 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMicroscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
High Performance Scalable FPGA Accelerator for Deep Neural Networks
Aug 29, 2019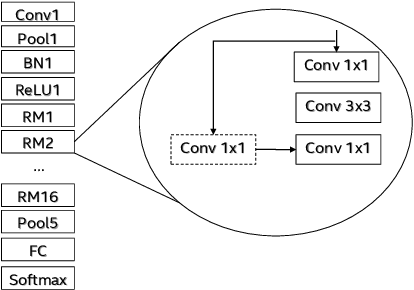
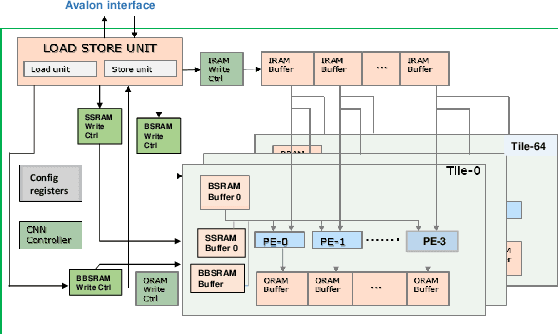
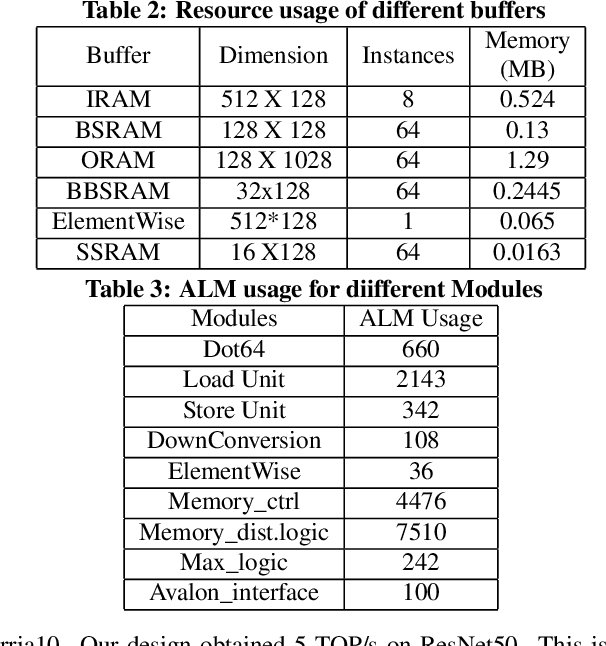
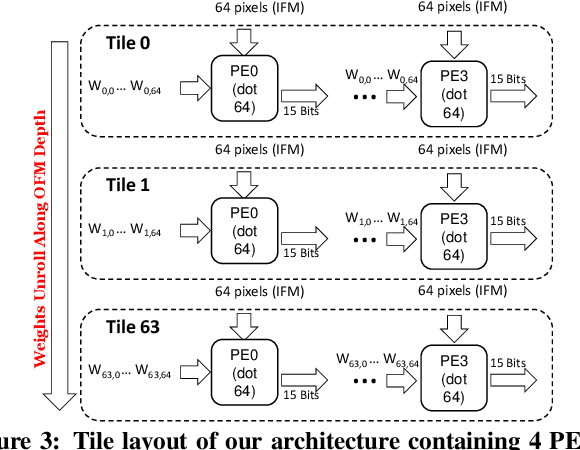
Low-precision is the first order knob for achieving higher Artificial Intelligence Operations (AI-TOPS). However the algorithmic space for sub-8-bit precision compute is diverse, with disruptive changes happening frequently, making FPGAs a natural choice for Deep Neural Network inference, In this work we present an FPGA-based accelerator for CNN inference acceleration. We use {\it INT-8-2} compute (with {\it 8 bit} activation and {2 bit} weights) which is recently showing promise in the literature, and which no known ASIC, CPU or GPU natively supports today. Using a novel Adaptive Logic Module (ALM) based design, as a departure from traditional DSP based designs, we are able to achieve high performance measurement of 5 AI-TOPS for {\it Arria10} and project a performance of 76 AI-TOPS at 0.7 TOPS/W for {\it Stratix10}. This exceeds known CPU, GPU performance and comes close to best known ASIC (TPU) numbers, while retaining the versatility of the FPGA platform for other applications.