 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepClean: Machine Unlearning on the Cheap by Resetting Privacy Sensitive Weights using the Fisher Diagonal
Paper and Code
Nov 17, 2023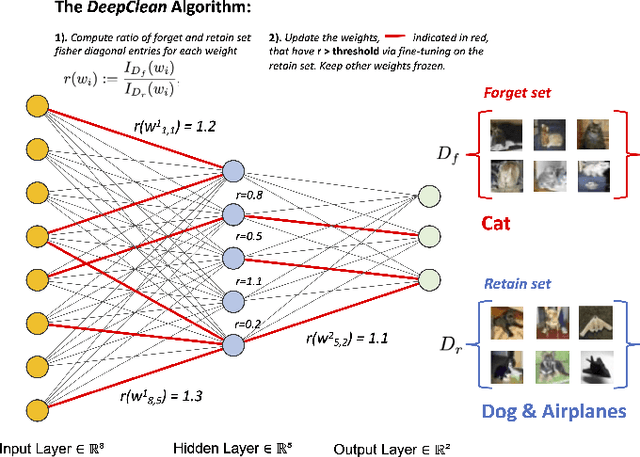
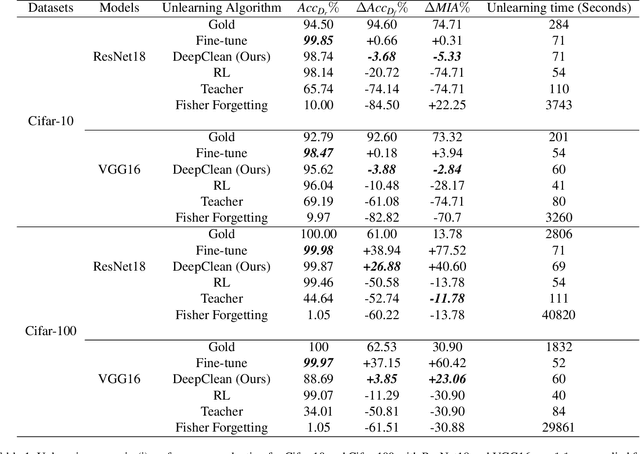
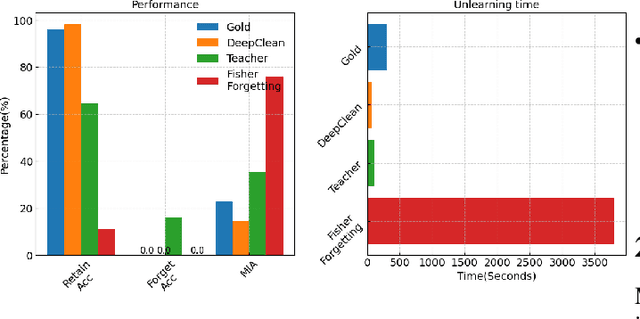
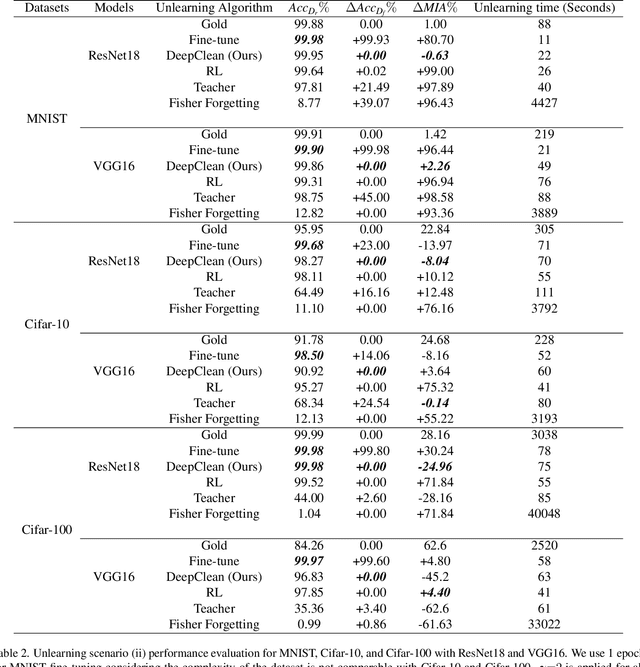
Machine learning models trained on sensitive or private data can inadvertently memorize and leak that information. Machine unlearning seeks to retroactively remove such details from model weights to protect privacy. We contribute a lightweight unlearning algorithm that leverages the Fisher Information Matrix (FIM) for selective forgetting. Prior work in this area requires full retraining or large matrix inversions, which are computationally expensive. Our key insight is that the diagonal elements of the FIM, which measure the sensitivity of log-likelihood to changes in weights, contain sufficient information for effective forgetting. Specifically, we compute the FIM diagonal over two subsets -- the data to retain and forget -- for all trainable weights. This diagonal representation approximates the complete FIM while dramatically reducing computation. We then use it to selectively update weights to maximize forgetting of the sensitive subset while minimizing impact on the retained subset. Experiments show that our algorithm can successfully forget any randomly selected subsets of training data across neural network architectures. By leveraging the FIM diagonal, our approach provides an interpretable, lightweight, and efficient solution for machine unlearning with practical privacy benefits.