 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Stage Huffman Encoder for ML Compression
Jan 15, 2026Training and serving Large Language Models (LLMs) require partitioning data across multiple accelerators, where collective operations are frequently bottlenecked by network bandwidth. Lossless compression using Huffman codes is an effective way to alleviate the issue, however, its three-stage design requiring on-the-fly frequency analysis, codebook generation and transmission of codebook along with data introduces computational, latency and data overheads which are prohibitive for latency-sensitive scenarios such as die-to-die communication. This paper proposes a single-stage Huffman encoder that eliminates these overheads by using fixed codebooks derived from the average probability distribution of previous data batches. Through our analysis of the Gemma 2B model, we demonstrate that tensors exhibit high statistical similarity across layers and shards. Using this approach we achieve compression within 0.5% of per-shard Huffman coding and within 1% of the ideal Shannon compressibility, enabling efficient on-the-fly compression.
High Performance Scalable FPGA Accelerator for Deep Neural Networks
Aug 29, 2019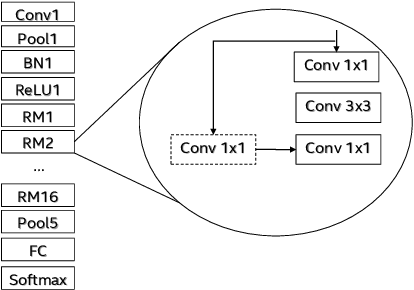
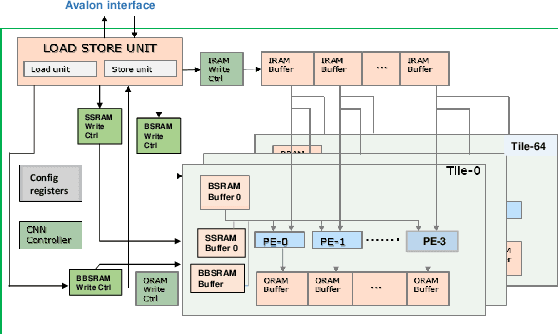
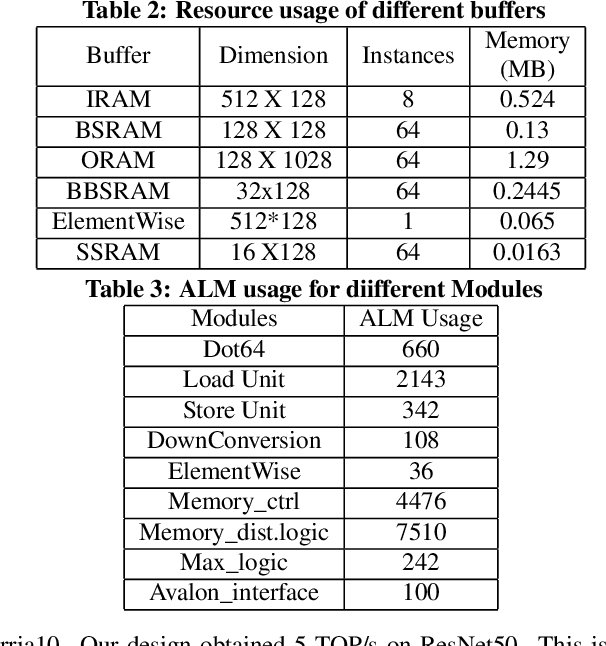
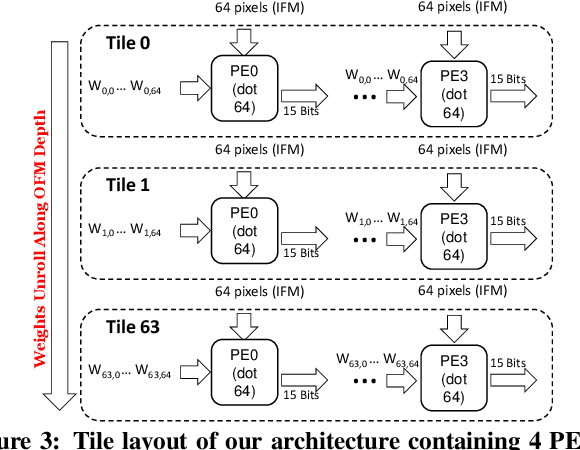
Low-precision is the first order knob for achieving higher Artificial Intelligence Operations (AI-TOPS). However the algorithmic space for sub-8-bit precision compute is diverse, with disruptive changes happening frequently, making FPGAs a natural choice for Deep Neural Network inference, In this work we present an FPGA-based accelerator for CNN inference acceleration. We use {\it INT-8-2} compute (with {\it 8 bit} activation and {2 bit} weights) which is recently showing promise in the literature, and which no known ASIC, CPU or GPU natively supports today. Using a novel Adaptive Logic Module (ALM) based design, as a departure from traditional DSP based designs, we are able to achieve high performance measurement of 5 AI-TOPS for {\it Arria10} and project a performance of 76 AI-TOPS at 0.7 TOPS/W for {\it Stratix10}. This exceeds known CPU, GPU performance and comes close to best known ASIC (TPU) numbers, while retaining the versatility of the FPGA platform for other applications.