 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyDL: Polyhedral Optimizations for Creation of High Performance DL primitives
Jun 02, 2020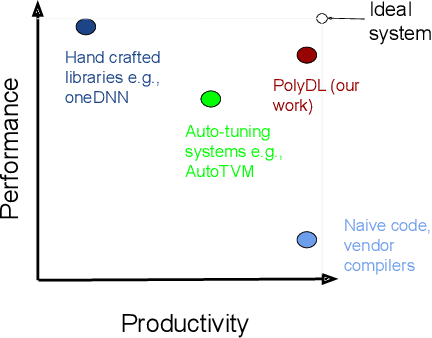
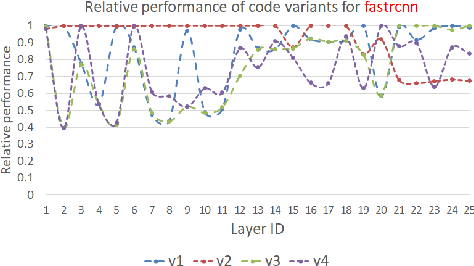
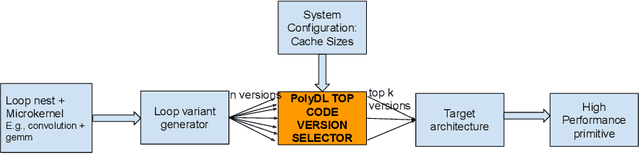

Deep Neural Networks (DNNs) have revolutionized many aspects of our lives. The use of DNNs is becoming ubiquitous including in softwares for image recognition, speech recognition, speech synthesis, language translation, to name a few. he training of DNN architectures however is computationally expensive. Once the model is created, its use in the intended application - the inference task, is computationally heavy too and the inference needs to be fast for real time use. For obtaining high performance today, the code of Deep Learning (DL) primitives optimized for specific architectures by expert programmers exposed via libraries is the norm. However, given the constant emergence of new DNN architectures, creating hand optimized code is expensive, slow and is not scalable. To address this performance-productivity challenge, in this paper we present compiler algorithms to automatically generate high performance implementations of DL primitives that closely match the performance of hand optimized libraries. We develop novel data reuse analysis algorithms using the polyhedral model to derive efficient execution schedules automatically. In addition, because most DL primitives use some variant of matrix multiplication at their core, we develop a flexible framework where it is possible to plug in library implementations of the same in lieu of a subset of the loops. We show that such a hybrid compiler plus a minimal library-use approach results in state-of-the-art performance. We develop compiler algorithms to also perform operator fusions that reduce data movement through the memory hierarchy of the computer system.
PolyScientist: Automatic Loop Transformations Combined with Microkernels for Optimization of Deep Learning Primitives
Feb 06, 2020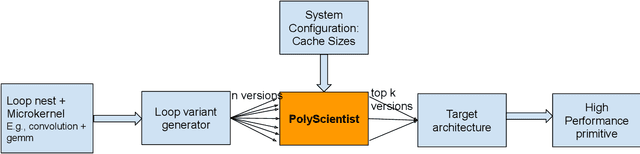
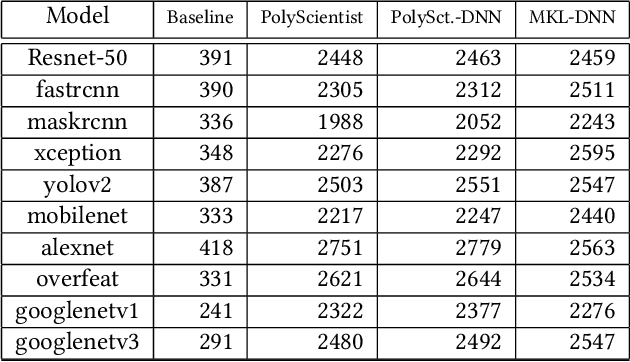
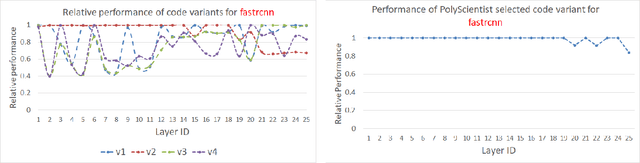

At the heart of deep learning training and inferencing are computationally intensive primitives such as convolutions which form the building blocks of deep neural networks. Researchers have taken two distinct approaches to creating high performance implementations of deep learning kernels, namely, 1) library development exemplified by Intel MKL-DNN for CPUs, 2) automatic compilation represented by the TensorFlow XLA compiler. The two approaches have their drawbacks: even though a custom built library can deliver very good performance, the cost and time of development of the library can be high. Automatic compilation of kernels is attractive but in practice, till date, automatically generated implementations lag expert coded kernels in performance by orders of magnitude. In this paper, we develop a hybrid solution to the development of deep learning kernels that achieves the best of both worlds: the expert coded microkernels are utilized for the innermost loops of kernels and we use the advanced polyhedral technology to automatically tune the outer loops for performance. We design a novel polyhedral model based data reuse algorithm to optimize the outer loops of the kernel. Through experimental evaluation on an important class of deep learning primitives namely convolutions, we demonstrate that the approach we develop attains the same levels of performance as Intel MKL-DNN, a hand coded deep learning library.