 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Effect-Size Bias in Ridehailing: Measuring Social Bias in Dynamic Pricing of 100 Million Rides
Paper and Code
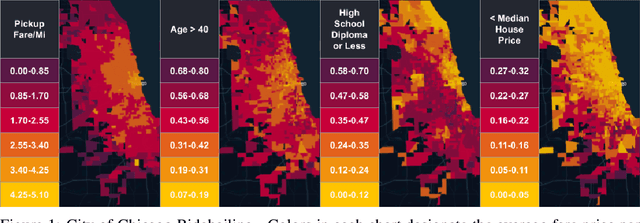
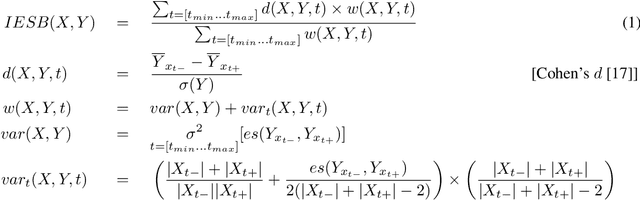
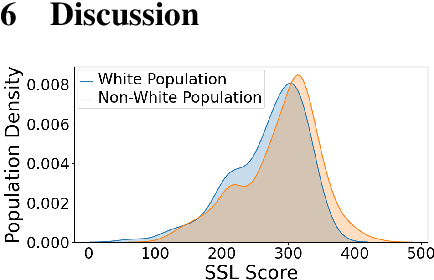
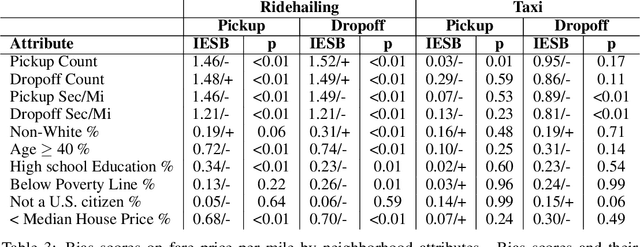
Algorithmic bias is the systematic preferential or discriminatory treatment of a group of people by an artificial intelligence system. In this work we develop a random-effects based metric for the analysis of social bias in supervised machine learning prediction models where model outputs depend on U.S. locations. We define a methodology for using U.S. Census data to measure social bias on user attributes legally protected against discrimination, such as ethnicity, sex, and religion, also known as protected attributes. We evaluate our method on the Strategic Subject List (SSL) gun-violence prediction dataset, where we have access to both U.S. Census data as well as ground truth protected attributes for 224,235 individuals in Chicago being assessed for participation in future gun-violence incidents. Our results indicate that quantifying social bias using U.S. Census data provides a valid approach to auditing a supervised algorithmic decision-making system. Using our methodology, we then quantify the potential social biases of 100 million ridehailing samples in the city of Chicago. This work is the first large-scale fairness analysis of the dynamic pricing algorithms used by ridehailing applications. An analysis of Chicago ridehailing samples in conjunction with American Community Survey data indicates possible disparate impact due to social bias based on age, house pricing, education, and ethnicity in the dynamic fare pricing models used by ridehailing applications, with effect-sizes of 0.74, 0.70, 0.34, and -0.31 (using Cohen's d) for each demographic respectively. Further, our methodology provides a principled approach to quantifying algorithmic bias on datasets where protected attributes are unavailable, given that U.S. geolocations and algorithmic decisions are provided.