Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Acoustic-based Approaches for Alzheimer's Disease Detection
Paper and Code
Jun 03, 2021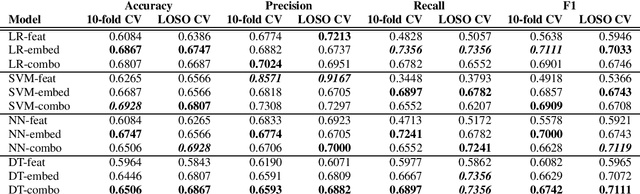
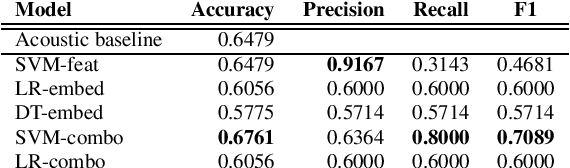

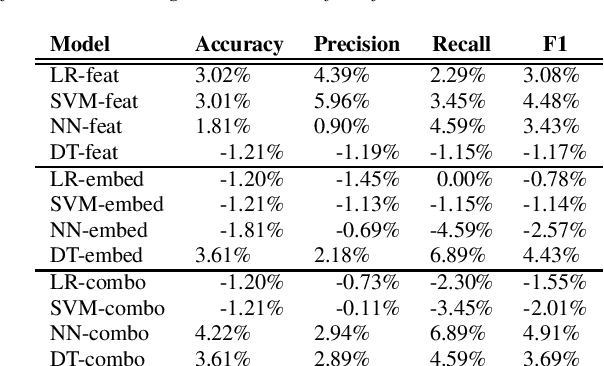
In this paper, we study the performance and generalizability of three approaches for AD detection from speech on the recent ADReSSo challenge dataset: 1) using conventional acoustic features 2) using novel pre-trained acoustic embeddings 3) combining acoustic features and embeddings. We find that while feature-based approaches have a higher precision, classification approaches relying on the combination of embeddings and features prove to have a higher, and more balanced performance across multiple metrics of performance. Our best model, using such a combined approach, outperforms the acoustic baseline in the challenge by 2.8\%.
* Accepted to INTERSPEECH 2021
View paper on