 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechNet: Weakly Supervised, End-to-End Speech Recognition at Industrial Scale
Nov 21, 2022


End-to-end automatic speech recognition systems represent the state of the art, but they rely on thousands of hours of manually annotated speech for training, as well as heavyweight computation for inference. Of course, this impedes commercialization since most companies lack vast human and computational resources. In this paper, we explore training and deploying an ASR system in the label-scarce, compute-limited setting. To reduce human labor, we use a third-party ASR system as a weak supervision source, supplemented with labeling functions derived from implicit user feedback. To accelerate inference, we propose to route production-time queries across a pool of CUDA graphs of varying input lengths, the distribution of which best matches the traffic's. Compared to our third-party ASR, we achieve a relative improvement in word-error rate of 8% and a speedup of 600%. Our system, called SpeechNet, currently serves 12 million queries per day on our voice-enabled smart television. To our knowledge, this is the first time a large-scale, Wav2vec-based deployment has been described in the academic literature.
What the DAAM: Interpreting Stable Diffusion Using Cross Attention
Oct 11, 2022
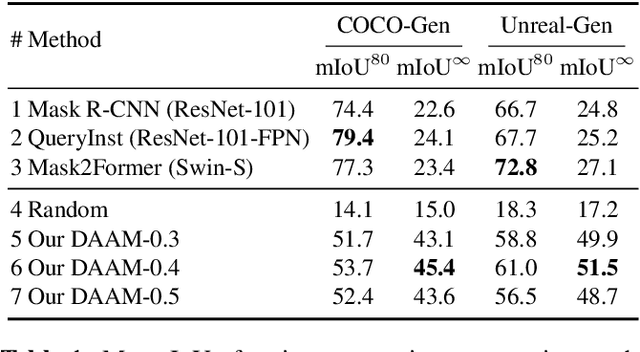
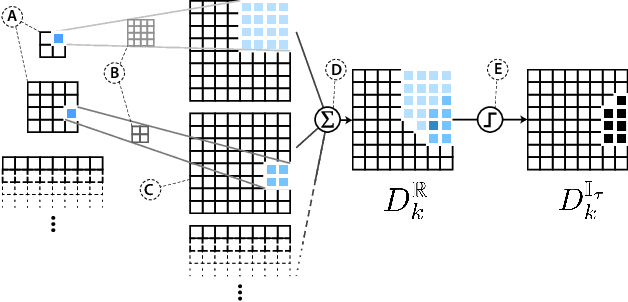

Large-scale diffusion neural networks represent a substantial milestone in text-to-image generation, with some performing similar to real photographs in human evaluation. However, they remain poorly understood, lacking explainability and interpretability analyses, largely due to their proprietary, closed-source nature. In this paper, to shine some much-needed light on text-to-image diffusion models, we perform a text-image attribution analysis on Stable Diffusion, a recently open-sourced large diffusion model. To produce pixel-level attribution maps, we propose DAAM, a novel method based on upscaling and aggregating cross-attention activations in the latent denoising subnetwork. We support its correctness by evaluating its unsupervised semantic segmentation quality on its own generated imagery, compared to supervised segmentation models. We show that DAAM performs strongly on COCO caption-generated images, achieving an mIoU of 61.0, and it outperforms supervised models on open-vocabulary segmentation, for an mIoU of 51.5. We further find that certain parts of speech, like punctuation and conjunctions, influence the generated imagery most, which agrees with the prior literature, while determiners and numerals the least, suggesting poor numeracy. To our knowledge, we are the first to propose and study word-pixel attribution for large-scale text-to-image diffusion models. Our code and data are at https://github.com/castorini/daam.
