 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeechNet: Weakly Supervised, End-to-End Speech Recognition at Industrial Scale
Nov 21, 2022


End-to-end automatic speech recognition systems represent the state of the art, but they rely on thousands of hours of manually annotated speech for training, as well as heavyweight computation for inference. Of course, this impedes commercialization since most companies lack vast human and computational resources. In this paper, we explore training and deploying an ASR system in the label-scarce, compute-limited setting. To reduce human labor, we use a third-party ASR system as a weak supervision source, supplemented with labeling functions derived from implicit user feedback. To accelerate inference, we propose to route production-time queries across a pool of CUDA graphs of varying input lengths, the distribution of which best matches the traffic's. Compared to our third-party ASR, we achieve a relative improvement in word-error rate of 8% and a speedup of 600%. Our system, called SpeechNet, currently serves 12 million queries per day on our voice-enabled smart television. To our knowledge, this is the first time a large-scale, Wav2vec-based deployment has been described in the academic literature.
What the DAAM: Interpreting Stable Diffusion Using Cross Attention
Oct 11, 2022
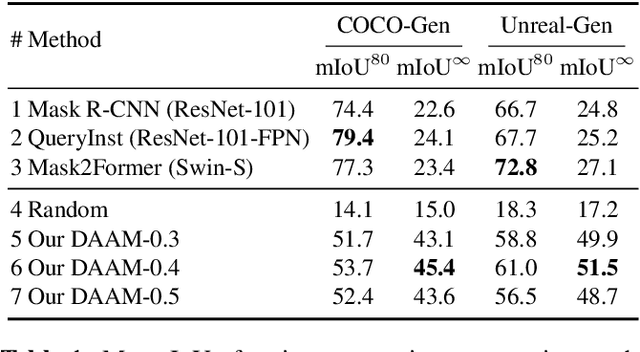
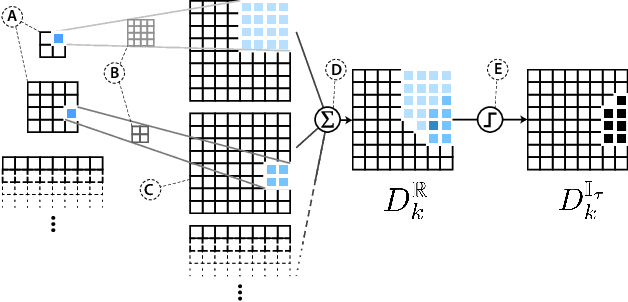

Large-scale diffusion neural networks represent a substantial milestone in text-to-image generation, with some performing similar to real photographs in human evaluation. However, they remain poorly understood, lacking explainability and interpretability analyses, largely due to their proprietary, closed-source nature. In this paper, to shine some much-needed light on text-to-image diffusion models, we perform a text-image attribution analysis on Stable Diffusion, a recently open-sourced large diffusion model. To produce pixel-level attribution maps, we propose DAAM, a novel method based on upscaling and aggregating cross-attention activations in the latent denoising subnetwork. We support its correctness by evaluating its unsupervised semantic segmentation quality on its own generated imagery, compared to supervised segmentation models. We show that DAAM performs strongly on COCO caption-generated images, achieving an mIoU of 61.0, and it outperforms supervised models on open-vocabulary segmentation, for an mIoU of 51.5. We further find that certain parts of speech, like punctuation and conjunctions, influence the generated imagery most, which agrees with the prior literature, while determiners and numerals the least, suggesting poor numeracy. To our knowledge, we are the first to propose and study word-pixel attribution for large-scale text-to-image diffusion models. Our code and data are at https://github.com/castorini/daam.
Streaming Voice Query Recognition using Causal Convolutional Recurrent Neural Networks
Dec 19, 2018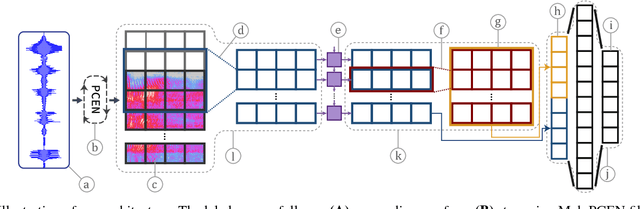
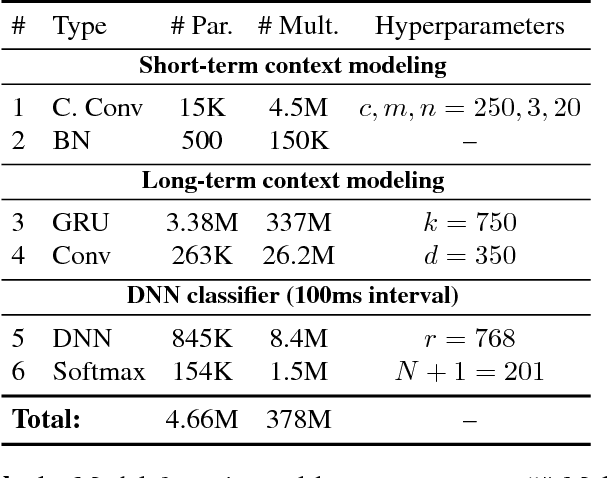
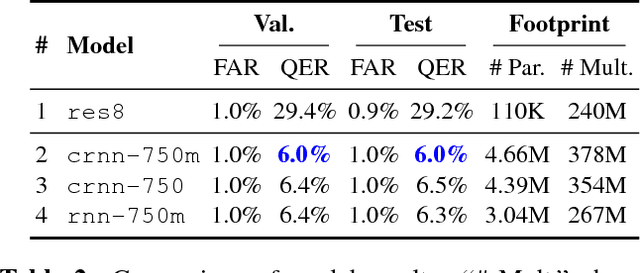
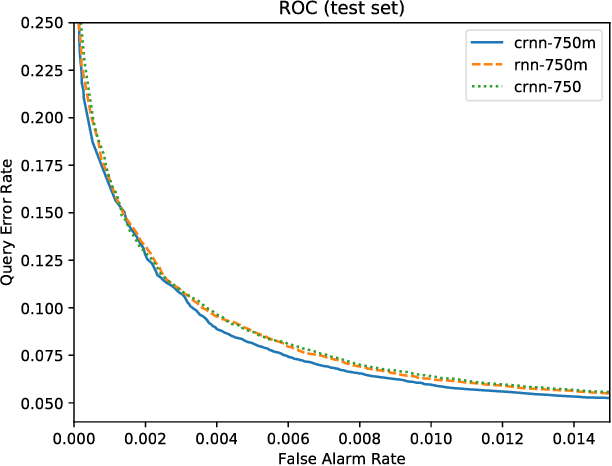
Voice-enabled commercial products are ubiquitous, typically enabled by lightweight on-device keyword spotting (KWS) and full automatic speech recognition (ASR) in the cloud. ASR systems require significant computational resources in training and for inference, not to mention copious amounts of annotated speech data. KWS systems, on the other hand, are less resource-intensive but have limited capabilities. On the Comcast Xfinity X1 entertainment platform, we explore a middle ground between ASR and KWS: We introduce a novel, resource-efficient neural network for voice query recognition that is much more accurate than state-of-the-art CNNs for KWS, yet can be easily trained and deployed with limited resources. On an evaluation dataset representing the top 200 voice queries, we achieve a low false alarm rate of 1% and a query error rate of 6%. Our model performs inference 8.24x faster than the current ASR system.