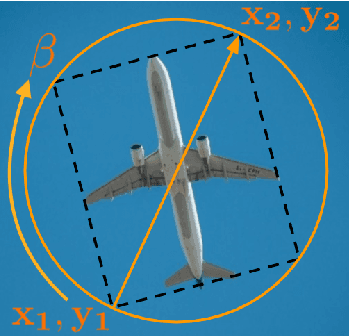
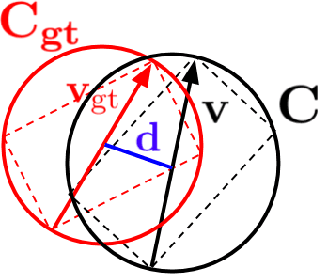

The task object tracking is vital in numerous applications such as autonomous driving, intelligent surveillance, robotics, etc. This task entails the assigning of a bounding box to an object in a video stream, given only the bounding box for that object on the first frame. In 2015, a new type of video object tracking (VOT) dataset was created that introduced rotated bounding boxes as an extension of axis-aligned ones. In this work, we introduce a novel end-to-end deep learning method based on the Transformer Multi-Head Attention architecture. We also present a new type of loss function, which takes into account the bounding box overlap and orientation. Our Deep Object Tracking model with Circular Loss Function (DOTCL) shows an considerable improvement in terms of robustness over current state-of-the-art end-to-end deep learning models. It also outperforms state-of-the-art object tracking methods on VOT2018 dataset in terms of expected average overlap (EAO) metric.