Iterative Effect-Size Bias in Ridehailing: Measuring Social Bias in Dynamic Pricing of 100 Million Rides
Jun 22, 2020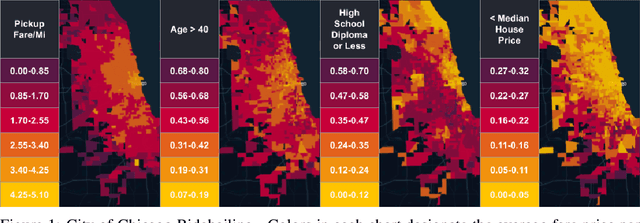
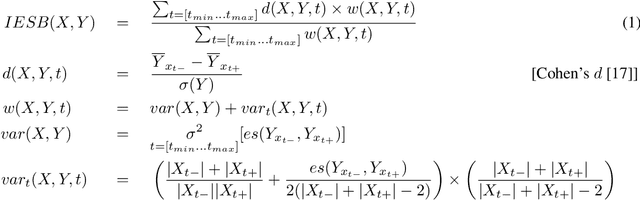
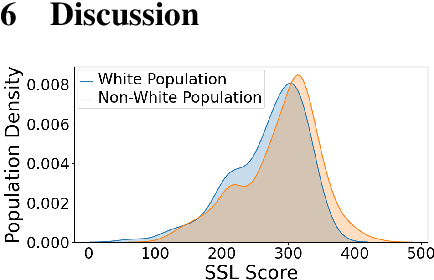
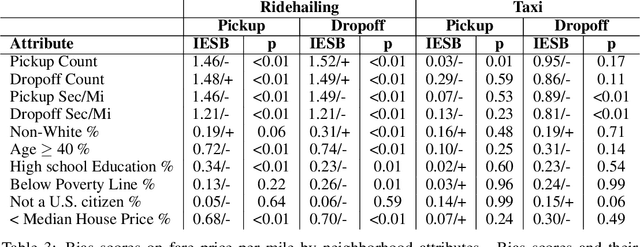
Algorithmic bias is the systematic preferential or discriminatory treatment of a group of people by an artificial intelligence system. In this work we develop a random-effects based metric for the analysis of social bias in supervised machine learning prediction models where model outputs depend on U.S. locations. We define a methodology for using U.S. Census data to measure social bias on user attributes legally protected against discrimination, such as ethnicity, sex, and religion, also known as protected attributes. We evaluate our method on the Strategic Subject List (SSL) gun-violence prediction dataset, where we have access to both U.S. Census data as well as ground truth protected attributes for 224,235 individuals in Chicago being assessed for participation in future gun-violence incidents. Our results indicate that quantifying social bias using U.S. Census data provides a valid approach to auditing a supervised algorithmic decision-making system. Using our methodology, we then quantify the potential social biases of 100 million ridehailing samples in the city of Chicago. This work is the first large-scale fairness analysis of the dynamic pricing algorithms used by ridehailing applications. An analysis of Chicago ridehailing samples in conjunction with American Community Survey data indicates possible disparate impact due to social bias based on age, house pricing, education, and ethnicity in the dynamic fare pricing models used by ridehailing applications, with effect-sizes of 0.74, 0.70, 0.34, and -0.31 (using Cohen's d) for each demographic respectively. Further, our methodology provides a principled approach to quantifying algorithmic bias on datasets where protected attributes are unavailable, given that U.S. geolocations and algorithmic decisions are provided.
Pro-Russian Biases in Anti-Chinese Tweets about the Novel Coronavirus
Apr 18, 2020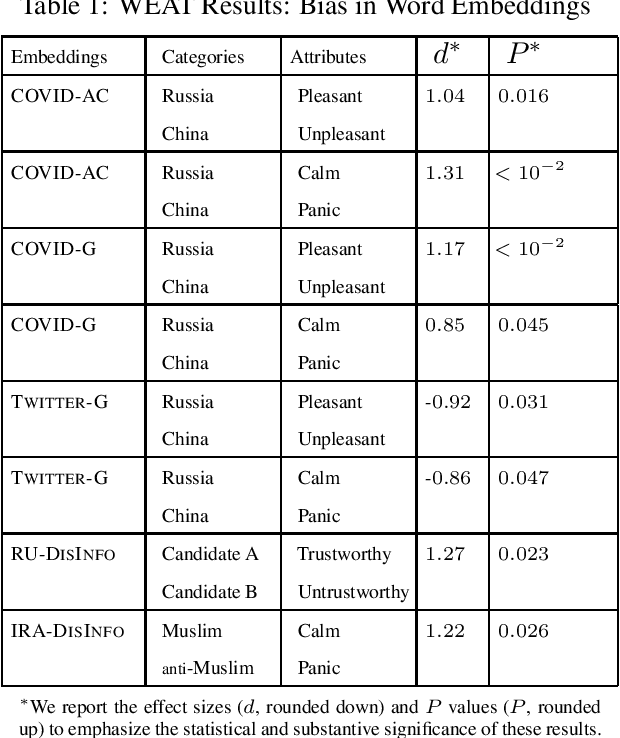
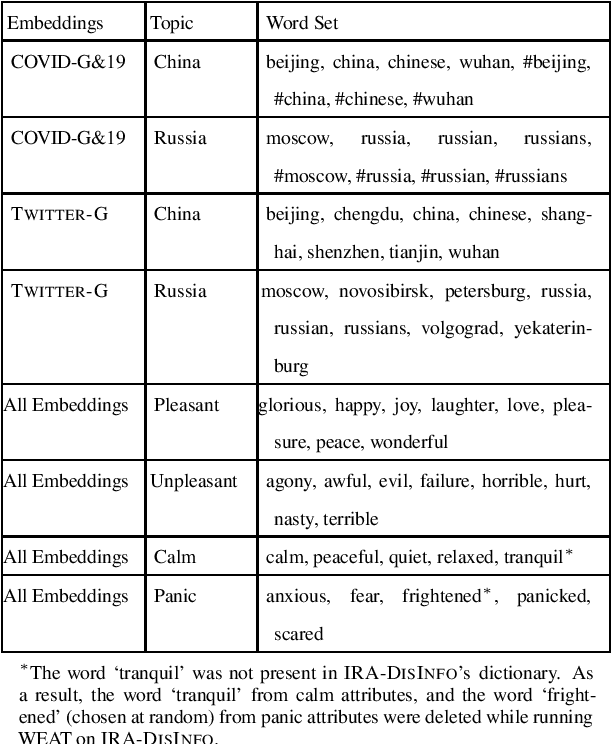
The recent COVID-19 pandemic, which was first detected in Wuhan, China, has been linked to increased anti-Chinese sentiment in the United States. Recently, Broniatowski et al. found that foreign powers, and especially Russia, were implicated in information operations using public health crises to promote discord -- including racial conflict -- in American society (Broniatowski, 2018). This brief considers the problem of automatically detecting changes in overall attitudes, that may be associated with emerging information operations, via artificial intelligence. Accurate analysis of these emerging topics usually requires laborious, manual analysis by experts to annotate millions of tweets to identify biases in new topics. We introduce extensions of the Word Embedding Association Test from Caliskan et. al to a new domain (Caliskan, 2017). This practical and unsupervised method is applied to quantify biases being promoted in information operations. Analyzing historical information operations from Russia's interference in the 2016 U.S. presidential elections, we quantify biased attitudes for presidential candidates, and sentiment toward Muslim groups. We next apply this method to a corpus of tweets containing anti-Chinese hashtags. We find that roughly 1% of tweets in our corpus reference Russian-funded news sources and use anti-Chinese hashtags and, beyond the expected anti-Chinese attitudes, we find that this corpus as a whole contains pro-Russian attitudes, which are not present in a control Twitter corpus containing general tweets. Additionally, 4% of the users in this corpus were suspended within a week. These findings may indicate the presence of abusive account activity associated with rapid changes in attitudes around the COVID-19 public health crisis, suggesting potential information operations.